Watching Brent Ozar’s 2017 PASS Summit session on Youtube the other day, I learned that the Top N Sort operation in SQL Server behaves dramatically differently, depending on how many rows you want from the TOP.
Consider the following example query in the Stack Overflow database:
SELECT TOP (250) Id, DisplayName, DownVotes
FROM dbo.Users
ORDER BY DownVotes DESC;
SQL Server will scan all of the rows from the Users table (because there’s no index on the DownVotes column), then sort those rows to get only the unfortunate top 250 users with the most downvotes.
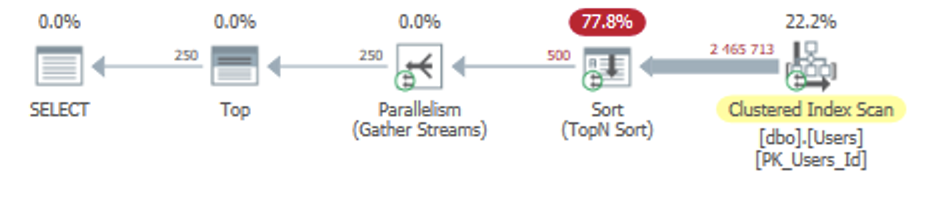
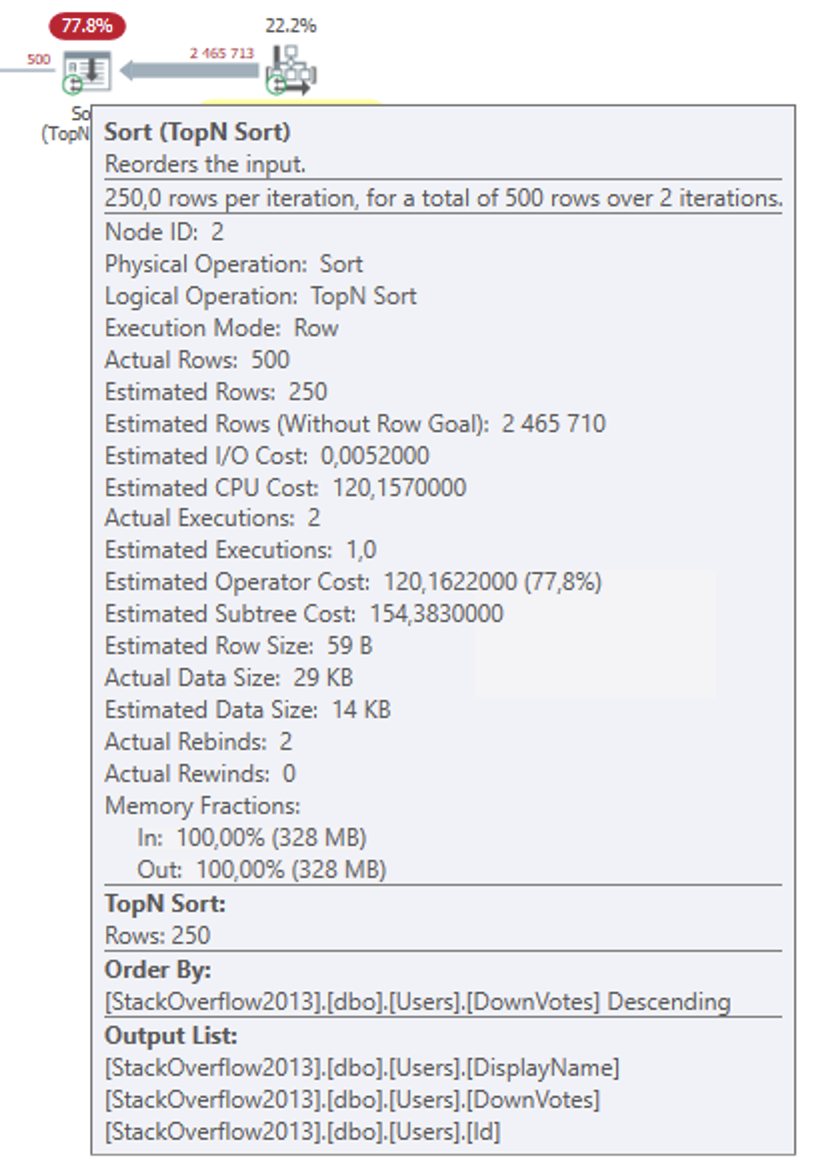
Sorting all of those rows is pretty expensive because it’s a large table:
But there’s a built-in (undocumented) shortcut optimization in SQL Server. If you’re returning no more than 100 rows, the internal behaviour of the Top N Sort operator changes.
SELECT TOP (100) Id, DisplayName, DownVotes
FROM dbo.Users
ORDER BY DownVotes DESC;
Look what happened to the memory grant:
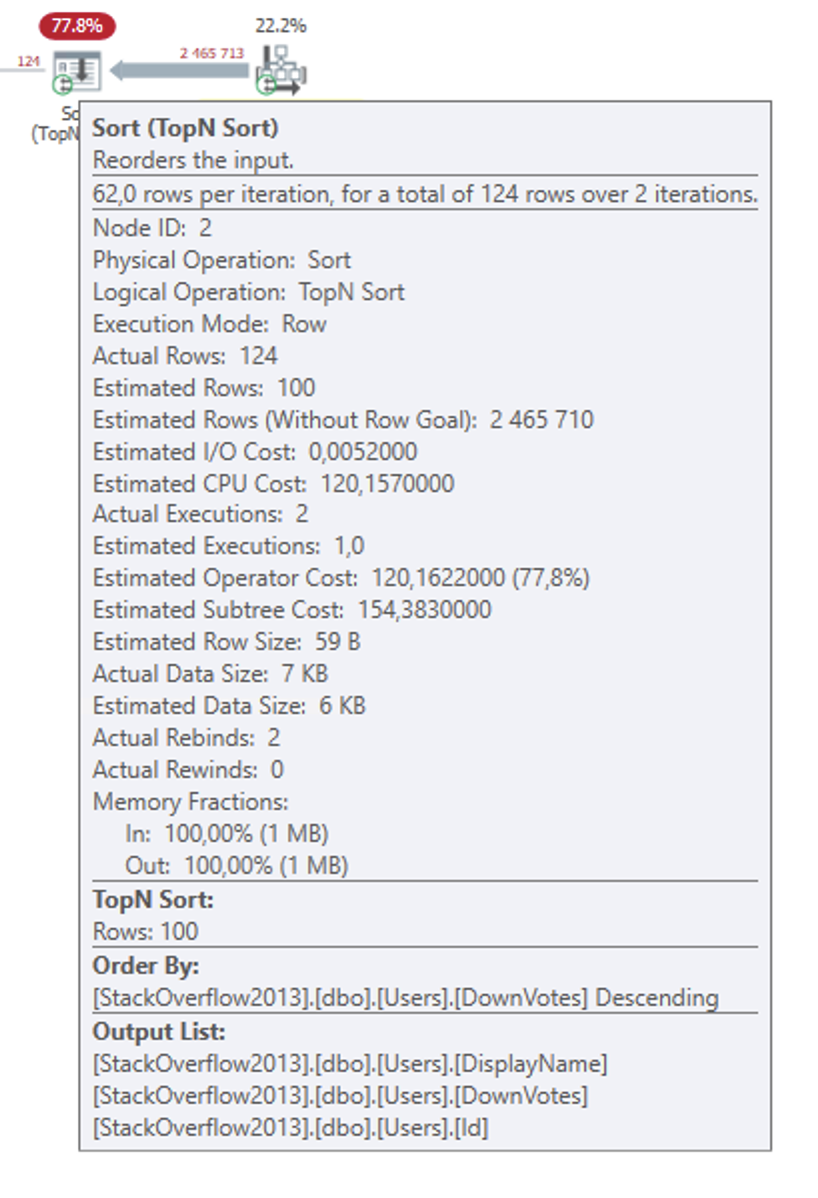
The reason that the smaller query requires so much less memory is that it doesn’t actually store and sort the entire dataset from the Clustered Index Scan operator, as the regular Sort would.
Because the data is relatively small, I suppose, SQL Server keeps just the top 100 rows in an internal work table in memory. For each new row returned by the Scan operator, the Top N Sort operator looks if that row belongs in the top 100. If it does, that row is inserted into the working set and the currently last row (101), is bumped off the working set. And rinse, repeat.
At any point during this iterative process, the only memory we need is to store this work table.
Not just memory
This reflects not just in the memory allocation, but also in execution time. A TOP (101) query takes almost twice as long to run as an otherwise identical TOP (100).
I was going to write a workaround to get more than 100 rows, but I got so far out in the weeds that my legal counsel had to talk me out of it. I’ll save it for another time, when my lawyer is on a well-deserved vacation.