We need to talk about the nullable columns in your database. Specifically, because of how NULL values are compared, they can dramatically affect how some lookup operations perform.
NULL values are special. For instance, a comparison between two NULL values, or even a comparison between a NULL value and a non-value, will always be false. This is because NULL values aren’t real values as such, but rather “unknowns”.
-- False:
SELECT '0=NULL',
(CASE WHEN 0=NULL THEN 'True' ELSE 'False' END);
-- False:
SELECT '0!=NULL',
(CASE WHEN 0!=NULL THEN 'True' ELSE 'False' END);
-- Still false:
SELECT 'NULL=NULL',
(CASE WHEN NULL=NULL THEN 'True' ELSE 'False' END);
So it stands to reason that this also applies to IN and NOT IN:
-- False:
SELECT 'NULL IN (0, 1)',
(CASE WHEN NULL IN (0, 1) THEN 'True' ELSE 'False' END);
-- False:
SELECT 'NULL IN (0, 1, NULL)',
(CASE WHEN NULL IN (0, 1, NULL) THEN 'True' ELSE 'False' END);
-- False:
SELECT 'NULL NOT IN (0, 1, NULL)',
(CASE WHEN NULL NOT IN (0, 1, NULL) THEN 'True' ELSE 'False' END);
So far, so good. Now, let’s turn it around and look if we can look for a constant in a dataset that includes a NULL value:
-- True:
SELECT '1 IN (0, 1, NULL)',
(CASE WHEN 1 IN (0, 1, NULL) THEN 'True' ELSE 'False' END);
-- False:
SELECT '1 NOT IN (0, 1, NULL)',
(CASE WHEN 1 NOT IN (0, 1, NULL) THEN 'True' ELSE 'False' END);
-- False:
SELECT '1 NOT IN (2, 3, 4, NULL)',
(CASE WHEN 1 NOT IN (2, 3, 4, NULL) THEN 'True' ELSE 'False' END);
So the first comparison is true, and it’s unaffected by the fact that there’s a NULL value in the list we’re comparing with. 1=1, plain and simple.
The second comparison is false, but not because there’s a 1 in the list, but rather because there’s a NULL. To prove this, look at the third comparison, where there’s no 1, but still a NULL.
The poison NULL
Let’s go bigger. Instead of comparing a fixed set of values, let’s look at a whole table. Here’s a quick setup:
--- Create the outer table, give it some rows:
CREATE TABLE #outer (
i int NOT NULL,
CONSTRAINT PK PRIMARY KEY CLUSTERED (i)
);
INSERT INTO #outer (i) VALUES (1);
WHILE (@@ROWCOUNT<100000)
INSERT INTO #outer (i)
SELECT MAX(i) OVER ()+i
FROM #outer;
--- Create the inner table, fill it with a copy of the outer table,
--- except for 10 random rows:
CREATE TABLE #inner (
i int NULL
);
CREATE UNIQUE CLUSTERED INDEX UCIX ON #inner (i);
INSERT INTO #inner (i)
SELECT i
FROM #outer;
--- Remove 10 random rows, to make things a little more interesting.
DELETE TOP (10) FROM #inner;
Now, let’s look at some simple IN () queries. First up:
SELECT *
FROM #outer
WHERE i IN (SELECT i FROM #inner);
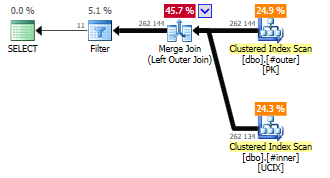
This one equates to a really nice merge join, because the two tables have matching clustered indexes on the join column.
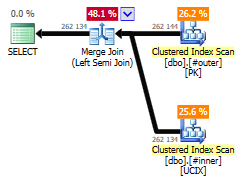
So what happens if we change the IN() to a NOT IN()?
SELECT *
FROM #outer
WHERE i NOT IN (SELECT i FROM #inner);
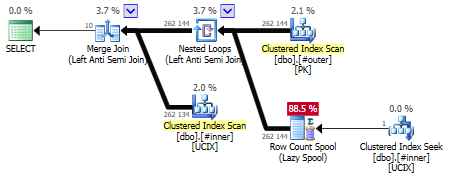
We expected the Semi Join to turn into an Anti Semi Join, but the plan now also contains a Nested Loop branch with a Row Count Spool – what’s that about? Turns out the Row Count Spool, along with its index seek, has to do with the NOT IN() and the fact that we’re looking at a nullable column. Remember that…
x NOT IN (y, z, NULL)
… always returns false, because the NULL value could represent essentially anything, including the x. And so it is with the inner table, if there happens to be a NULL value among those rows.
So the lower-right clustered index seek actually checks if there is a NULL value in the inner table’s join column, and if there is, the entire join subsequent Merge Join between the inner and outer tables will return zero rows.
Simplifying the plan
There are a number of ways we can simplify things.
Skipping the NULLs
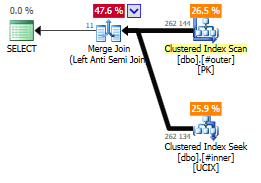
You could change the column to a non-nullable type (so SQL Server won’t have to check for NULL values in the first place), or you could just tell SQL Server to ignore NULL values, by eliminating them with a WHERE clause:
SELECT *
FROM #outer
WHERE i NOT IN (SELECT i FROM #inner
WHERE i IS NOT NULL);
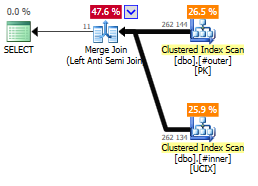
Using NOT EXISTS instead of NOT IN
You could rewrite the query to use a NOT EXISTS construct, which will be optimized to form the exact same Merge Join plan as we saw above.
SELECT *
FROM #outer AS o
WHERE NOT EXISTS (SELECT i FROM #inner AS i
WHERE o.i=i.i);
Left Anti Join
You could write the query with a LEFT JOIN and a WHERE clause, but what it gains in readability, it loses adding an extra Filter operator that could slow the query down just a fraction:
SELECT o.*
FROM #outer AS o
LEFT JOIN #inner AS i ON o.i=i.i
WHERE i.i IS NULL;
Getting fancy with set operators
You could use the EXCEPT set operator. It generates the same query plan in this case, but the downside is that you can only return the key column(s). But instead, EXCEPT does compare NULL values, unlike the equality operator in a regular join.
SELECT i FROM #outer
EXCEPT
SELECT i FROM #inner;
I wrote a post a while ago about using set operators like INTERSECT to compare or join on null values, but Paul White has a really nice post that goes a lot more in depth.
Cool story, bro
“… but who creates nullable columns without actual NULL values?” I hear you say.
I’m glad you asked. There are a number of ways to do this inadvertedly. One is to SELECT … INTO a new temp table. This will inherit the nullability of the source column definition.
Another is by to use CREATE TABLE without specifically saying NOT NULL.
CREATE TABLE #inner (
i int
)
If you don’t specify “NULL” or “NOT NULL” on the column, it always defaults to “NULL”.
Why you should care
The query in this example will really only check the inner table once for NULL values (hence the Spool operator), and for that check, it’ll use an index seek, because the column is indexed. So the performance impact is hardly an issue here.
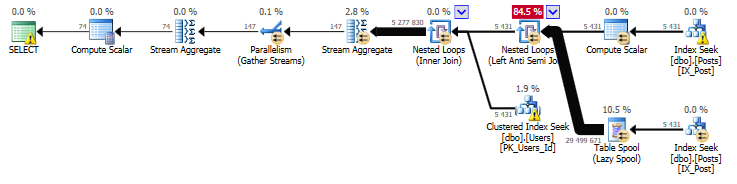
But it gets considerably worse with the following example that uses the Stack Overflow database, where none of those two things are true:
SELECT u.Id AS UserId,
u.DisplayName,
COUNT(*) AS UnansweredWithin24Hours
FROM dbo.Users AS u
INNER JOIN dbo.Posts AS p ON
u.Id=p.OwnerUserId AND
p.PostTypeId=1
WHERE p.Id NOT IN (SELECT ParentId
FROM dbo.Posts
WHERE PostTypeId=2
AND CreationDate<=DATEADD(hour, 24, p.CreationDate))
GROUP BY u.Id, u.DisplayName
The ParentId column in dbo.Posts is nullable and not indexed, so the resulting query plan ends up running a Nested Loop over each row in dbo.Posts for each row in “p”. By fixing the null problem that we’ve looked at in this post, the query goes from running for hours and hours down to just a few seconds.
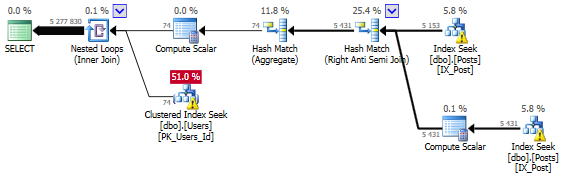
Just adding “AND ParentId IS NOT NULL” to the NOT IN() subquery gets us:
I’m using this Stack Overflow example in my GroupBy presentation “Not just polish” from September 2018, if you want to see it in a demo. The magic starts at 39:07.
Or try this ? /Stephen
— Alter DB Setting
ALTER DATABASE Test SET ANSI_NULL_DEFAULT OFF;
GO
— and alter connection level setting
SET ANSI_DEFAULTS OFF;
— Create table t1.
CREATE TABLE t1 (a TINYINT) ;
GO
— NULL INSERT should fail.
INSERT INTO t1 (a) VALUES (NULL);
Msg 515, Level 16, State 2, Line 14
Cannot insert the value NULL into column ‘a’, table ‘master.dbo.t1’; column does not allow nulls. INSERT fails.
This is a great point!
If you like it it might be a good thing to set on your MODEL db !!!
Kind of frustrating that you seem to need to set it on the connection too – but that is maybe part of the DEVOPS build process
— False:
SELECT ‘NULL IN (0, 1, NULL)’,
(CASE WHEN NULL IN (0, 1, NULL) THEN ‘True’ ELSE ‘False’ END);
— False:
SELECT ‘NULL IN (0, 1, NULL)’,
(CASE WHEN NULL IN (0, 1, NULL) THEN ‘True’ ELSE ‘False’ END);
— False:
SELECT ‘NULL NOT IN (0, 1, NULL)’,
(CASE WHEN NULL NOT IN (0, 1, NULL) THEN ‘True’ ELSE ‘False’ END);
Good catch. Thanks!