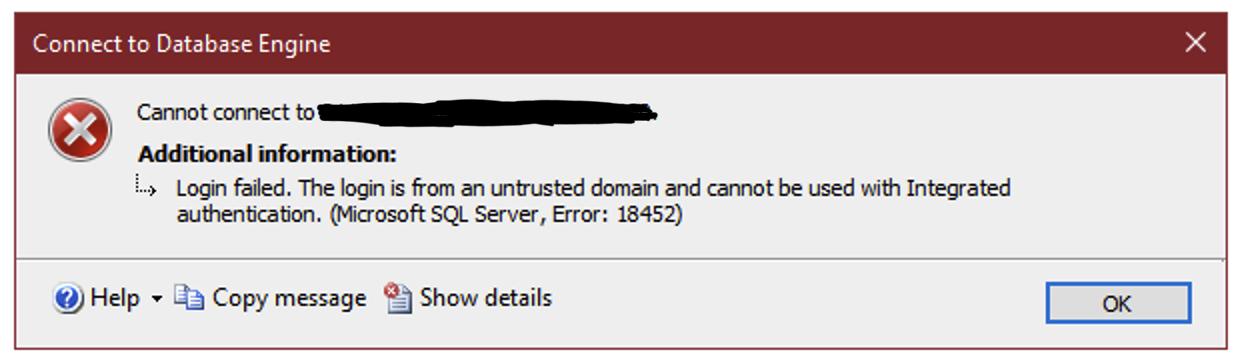
Using a local service account for your SQL Server service, your server won’t automatically have permissions to access to other network resources like UNC paths. Most commonly, this is needed to be able to perform backups directly to a network share.
Using a domain account as your SQL Server service account will allow the server to access a network share on the same domain, but if the network share is not on your domain, like an Azure File Share, you need a different solution.
There’s a relatively easy way to make all of this work, though.