In my last post, I found that DATEDIFF, DATEADD and the other date functions in SQL Server are not as datatype agnostic as the documentation would have you believe. Those functions would perform an implicit datatype conversion to either datetimeoffset or datetime (!), which would noticeably affect the CPU time of a query.
Well, today I was building a query on an indexed date range, and the execution plan contained a Merge Interval operator. Turns out, this operator brings a few unexpected surprises to your query performance. The good news is, it’s a relatively simple fix.
I’ve seen this operator a thousand times, and I haven’t really paid much attention to it before:
DECLARE @from datetime2(0)='2020-01-01',
@to datetime2(0)='2023-01-01';
SELECT COUNT(*)
FROM #dates
WHERE [date] BETWEEN @from AND @to;

So what’s going on in this plan, and what exactly does the Merge Interval operator do? Hugo Kornelis goes into great detail on this in his Execution Plan Reference page, but for the purpose of this blog post, let’s just say that Merge Interval helps concatenate the results from two different branches into a “from” and a “to” value, which we can then pass to an Index Seek.
This pseudocode gives you a general idea of what’s going on:
DECLARE @from datetime2(0)='2020-01-01',
@to datetime2(0)='2023-01-01';
SELECT COUNT(*)
FROM #dates
WHERE [date] BETWEEN (SELECT CAST(@from AS date))
AND (SELECT CAST(@to AS date));
Now, to make this work, SQL Server will create a Nested Loops operator, which is technically a “for each” operation – for every row in the top input, the lower branch is executed once. The top input will, by definition, always contain a single row in our type of query.
Eliminating the Merge Interval operator
So can we just have a plan where the Index Seek operator performs a range scan between @from and @to without the whole Merge Interval malarkey?
Yes. The reason for the Merge Interval is that SQL Server needs to perform some kind of work before passing the from/to arguments to the Index Seek. In our plan, this work is represented by the two Compute Scalar operators, right next to the Constant Scan.
The Constant Scan is the parameter (@from and @to). The Compute Scalar appears to convert the @from and @to parameters to a datatype that is compatible with the Index Seek. I say “appears to”, because the execution plan doesn’t really tell us what it does, so this is an educated guess based on a lot of trial-and-error.
The easiest way to eliminate the Merge Interval is to just pass the two range boundaries in the correct datatype from the start:
DECLARE @from datetime2(0)='2020-01-01',
@to datetime2(0)='2023-01-01';
SELECT COUNT(*)
FROM #dates
WHERE [date] BETWEEN CAST(@from AS date) AND CAST(@to AS date);

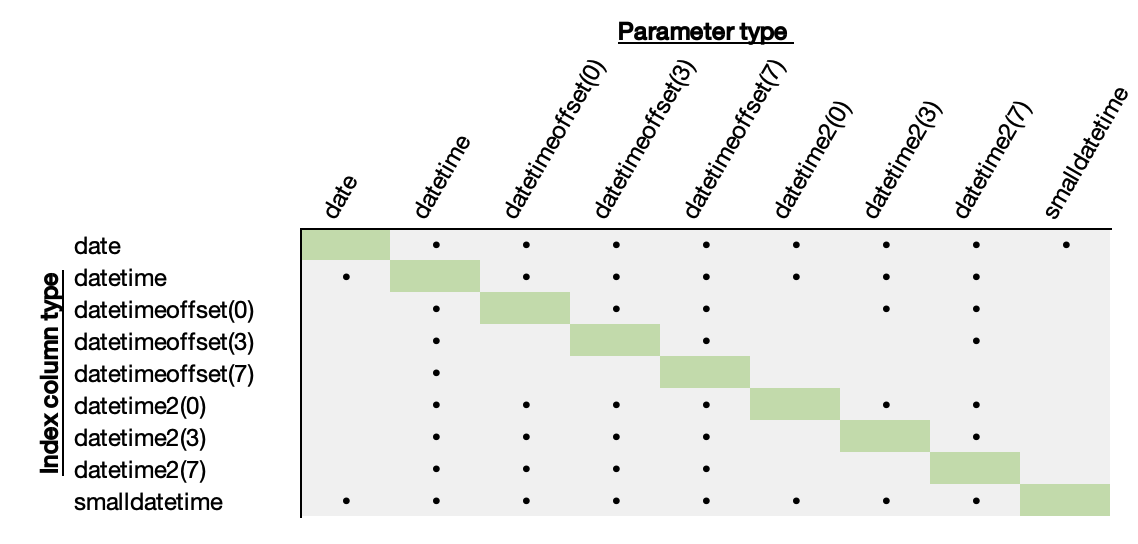
What causes the Merge Interval construct?
This is guesswork, based on my testing.
- Comparing apples-to-apples will always generate a “clean” Seek operation.
- If the parameter is more precise than the column, a conversion will happen.
- This applies even for the same type but different precisions.
- A datetime parameter causes a Merge Interval with anything but a datetime column.
- As with my last post, datetime and smalldatetime are special. But in this case, not in a good way.
Marginal gains?
I know what you’re thinking: of all the marginal gains, the Nested Loops operator runs just once, and all the other operators I’ve removed process just one or two rows.
How many nanoseconds could we possibly save?
Quite a few, actually. Using the same demo table as the previous post, performing a COUNT(*) on about 4 million rows with an Index Seek can vary pretty dramatically. A plain Index Seek query uses on average 15% less CPU time than one using a Merge Interval. My best guess is that the overhead happens in the Nested Loops operator. Simply because it’s another operator that every single row from needs to pass through, even though it doesn’t do much.
In my 81 test cases with different permutations of parameters,
- Merge Interval & Nested Loop averaged a CPU of 510 ms with a median of 515 ms.
- The plain Index Seek averaged a CPU of 447 ms with a median of 438 ms.
The difference between CPU and elapsed are negligible for my test. All queries performed almost the exact same number of logical reads.
Quick unverified thought, I think the reason for the Merge Interval here is similar to the reason why a filter such as LIKE ‘B%’ on an indexed column gets converted to a Seek Predicates of ” >= ‘B’ AND = / = and <=), that need to be converted individually and then combined to a single range.
I don't have time to dive into your analysis now but my guess it is the same principle, but then for various date/time values with different boundaries. The interval generated is sargable and contains (at least) the needed values. Perf differences might be due to slightly more values in the generated interval that are not needed.
Yeah, that’s reasonable. But with a “trivial” case such as this one (where it essentially just handles a datatype conversion of a constant) the Merge Interval feels like overkill. I totally understand its benefits in complex cases, like wildcards, multiple overlapping ranges, etc.
The row count is exactly the same (it effectively returns all rows in the table in this demo), so I’m pretty sure that the overhead of the Nested Loops could explain the added cpu time.
Two thoughts. First (back to the post): Your two queries are not equivalent. A value of e.g. ‘2023-01-01 11:10:10’ is outside the interval of the original query. But the CAST in the second query changes it to ‘2023-01-01’ and it will be included.
On the Merge Interval: For handling variables and converting them to sargable ranges, the optimizer uses fixed patterns. I often see inefficiency. But these are always operators that are very cheap and execute just once or twice or so; they basically do at run-time what the parser does when you supply constant values (or when the variables can be inlined). In this case, BETWEEN is expanded to a >= comparison AND a <= comparison. And that's then two predicates that are handled individually, concatenated, and merged. Standard pattern. No optimization … my guess has always been because of effort vs gain for a part of the plan that takes less than 0.01% of the entire execution in a typical query.
That said, I cannot explain the reason for the differences you measured. With reading 4 million rows I would expect the Merge Interval and the rest of the pattern to be a fraction of a fraction.