Here are 50 random numbers:
--- 50 random numbers
WITH cte AS (
SELECT 0 AS i, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) AS n
UNION ALL
SELECT i+1, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3)
FROM cte WHERE i<50)
SELECT *
FROM cte;
And in SSMS, with the variable-width default font, the output looks… slightly-less-than-readable in the grid view:
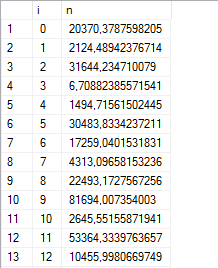
We could use STR() to format the output, but the indent looks a little off:
--- 50 random numbers
WITH cte AS (
SELECT 0 AS i, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) AS n
UNION ALL
SELECT i+1, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3)
FROM cte WHERE i<50)
SELECT *, STR(n, 12, 2) AS with_str
FROM cte;
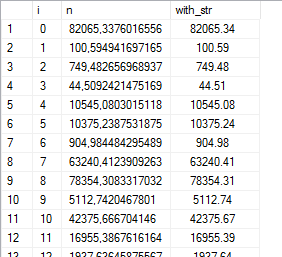
Here’s something I’ve found: the space character is roughly about half the width of a typical number character. So replace every leading space with two spaces, and it will look really neat in the grid:
--- 50 random numbers
WITH cte AS (
SELECT 0 AS i, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) AS n
UNION ALL
SELECT i+1, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3)
FROM cte WHERE i<50)
SELECT *, STR(n, 12, 2) AS with_str,
REPLACE(STR(n, 12, 2), ' ', ' ') AS with_replace
FROM cte;
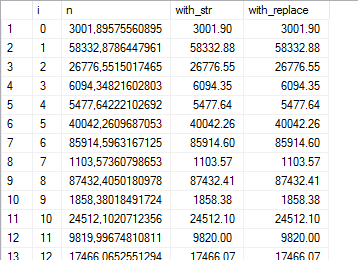
(and terrible everywhere else, obviously.)
