R2 is Cloudflare’s own implementation of AWS S3 storage, with some big benefits – one of them being no egress fees, which is great if you want to publish or distribute a lot of data (like I did with this demo database). In this post, I thought I’d briefly document how to set up R2, and how to use it to back up and restore your SQL Server databases.
Category: Basics
T-SQL math patterns
As part of spending waaaaaay to much time trying to solve the 2023 Advent of Code challenges, I came across multiple instances where I had to dust off some old math that I hadn’t paid attention to since I went to school back in the 90ies.
So for my own convenience, and yours, I’ve built functions for some common math that you might perhaps encounter at some point. I found this whole experience to be a great way to familiarize myself with a lot of the new functionality in SQL Server 2022, including GENERATE_SERIES(), LEAST(), GREATEST() and more. The Github repo contains a SQL Server 2019 version where I’ve built drop-in versions of the 2022 functions, but they probably won’t perform as well as the built-in stuff.
If there are any other functions you’d like to add, feel free to add a comment to this post, or, by all means, a pull request to the repo.
I ❤️ QUOTENAME()
An underrated, and perhaps less well-known T-SQL function is QUOTENAME(). If you haven’t heard of it, chances are that it could do wonders for your dynamic SQL scripts.
To quickly recap quoting, consider the following script:
SELECT N'DROP PROCEDURE '+OBJECT_SCHEMA_NAME([object_id])+N'.'+[name]+N';'
FROM sys.procedures
WHERE [name] LIKE N'%test';
What happens if one of your object names contains a space, a quote, an apostrophe, a square bracket, etc? You’ll end up with a syntax error, or even worse, a SQL injection attack (pretty elaborate, but still quite possible). To solve for this, we quote the object names. In SQL Server, you can surround schema and object names with double quotes (if you’ve set QUOTED_IDENTIFIER) or square brackets.
Simple, right?
SELECT N'DROP PROCEDURE ['+OBJECT_SCHEMA_NAME([object_id])+N'].['+[name]+N'];'
FROM sys.procedures
WHERE [name] LIKE N'%test';
But just adding a [ before and a ] after won’t work if your evil user as embedded square brackets or a semicolon in the object name. What if your object name is “Testing [quoting]; test”?
How to put tempdb on your Azure VM temp disk
Almost all Azure virtual machine sizes come with a temporary disk. The temporary disk is a locally attached SSD drive that comes with a couple of desirable features if you’re installing a SQL Server on your VM:
- Because it is locally attached, it has lower latency than regular disks.
- IO and storage are not billed like regular storage.
As the name implies, the temporary disk is not persistent, meaning that it will be wiped if you shut down your VM or if the VM moves to another VM host (as part of maintenance or troubleshooting). For that reason, we never want to put anything on the temporary disk that we need to keep.
tempdb could be a good fit
Since tempdb is wiped and recreated every time we start a SQL Server instance, it could be a great candidate to have on the temporary drive, provided a few prerequisites are met:
Use Ctrl+F1 as a “preview” button in SSMS
Every time I set up SQL Server Management Studio, I take the time to add a shortcut to the “Query Shortcuts” section of the options:
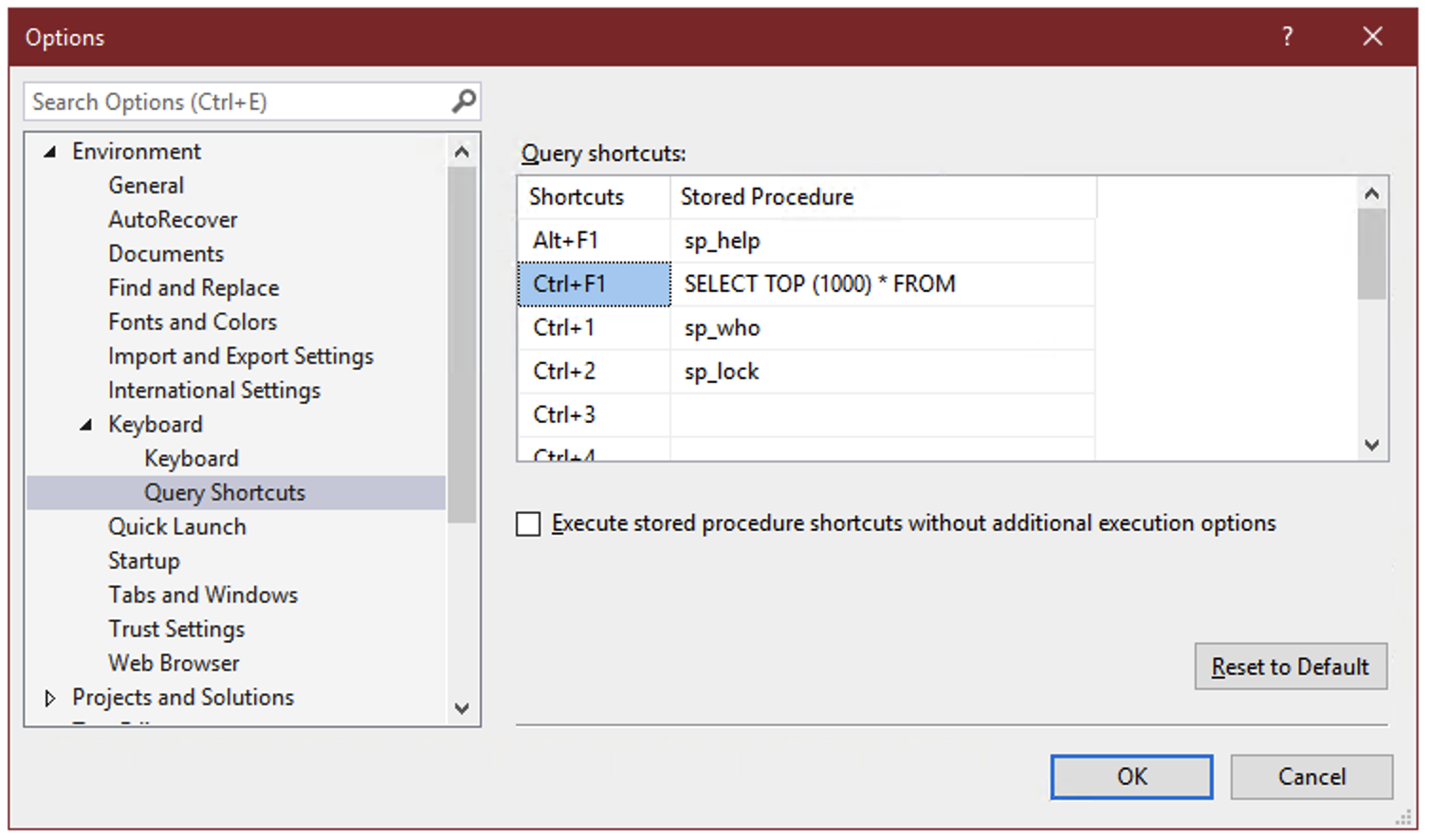
On the surface, these query shortcuts are just what the name implies – a key combination that you can press to run a command or execute a stored procedure. But there’s a hidden super power: whatever text you’ve selected in SSMS when you press the keyboard combination gets appended to the shortcut statement.
So if you select the name of a table, for instance “dbo.Votes”, and press Ctrl+F1, SSMS will run:
SELECT TOP (1000) * FROM dbo.Votes
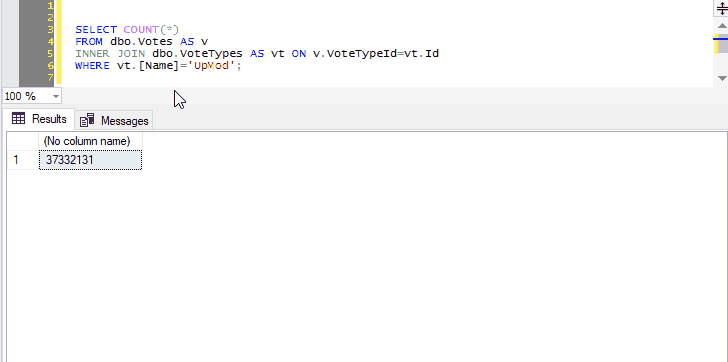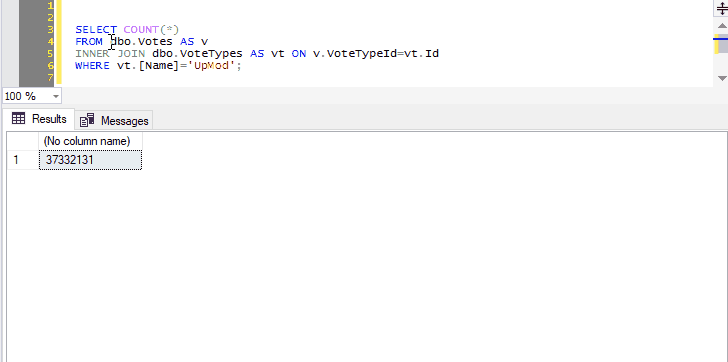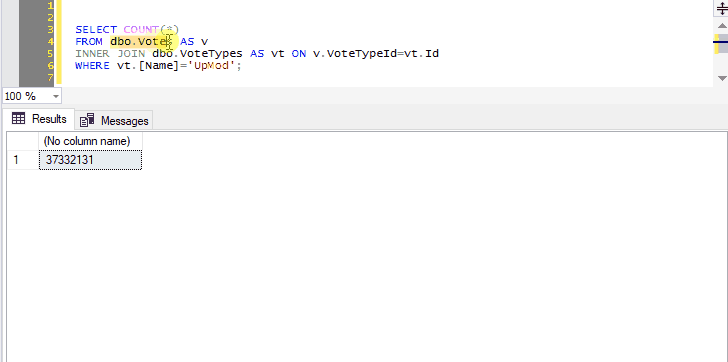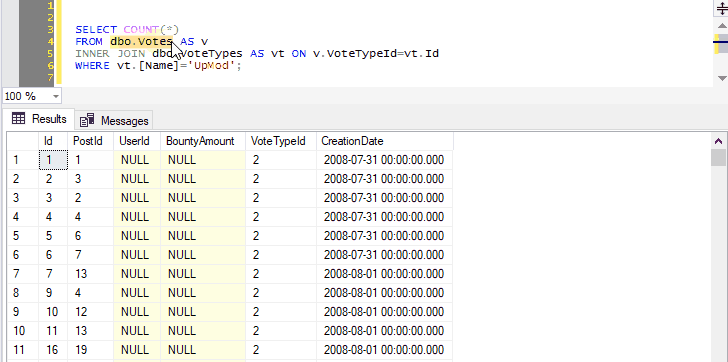
This allows you to create a keyboard shortcut to instantly preview the contents of a table or view.
And you can select not just the name of one table, but any other query text you want to tack on:
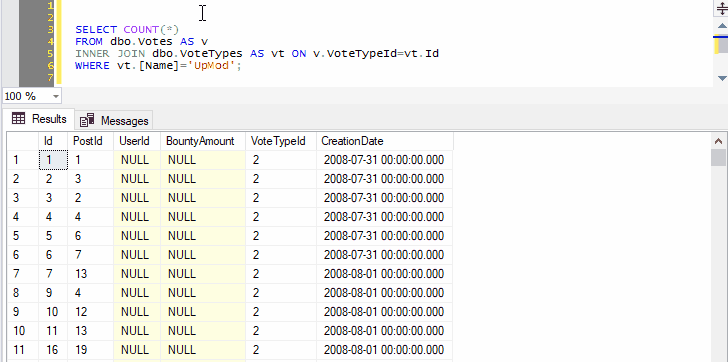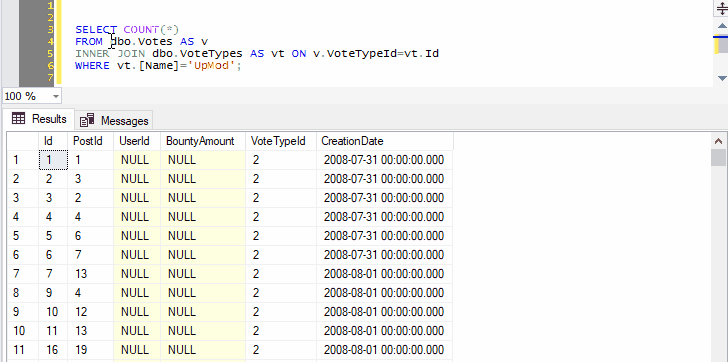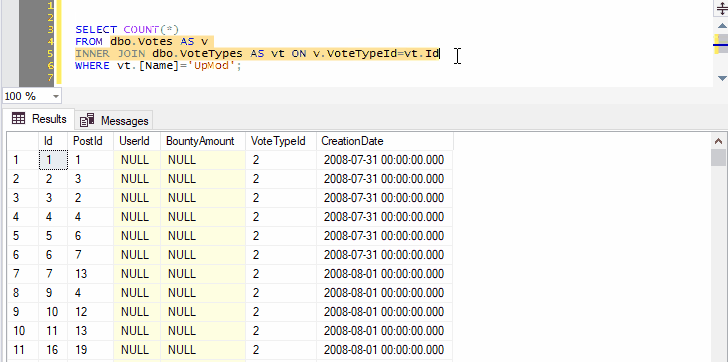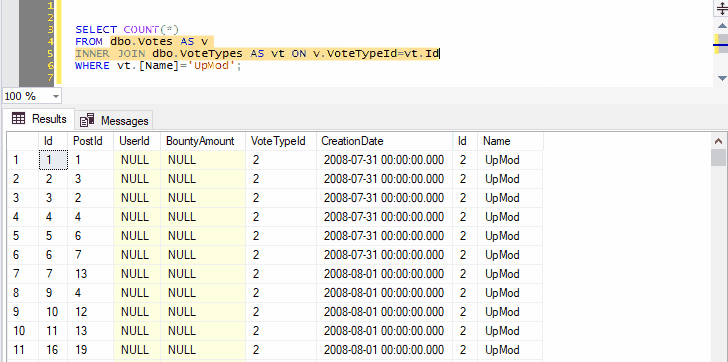
Because we’ve selected both the name of a table and the next line, pressing Ctrl+F1 in SSMS will effectively run the following command:
SELECT TOP (1000) * FROM dbo.Votes AS v INNER JOIN dbo.VoteTypes AS vt ON v.VoteTypeId=vt.Id
You can go on to include as many joins, WHERE clauses, ORDER BY, as long as the syntax makes sense:
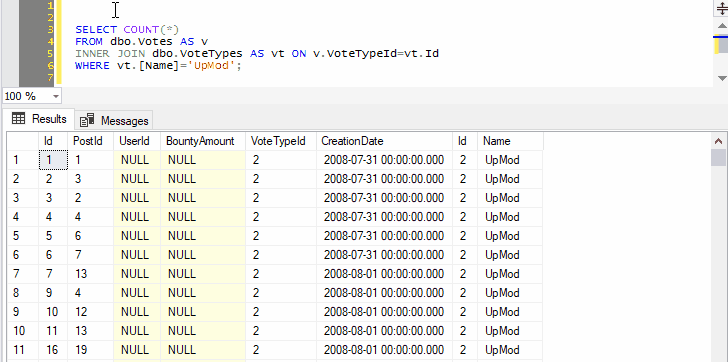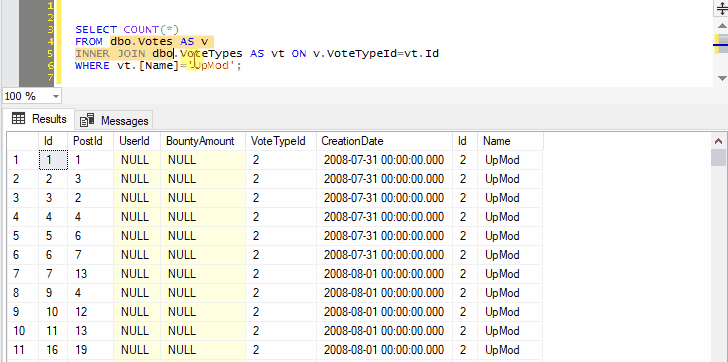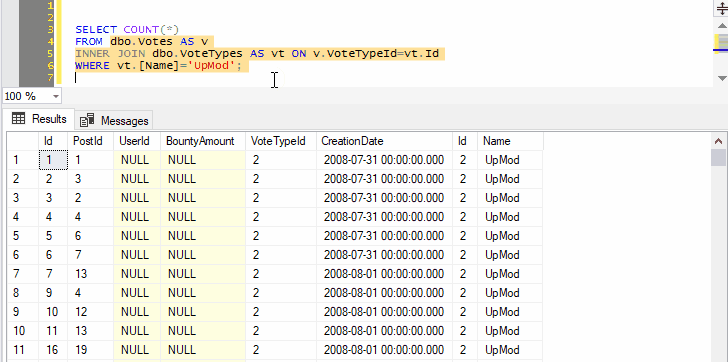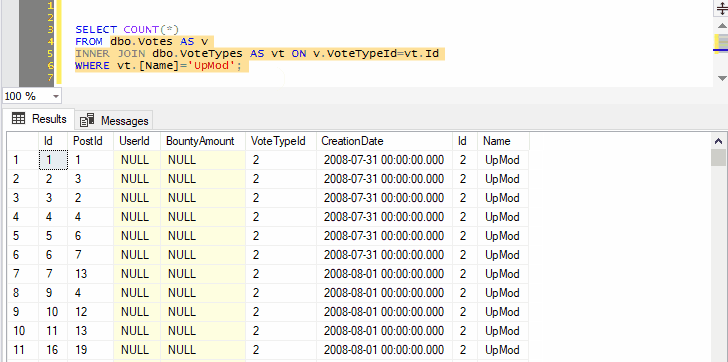
Remember that query shortcuts only apply to new windows, so if you change them, you’ll have to open a new window for the change to take effect.
About wildcards and data type precedence
Implicit conversions in SQL Server follow a specific, predictable order, called data type precedence. This means that if you compare or add/concatenate two values, a and b, with different data types, you can predict which one will be implicitly converted to the data type of the other one in order to be able to complete the operation.
I stumbled on an interesting exception to this rule the other day.
A simple database deploy pipeline using sqlpackage
I did some googling to see just how simple I could make a database deployment pipeline. I keep the DDL scripts in a git repository on the local network, but I can’t use Azure DevOps or any other cloud service, and I don’t have Visual Studio installed, so the traditional database project in SSDT that I know and love is unfortunately not an option for me.
So I googled a little, and here’s what I ended up doing.
Set up access to network shares from SQL Server
Using a local service account for your SQL Server service, your server won’t automatically have permissions to access to other network resources like UNC paths. Most commonly, this is needed to be able to perform backups directly to a network share.
Using a domain account as your SQL Server service account will allow the server to access a network share on the same domain, but if the network share is not on your domain, like an Azure File Share, you need a different solution.
There’s a relatively easy way to make all of this work, though.
Connect using Windows authentication across domains
You’re a consultant or remote worker, and you’re connecting into your work or client network using a VPN. But when you try to connect to the SQL Server, you get this.
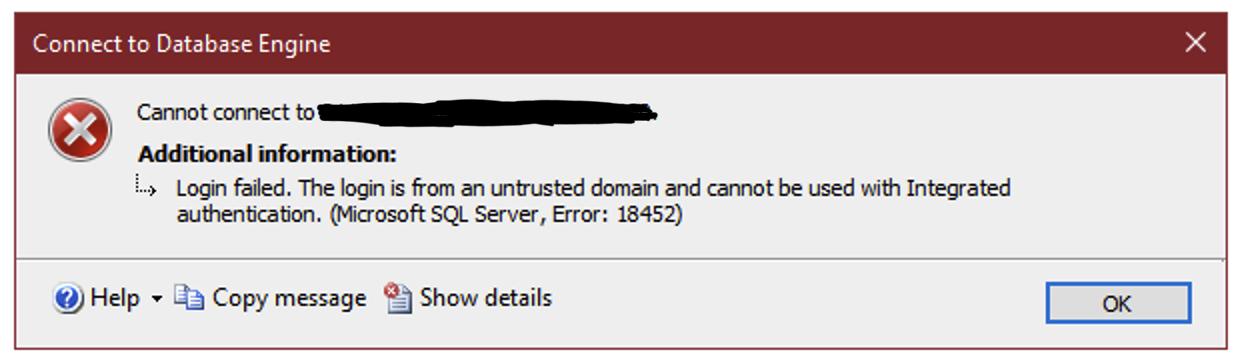
There are a few simple workarounds, each with their own pros and cons.
How to fix rounding errors
A number of business processes require you to distribute a value over a date range. However, if your distribution keys and values don’t add up perfectly or aren’t perfectly divisible, it’s very easy to get rounding errors in your distributions.