Some database operations can be performed in distinctly different manners, with different impacts on query performance. One important example of such an operation is calculating an aggregate. In this article, we’ll take a look at how aggregates can be “blocking” or “non-blocking”, how it affects memory allocation, and ultimately, what impact this has on your query.
Some example data
To properly illustrate aggregates, we’re going to need some data to work with. Here’s a quick-and-dirty table with 100 000 rows of 100 distinct “accounts” with amounts that we’re going to aggregate.
--- Create the table with a clustered index CREATE TABLE #accountTransactions ( transaction_id int IDENTITY(1, 1) NOT NULL, account int NOT NULL, notes varchar(30) NULL, amount numeric(12, 2) NOT NULL, PRIMARY KEY CLUSTERED (transaction_id) ); --- Add a second, non-clustered index CREATE INDEX accountIndex ON #accountTransactions (account) INCLUDE (amount); --- 100 000 "random" rows SET NOCOUNT ON; DECLARE @i int=0; WHILE (@i<1000000) BEGIN; INSERT INTO #accountTransactions (account, notes, amount) VALUES (@i%1000, 'Random transaction #'+LTRIM(STR(1000+@i/10, 5, 0)), 1000000.0*RAND()-500000.0); SET @i=@i+10; END;
We’re going to be working with a query that calculates the aggregate balance for each account in this table, resulting in 100 rows. This query will look something like this:
SELECT account, SUM(amount) AS balance FROM #accountTransactions GROUP BY account;
How aggregates work
![]() The Hash Match (Aggregate) operator is probably the most common aggregation operator you’ll find in a query plan. For an in-depth discussion on how hash matching works, read my previous HASH JOIN deep-dive post. This operator accepts any data set. It uses a hashing mechanism to partition the workload into so-called “buckets”, and then goes through the data, bucket by bucket, aggregating all of the data by the expressions specified in the GROUP BY clause of your query.
The Hash Match (Aggregate) operator is probably the most common aggregation operator you’ll find in a query plan. For an in-depth discussion on how hash matching works, read my previous HASH JOIN deep-dive post. This operator accepts any data set. It uses a hashing mechanism to partition the workload into so-called “buckets”, and then goes through the data, bucket by bucket, aggregating all of the data by the expressions specified in the GROUP BY clause of your query.
If you look at a random selection of rows from the table, you’ll notice that in order to build an aggregate, SQL Server needs to keep a “working table” in memory. This working table needs to maintain one row for each account. For each row from the source data, that row’s amount is added to the working table’s respective aggregate row.
In practice, this means that SQL Server can’t start returning aggregated rows to the client (or the next step in the query plan) until it has finished aggregating all the rows from the source data, because it won’t know when each aggregate is “complete”. The need to wait for the entire data set to be processed before you can start retrieving the aggregates makes the hash aggregate blocking.
![]()
The Stream Aggregate operator only accepts source data that is already suitably sorted the way it is to be aggregated. Because the data is sorted, SQL Server will only have to maintain a single aggregate row in memory at a time. Once the first aggregate row is complete, it’s passed over to the next step in the query plan and SQL Server can start working on the next aggregate. This makes stream aggregates non-blocking, i.e. you don’t have to wait for the entire aggregation to complete before you can move on.
Here’s an illustration on how the two aggregations work, side-by-side:
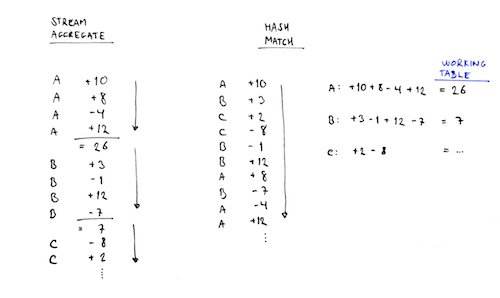
So the hash match is useful where the data isn’t properly sorted but requires a working table in memory and is blocking. The stream aggregate is much more efficient because it hardly uses any memory and it’s non-blocking, but it requires the data to be sorted beforehand.
Example execution plans
With the example data that we created before, here are a few example queries along with how their respective execution plans look.
First off, if we use the clustered index of the example table, the data won’t be ordered by account, which means that SQL Server will apply the Hash Match (Aggregate) operator.
--- Using the clustered index:
SELECT account, SUM(amount) AS balance
FROM #accountTransactions WITH (INDEX=1)
GROUP BY account;
This query uses the clustered index (because I’ve specified an index hint), resulting in a Hash Match (Aggregate).

If we use a the non-clustered index on the table, however, the data in the index is already stored ordered by account. And because we’ve included the amount column in the index, the index is “covering“.
--- Using the non-clustered, covering index:
SELECT account, SUM(amount) AS balance
FROM #accountTransactions WITH (INDEX=accountIndex)
GROUP BY account
ORDER BY account;
Here’s the result: a fast, non-blocking and memory efficient execution plan using Stream Aggregate:

Just for kicks, we can also manually force SQL Server to use Stream Aggregate on the clustered index with the OPTION (ORDER GROUP) hint:
--- Using the clustered index, with a forced sort operation:
SELECT account, SUM(amount) AS balance
FROM #accountTransactions WITH (INDEX=1)
GROUP BY account
ORDER BY account
OPTION (ORDER GROUP);
But in order to use Stream Aggregate, which requires a sorted input, SQL Server needs to sort the output of the clustered index scan before sending it into the Stream Aggregate operator. That’s why you get a rather expensive Sort operator in the execution plan.

On a side note: sort, just like hash match, is a blocking operation that requires working memory, so the whole gain of using a Stream Aggregate is lost because the Sort operator is now applied to the execution plan. Using the forced sort in this case results in a query that is twice as expensive as the original hash match aggregate example that we started off with.
Let me know what you think of this post by leaving comments, questions and requests in the comment section below!
6 comments