I’ve seen this accidental pattern more times than I care to remember, and it still bothers me no end. There’s a valuable lesson to be had at the end, though.
Some demo data
Suppose you have two tables; one table with accounts and a related property table called “account flags”. The “accounts” table contains one row for each account, along with its balance:
CREATE TABLE #accounts (
account varchar(10) NOT NULL,
balance numeric(12, 2) NOT NULL,
PRIMARY KEY CLUSTERED (account)
);
INSERT INTO #accounts
VALUES ('1001', 1001.00),
('1002', 1002.00),
('1003', 1003.00),
('1004', 1004.00),
('1005', 1005.00);
The “account flags” table can contain one or more flags for each account. Let’s imagine that those flags indicate different types of status codes or something.
CREATE TABLE #accountFlags (
acct varchar(10) NOT NULL,
flag tinyint NOT NULL,
PRIMARY KEY CLUSTERED (acct, flag)
);
INSERT INTO #accountFlags
VALUES ('1001', 10),
('1001', 30),
('1003', 30);
Code review
The developer wrote this pretty little query to show us which accounts are up for review (which in our case means they have a “30” flag).
SELECT account, balance, 'For review' AS [status]
FROM #accounts
WHERE account IN (SELECT account FROM #accountFlags WHERE flag=30)
ORDER BY account;
Did you spot it?
Here’s another hint. The query returns all five accounts in the “accounts” table, even though we can see in the “account flags” table that only two of them have the “30” flag:
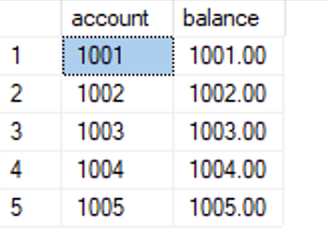
Let’s focus on that subquery:
SELECT account FROM #accountFlags WHERE flag=30;

This table right here, officer
The problem becomes apparent when we think of our query as a traditional multi-table join and explicitly declare the table aliases on all columns:
SELECT a.account, a.balance, 'For review' AS [status]
FROM #accounts AS a
WHERE a.account IN (SELECT f.account FROM #accountFlags AS f WHERE f.flag=30)
ORDER BY a.account;
After this change, our query now gives us the “invalid column name” error, because there’s no “account” column in the #accountFlags. Our clever developer, in a departure from database best practices, decided to name the account column “acct” in the flag table.
Update the query accordingly, and it works:
SELECT a.account, a.balance, 'For review' AS [status]
FROM #accounts AS a
WHERE a.account IN (SELECT f.acct FROM #accountFlags AS f WHERE f.flag=30)
ORDER BY a.account;
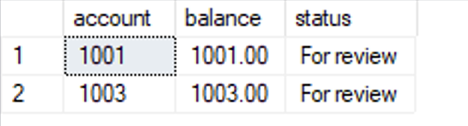
So why did it work in the first place?
In a query with multiple tables, when we don’t explicitly qualify our column names with a table name or table alias, the query compiler will look up if there’s a table that has a that column. In this case, the “account flags” table didn’t, so it proceeded to check the second-best, and voilà, the “accounts” table did.
So SQL Server interpreted the query like this:
SELECT a.account, a.balance, 'For review' AS [status]
FROM #accounts AS a
WHERE a.account IN (SELECT a.account FROM #accountFlags AS f WHERE f.flag=30)
ORDER BY a.account;
… which is really equivalent to:
SELECT a.account, a.balance, 'For review' AS [status]
FROM #accounts AS a
WHERE EXISTS (SELECT 1 FROM #accountFlags AS f WHERE f.flag=30)
ORDER BY a.account;
The moral of the story is
Whenever you’re working with multiple tables in a join (explicit or, like this one, implicit), always specify which table each column comes from. Even if your code works just fine today, just adding an unfortunately named column many years later can break your code.
Just think, in the example above, adding an “account” column to the “account flags” table will make this query suddenly produce dramatically different results.
Granted – in this example, the results would suddenly become correct.
Good article.
Two points. This is exactly why I prefer to do this with a join.
Using ordinal references is a good way to get burned.
Thanks! have a great day.
Richard