Whenever SQL Server needs to sort a data stream, it will use the Sort operator to reorder the rows of the stream. Sorting data is an expensive operation because it entails loading part or all of the data into memory and shifting that data back and forth a couple of times. The only time SQL Server doesn’t sort the data is when it already knows the data to be ordered correctly, like when it has already passed a Sort operator or it’s reading from an appropriately sorted index.
But what happens if the data is ordered correctly, but SQL Server doesn’t know about it? Let’s find out.
I’ve seen this accidental pattern more times than I care to remember, and it still bothers me no end. There’s a valuable lesson to be had at the end, though.
A number of business processes require you to distribute a value over a date range. However, if your distribution keys and values don’t add up perfectly or aren’t perfectly divisible, it’s very easy to get rounding errors in your distributions.
Watching Brent Ozar’s 2017 PASS Summit session on Youtube the other day, I learned that the Top N Sort operation in SQL Server behaves dramatically differently, depending on how many rows you want from the TOP.
You may already know that common table expressions, like views, don’t behave like regular tables. They’re a way to make your query more readable by allowing you to write a complex SQL expression just once, rather than repeating it all over your statement or view. This makes reading, understanding and future refactoring of your code a little less painful.
But they’re no magic bullet, and you may end up with some unexpected execution plans.
I recently worked with a large set of accounting transactions. I needed to split those rows into multiple logical batches, but each batch had to be logically consistent – among other things, those batches had to be properly balanced, because accounting people are kind of fussy like that.
So I designed a little T-SQL logic that would split all of those transactions into evenly sized batches, without violating their logical groupings.
There’s more to the VALUES clause in T-SQL than meets the eye. We’ve all used the most basic INSERT syntax:
INSERT INTO #work (a, b, c)
VALUES (10, 20, 30);
But did you know that you can create multiple rows using that same VALUES clause, separated by commas?
INSERT INTO #work (a, b, c)
VALUES (10, 20, 30),
(11, 21, 31),
(12, 22, 32);
Note the commas at the end of each line, denoting that a new row begins here. Because this runs as a single statement, the INSERT runs as an atomic operation, meaning that all rows are inserted, or none at all (like if there’s a syntax issue or a constraint violation).
I use this construct all the time to generate scripts to import data from various external sources, like Excel, or even a result set in Management Studio or Azure Data Studio.
Here’s something you can try:
Select a dataset from SSMS or Excel, copy it to the clipboard, and paste it into a new SSMS window.
Select just one of the tabs, then use the “find and replace” feature (Ctrl+H) in SSMS to replace all tabs with the text ', ' (including the apostrophes).
Now, add the text (' at the beginning of each line and '), at the end of each line. The last line obviously won’t need the trailing comma. If you’re handy with SSMS, you can do at least the leading values with a “box select”: holding down the Alt key as you make a zero-width selection over all the rows, then typing the text.
If all of this sounds like a lot of work for you, you might want to try out a little web hack that I wrote. It allows you to paste a tab-delimited dataset, just like the ones you get from Excel or the result pane in SSMS or ADS, into a window and instantly convert it into a T-SQL INSERT statement with the click of a button.
Pro tip: in SQL Server Management Studio, use Ctrl+Shift+C to copy not only the results, but also the column names!
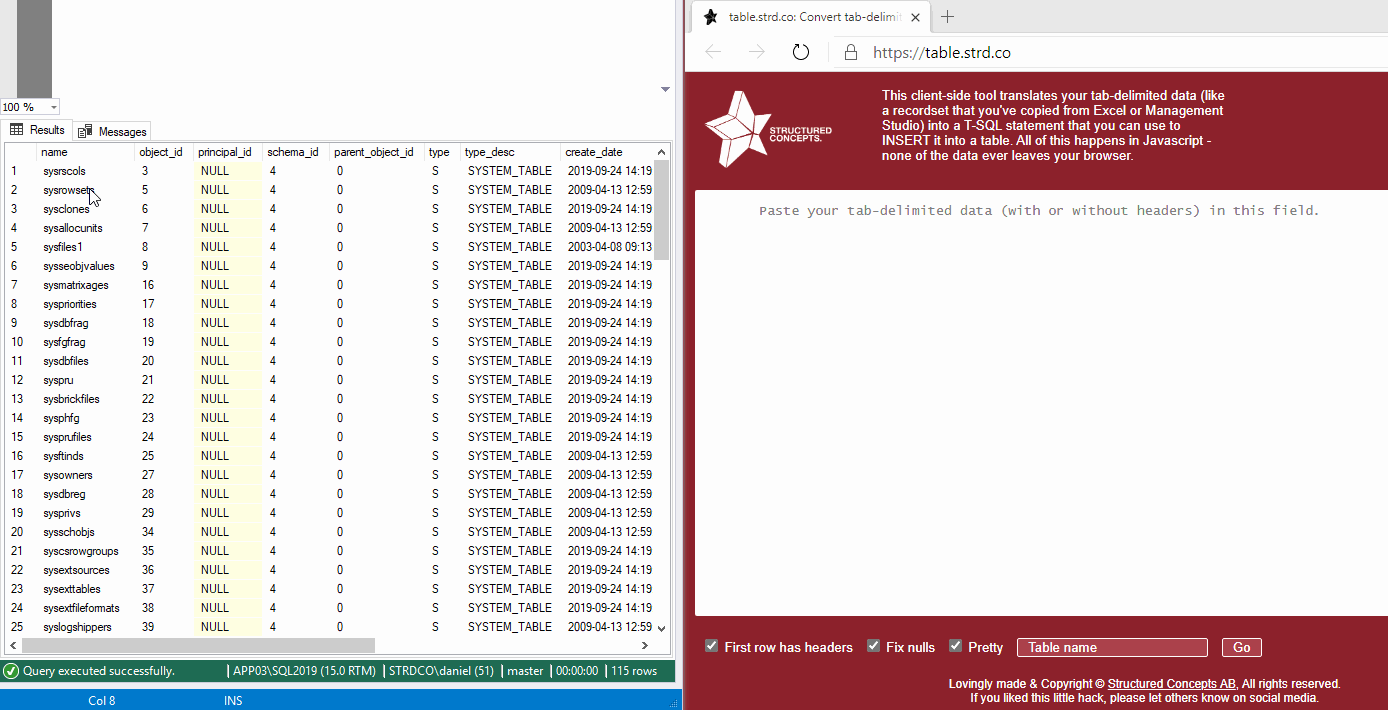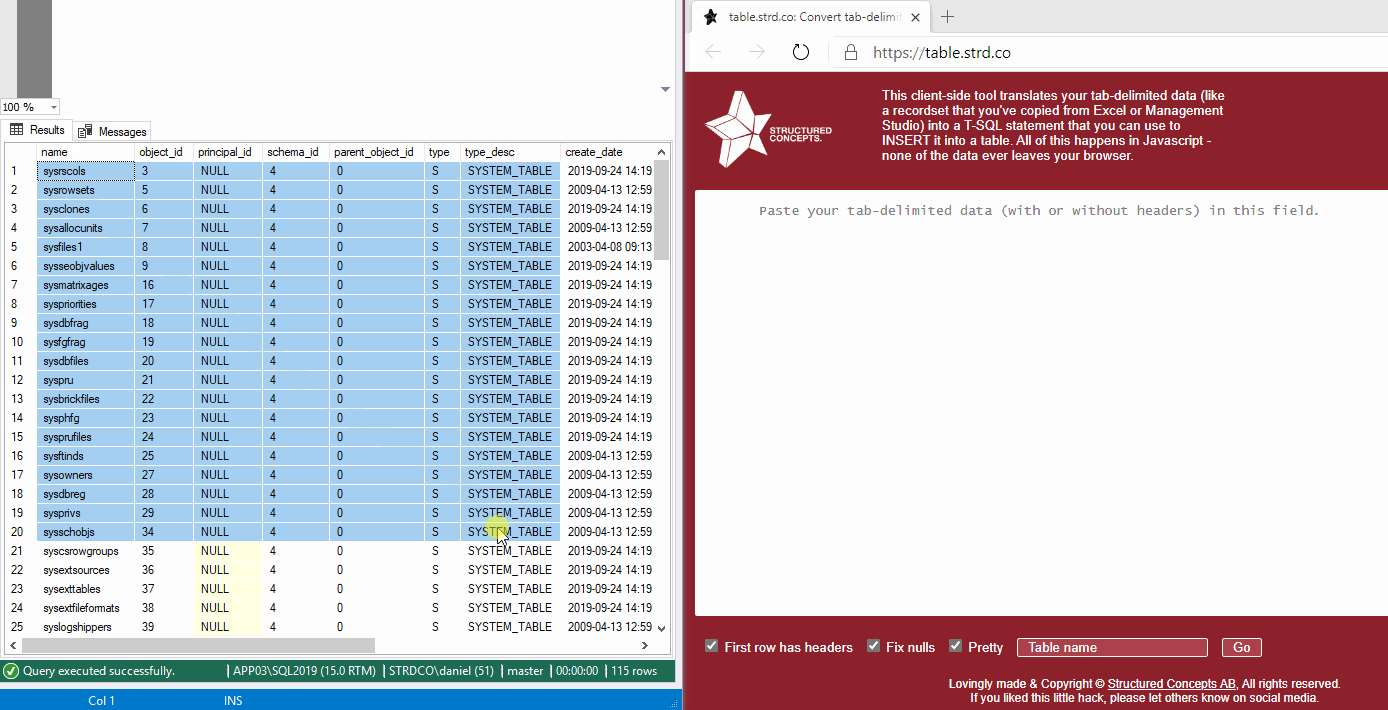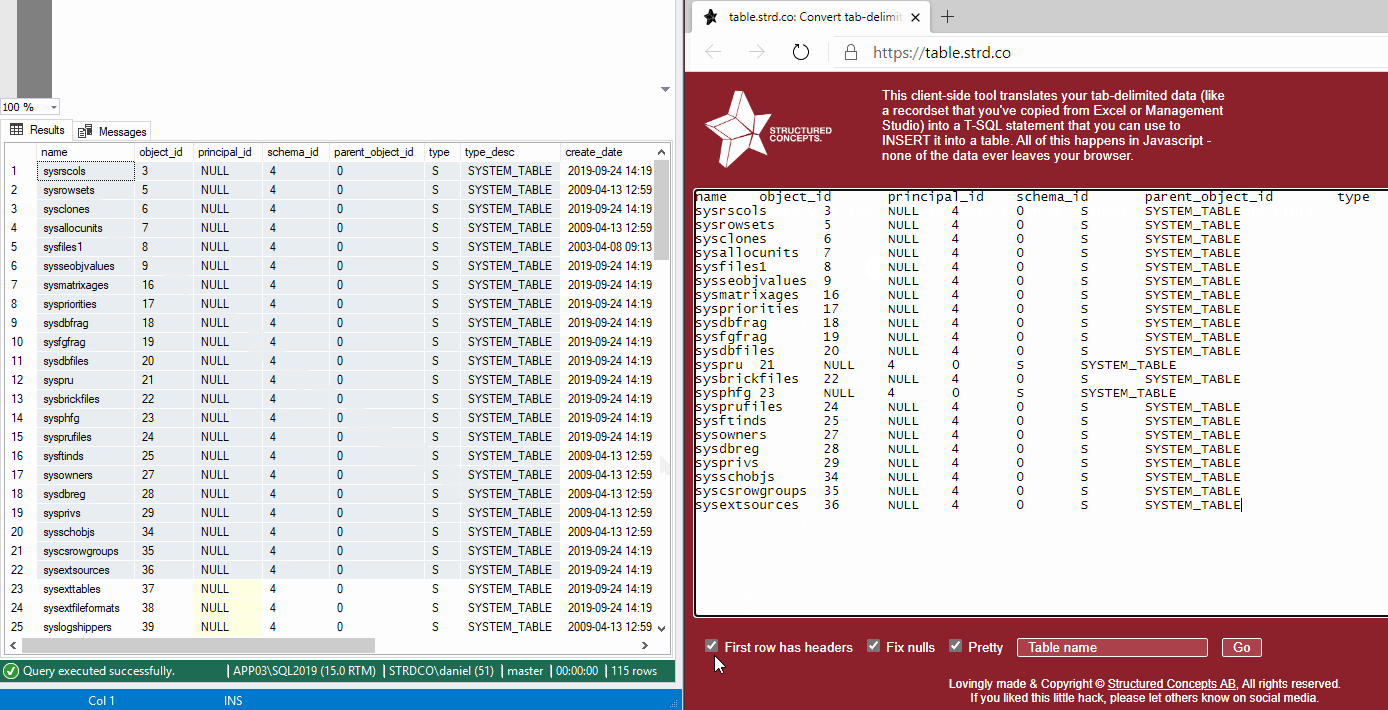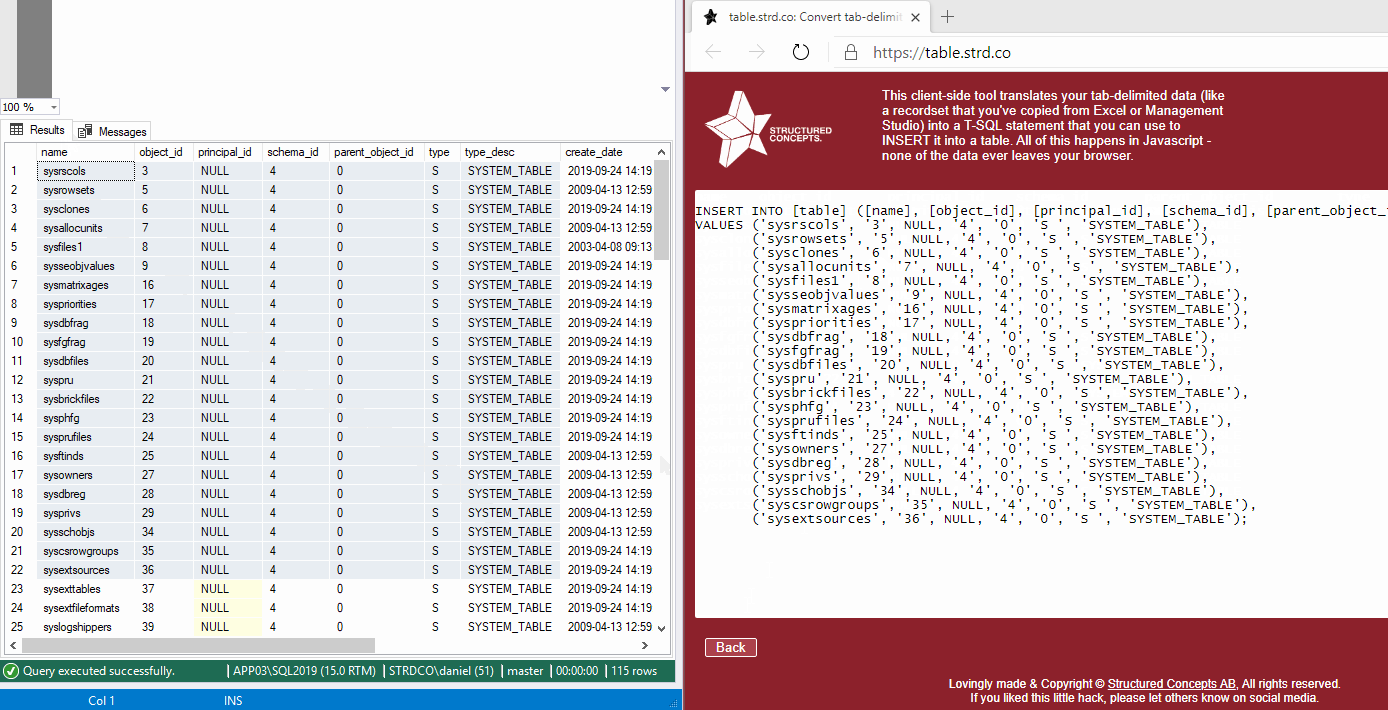
Options
First row has headers: instead of inserting the first row of the raw data, the script uses it to map the INSERTed values to the correct columns in the destination table.
Fix nulls: Particularly when exporting from SSMS, we’ll lose information about which values are actually NULL and which ones are actually the text “NULL”. When this option is unchecked, the values will be treated as the text “NULL”, when checked, all values that consist entirely of the text “NULL” will have the surrounding apostrophes removed, so they become actual NULL values.
Pretty: adds some indenting spaces to the output code. This increases the script size by a few bytes, but increases readability.
Table name: Option table name to put in the INSERT INTO header of the script.
And to make sure you sleep well at night, the entire process on table.strd.co happens in the browser – nothing is ever uploaded to the Internet.
Here’s a quick tip that touches on one of the powerful SSMS tricks in my “Management Studio Level-Up” presentation. Say you have a potentially large number of database objects (procedures, functions, views, what have you), and you need to make a search-and-replace kind of change to all of those objects.
You could, of course, put the database in source control and use a proper IDE to replace everything, then check your code back into source control and commit it to the database. That’s obviously the grown-up solution. Thanks for reading this post.
But let’s say for the sake of argument that you haven’t put your database in version control. What’s the lazy option here?
Metadata changes, like modifying a clustered index, or many types of column changes, will create locks in SQL Server that will block users from working with that table until the change is completed. In many cases, those locks will extend to the system objects, so you won’t even be able to expand the “Tables” or “Views” nodes in Management Studio.
I want to show you how you can perform those changes using a copy of the table, then instantly switching the table with the copy. The secret is partition switching, and contrary to popular belief, you won’t need Enterprise Edition, or even partitions, to do it.