Can SQL Server piece together two different indexes in a single-table query, rather than just giving up and scanning a suboptimal clustered index? The short answer is: yes, in a fairly narrow band of conditions.
Category: By difficulty
Watch out for Merge Interval with date range Index Seeks
In my last post, I found that DATEDIFF, DATEADD and the other date functions in SQL Server are not as datatype agnostic as the documentation would have you believe. Those functions would perform an implicit datatype conversion to either datetimeoffset or datetime (!), which would noticeably affect the CPU time of a query.
Well, today I was building a query on an indexed date range, and the execution plan contained a Merge Interval operator. Turns out, this operator brings a few unexpected surprises to your query performance. The good news is, it’s a relatively simple fix.
DATEDIFF performs implicit conversions
As I was performance tuning a query, I found that a number of date calculation functions in SQL Server appear to be forcing a conversion of their date parameters to a specific datatype, adding computational work to a query that uses them. In programming terms, it seems that these functions do not have “overloads”, i.e. different code paths depending on the incoming datatype.
So let’s take a closer look at how this manifests itself.
Computing the modulus from very large numbers
… and what of this all has to do with IBAN numbers.
The modulus is the remainder of a division of two integers*. Suppose you divide 12 by 4, the result is 3. But divide 11 by 4, and the result is 2.75. This could also be expressed by saying that 11/4 is 2 with a remainder of 3. Computing that 3 is the work of the modulo operator, which in T-SQL is represented by the % operator.
Let’s explore how to compute the modulus of large numbers in SQL Server, and how this is useful in the real world.
T-SQL template parser
Just for the heck of it, I scratched together a template parser for T-SQL ![]() . The usage of this function is similar to the STRING_SPLIT() function, except instead of splitting a string by a delimiter character, we want to split a string according to a defined template.
. The usage of this function is similar to the STRING_SPLIT() function, except instead of splitting a string by a delimiter character, we want to split a string according to a defined template.
SELECT *
FROM dbo.Template_Split(
'Wingtip Toys (Bethel Acres, OK)',
'% (%, %)'
);
… will generate the following output:

Notice how the “%” wildcard character denotes how the string is split. Unlike the fancy stuff you can do with regular expressions, T-SQL wildcards don’t allow you to define capture groups, so this function is unfortunately constrained to just using “%”. I hope it will still come in handy to someone out there.
That’s it, that’s the post. Enjoy!
Turn your list into human-readable intervals
If you’ve worked with reporting, you’ve probably come across the following problem. You have a list of values, say “A, B, C, D, K, L, M, N, R, S, T, U, Z” that you want to display in a more user-friendly, condensed manner, “A-D, K-N, R-U, Z”.
Today, we’re going to look at how you can accomplish this in T-SQL, and what this has to do with window functions and gaps and islands.
Use Ctrl+F1 as a “preview” button in SSMS
Every time I set up SQL Server Management Studio, I take the time to add a shortcut to the “Query Shortcuts” section of the options:
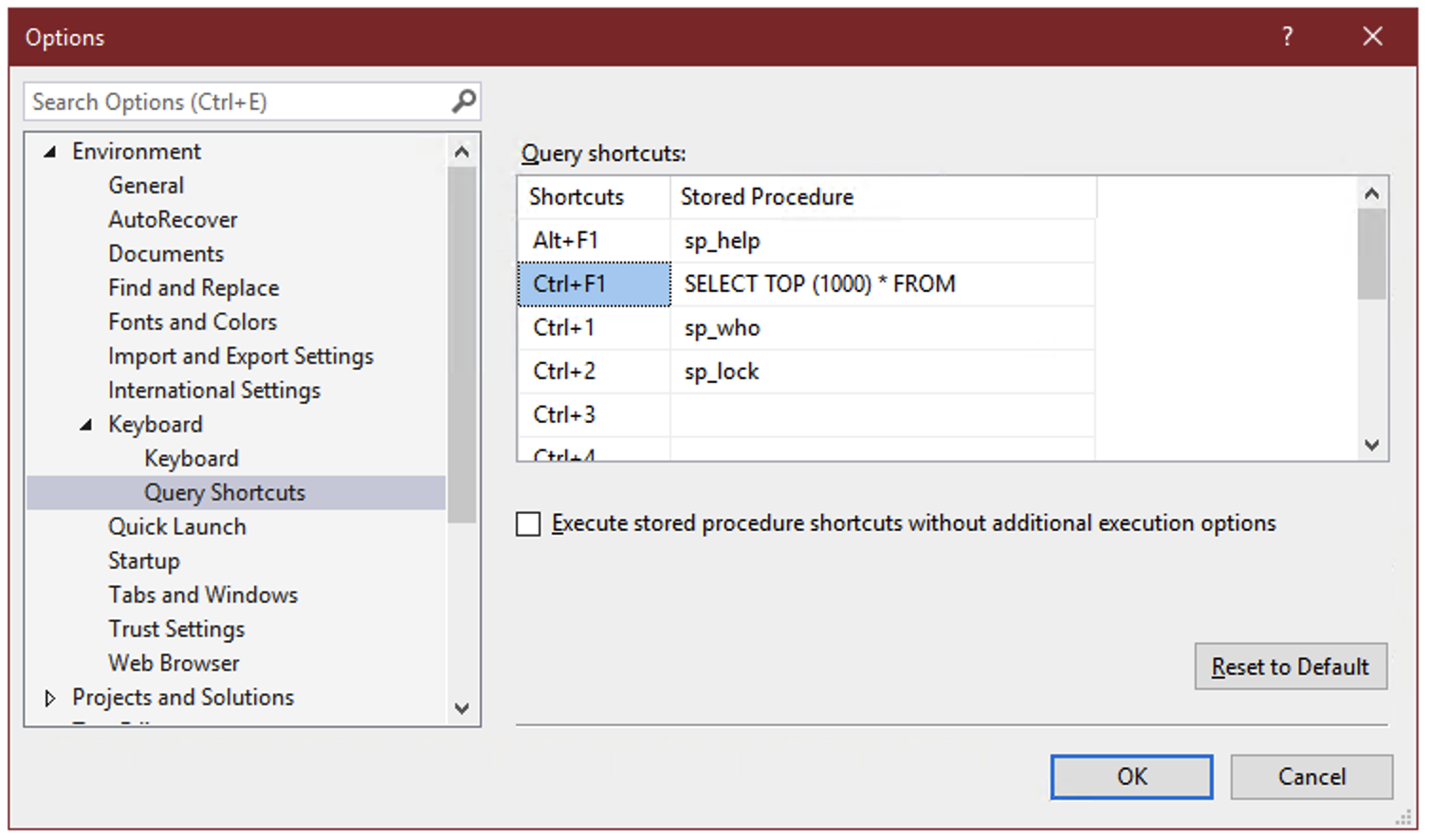
On the surface, these query shortcuts are just what the name implies – a key combination that you can press to run a command or execute a stored procedure. But there’s a hidden super power: whatever text you’ve selected in SSMS when you press the keyboard combination gets appended to the shortcut statement.
So if you select the name of a table, for instance “dbo.Votes”, and press Ctrl+F1, SSMS will run:
SELECT TOP (1000) * FROM dbo.Votes
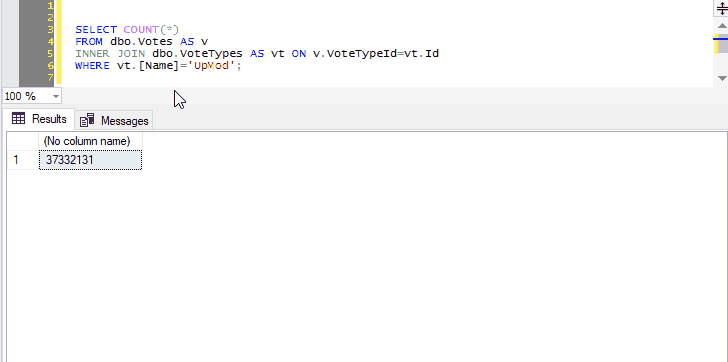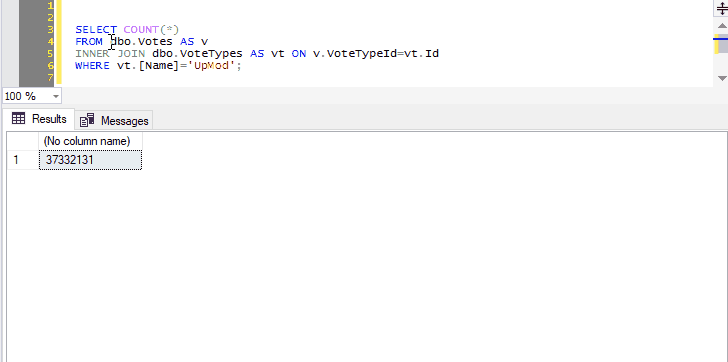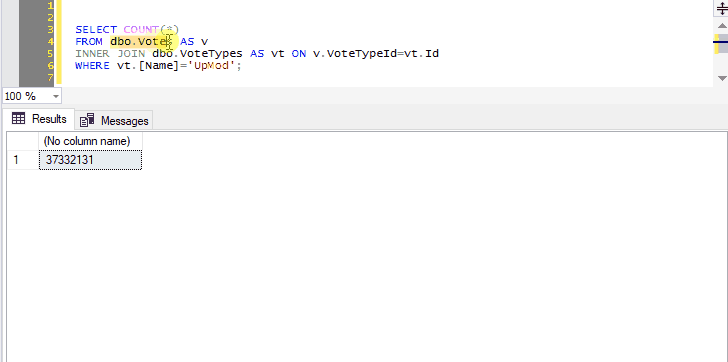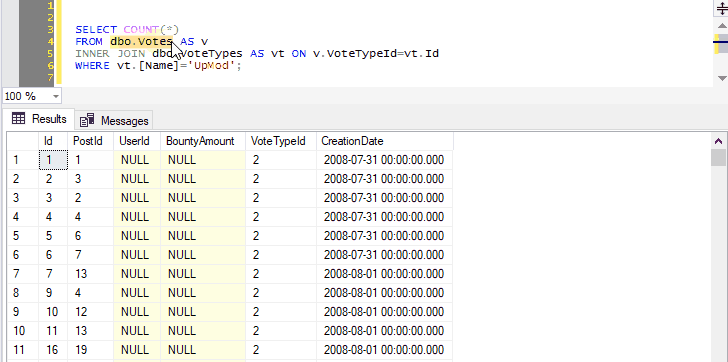
This allows you to create a keyboard shortcut to instantly preview the contents of a table or view.
And you can select not just the name of one table, but any other query text you want to tack on:
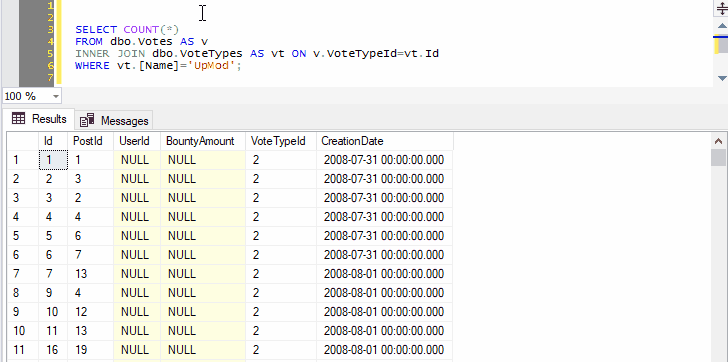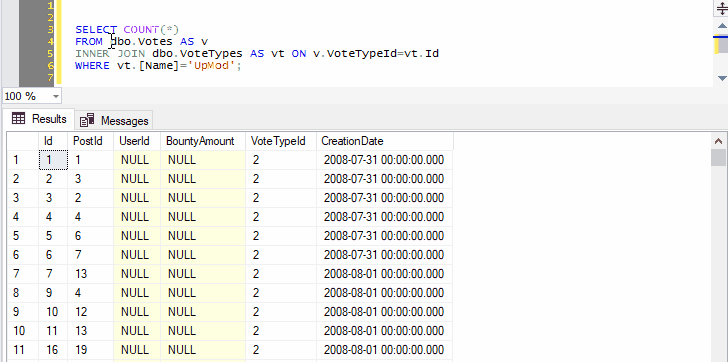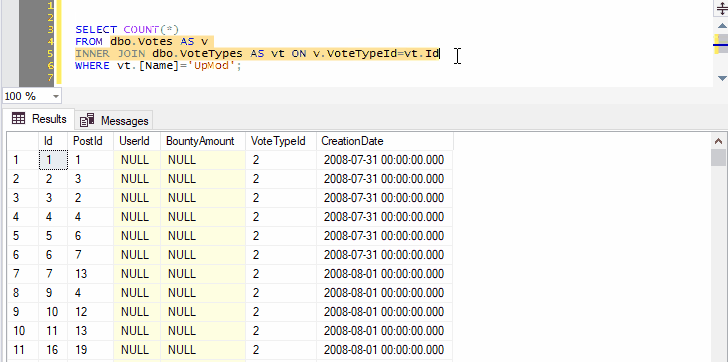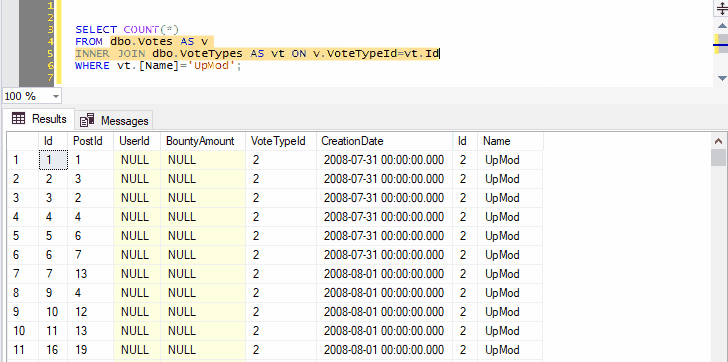
Because we’ve selected both the name of a table and the next line, pressing Ctrl+F1 in SSMS will effectively run the following command:
SELECT TOP (1000) * FROM dbo.Votes AS v INNER JOIN dbo.VoteTypes AS vt ON v.VoteTypeId=vt.Id
You can go on to include as many joins, WHERE clauses, ORDER BY, as long as the syntax makes sense:
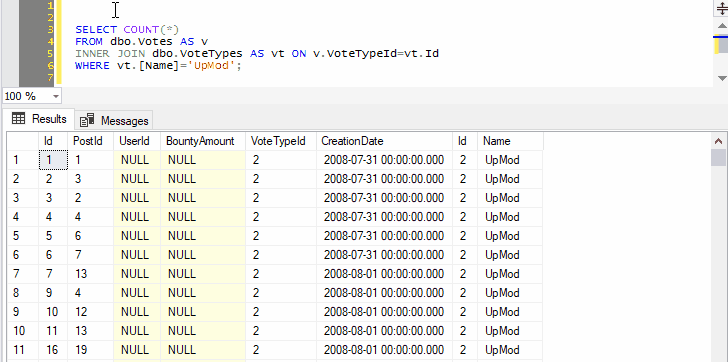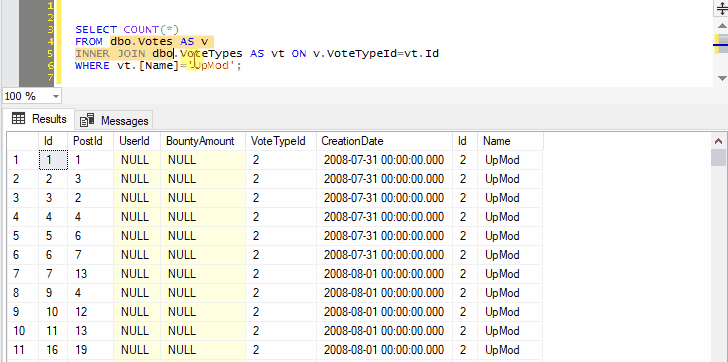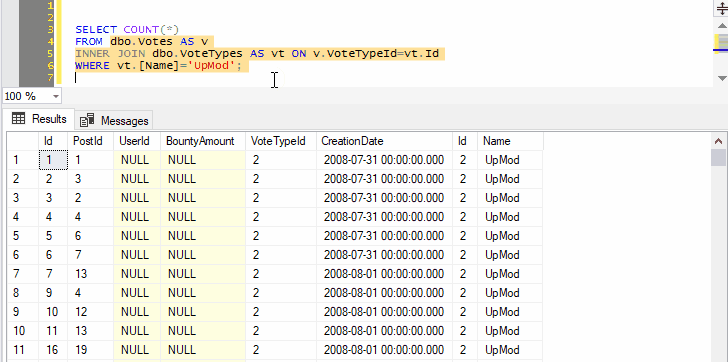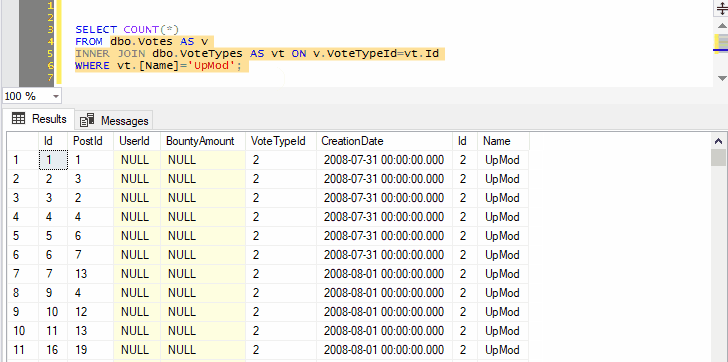
Remember that query shortcuts only apply to new windows, so if you change them, you’ll have to open a new window for the change to take effect.
STRING_SPLIT(), but for quoted names
Can you apply gaps and islands logic on a string? Sure you can.
About wildcards and data type precedence
Implicit conversions in SQL Server follow a specific, predictable order, called data type precedence. This means that if you compare or add/concatenate two values, a and b, with different data types, you can predict which one will be implicitly converted to the data type of the other one in order to be able to complete the operation.
I stumbled on an interesting exception to this rule the other day.
A simple database deploy pipeline using sqlpackage
I did some googling to see just how simple I could make a database deployment pipeline. I keep the DDL scripts in a git repository on the local network, but I can’t use Azure DevOps or any other cloud service, and I don’t have Visual Studio installed, so the traditional database project in SSDT that I know and love is unfortunately not an option for me.
So I googled a little, and here’s what I ended up doing.