Some operations in SQL Server will turn your entire query plan serial (single-threaded), others will just reserve a so-called “serial zone”. I read up on this stuff a number of years ago (including a great post by Paul White), and thinking that some things must have changed since, I decided to go see for myself.
Method
I set up a 16-core Azure VM with 64 GB of memory, and installed Developer Edition of SQL Server 2012, 2014, 2016 and 2017. I also iterated through each service pack respectively – so that’s 12 versions all in all.
For each service pack level, I ran through a script that I’ve created to try to force a parallel plan, given enough data (real, or a billion fake rows) and trace flag 8649.
What I’ve left out
I didn’t bother with in-memory tables, XML, JSON and CLR procedures. If you’ve ever tried to make an XQuery run parallel, you probably already know everything in this post.
Findings
Here’s a list of features/operations that I’ve found will need a serial plan or serial zone. Oh, and, as soon as I had just finished the post, I realized Erik Darling wrote a post on this a few years ago. So. Yeah. 🙂
Modifications to table variables
UPDATE, INSERT and DELETE on table variables cause a completely serial plan. SELECT statements, on the other hand, don’t neccessarily.
Scalar functions
Completely serial. Even when they’re used in computed columns in one of the tables. Even when you’re not referencing that actual column.
Not all computed columns generate serial plans – only those with scalar functions.
Table value functions
Inline table value functions are expanded in your query plan, just like views, and as such, they can run parallel provided there’s nothing else in them that would prevent that from happening.
Multistatement table value functions, on the other hand, modify table variables by definition. Hence, always serial.
Dynamic management views (DMVs)
Serial.
Sort of. I found that sys.dm_os_wait_stats will play along in a parallel query – so there could be other DMVs as well.
Recursive common table expressions
The recursive portion of a recursive CTE will run in a serial zone – however, the output will happily distribute into a parallel zone.
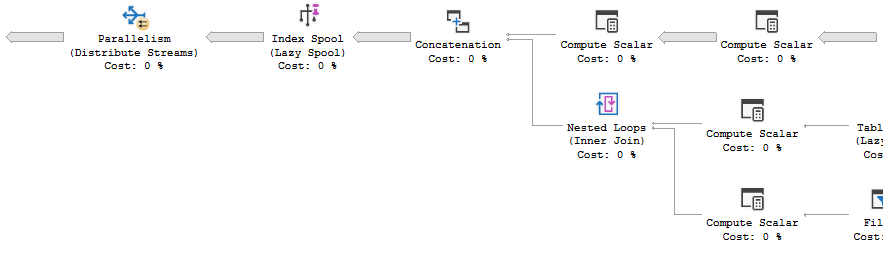
(The recursion happens up to and including Index Spool in the screenshot above.)
TOP (n) and TOP (n) WITH TIES
The Top operator runs in a serial zone of the plan. This makes perfect sense, considering what it does.

Reverse-order scans
If you scan an index in its declared order (forward), the Index Scan/Clustered Index Scan operator can go parallel. However, if the scan starts at the end and moves in reverse-order, it will get a serial zone.
Edit: As of SQL Server 2019, reverse-order scans can run parallel like the regular ones.

So if the index is on (x ASC) and you ORDER BY x DESC, that’s a reverse-order scan, and so is an index on (x DESC) and ORDER BY x ASC.
Sequence Project
Parallel. Although you’ll quite often find Sequence Project in a serial zone at the end of a plan, that’s probably just because you’re using it at the outermost part of your query.
However, there’s nothing to stop Sequence Project from going parallel.

(Try adding something nasty like COUNT(DISTINCT) to the results of a window function to get this kind of plan).
Edit: If your query runs in Batch mode on rowstore (as of SQL Server 2019), you’ll probably see a Window Aggregate-operator instead of Segment/Sequence Project. Window Aggregate loves parallel plans.
Modifications to indexes
So, to my knowledge, index modifications should be able to run in parallel on Enterprise Edition (and thus on Developer Edition), and so I would imagine that modifications such as UPDATE, INSERT and DELETE on an index would go parallel, but this does not appear to be the case.
The actual Index Insert, Index Update and Index Delete operators run in a serial zone.

Please let me know in the comments if you know something I don’t. 🙂
OUTPUT to client
Using OUTPUT to return rows to the client will force a serial plan. On SQL Server 2016+ compatibility, if you run an INSERT INTO … SELECT with parallelism, an OUTPUT … INTO will also be eligible for parallelism under the right circumstances.
INSERTs on heaps
Inserts on heaps can go parallel as of SQL Server 2016, provided that there is no IDENTITY column, and that you’ve specified WITH (TABLOCKX) on the INSERT.

Global aggregates
In parallel queries, you’ll often see “local” and “global” aggregates. Say, you want to calculate the average of a column in a parallel plan: SQL Server will divide the rows between the different worker threads, and each thread will create a local aggregate, say, a COUNT() and a SUM() for each thread. Those threads are then combined into a single thread using Parallelism (Gather Streams), which works a bit like UNION ALL in this context. Finally, there’s a global aggregate, which aggregates the SUM([local sum]) and SUM([local count]), and those are divided with each other to form the AVG().

For obvious reasons, the global aggregate can’t be parallel.
Edit: On SQL Server 2019 and newer, local-global aggregations are typically done in a single, parallel, aggregation if the query runs in Batch mode on rowstore.
Surprises
To my surprise, all versions and service pack levels (from 2012 RTM to 2017 RTM) behaved almost the same with respect to serial operators. The only exception I found was the SELECT INTO. I was expecting some dramatic changes across versions.
Great the article. Thanks
Thanks! Glad you liked it.