If you’ve worked with reporting, you’ve probably come across the following problem. You have a list of values, say “A, B, C, D, K, L, M, N, R, S, T, U, Z” that you want to display in a more user-friendly, condensed manner, “A-D, K-N, R-U, Z”.
Today, we’re going to look at how you can accomplish this in T-SQL, and what this has to do with window functions and gaps and islands.
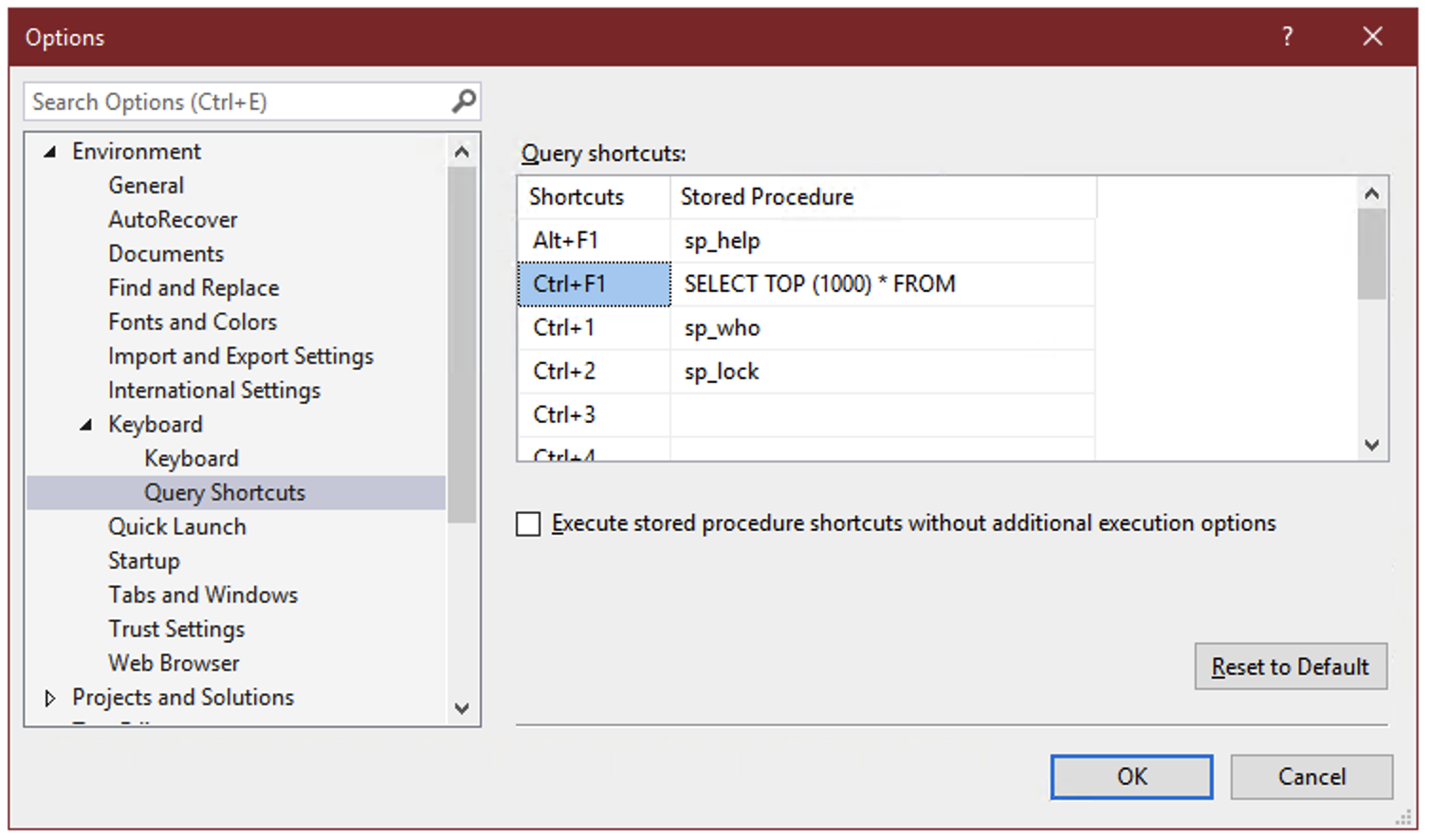
On the surface, these query shortcuts are just what the name implies – a key combination that you can press to run a command or execute a stored procedure. But there’s a hidden super power: whatever text you’ve selected in SSMS when you press the keyboard combination gets appended to the shortcut statement.
So if you select the name of a table, for instance “dbo.Votes”, and press Ctrl+F1, SSMS will run:
SELECT TOP (1000) * FROM dbo.Votes
Preview the contents of a table
This allows you to create a keyboard shortcut to instantly preview the contents of a table or view.
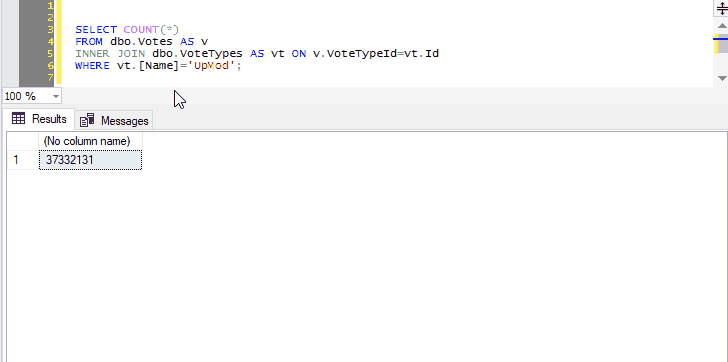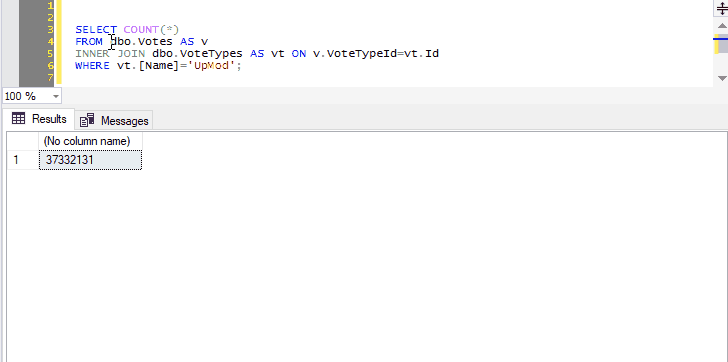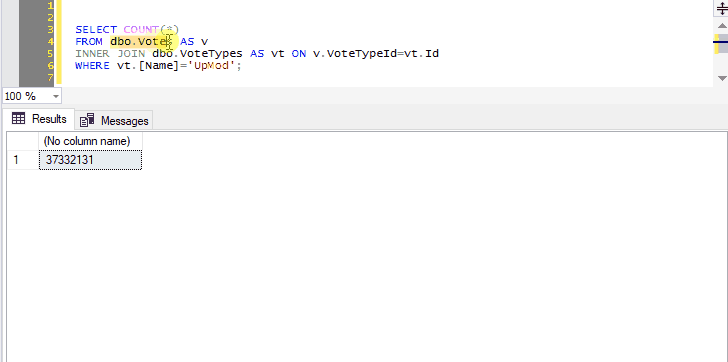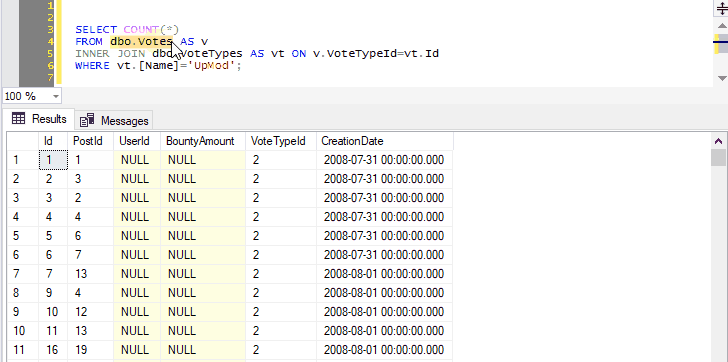
And you can select not just the name of one table, but any other query text you want to tack on:
Preview the contents of two joined tables.
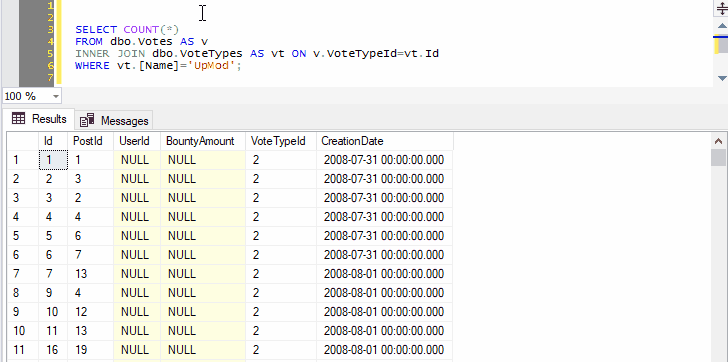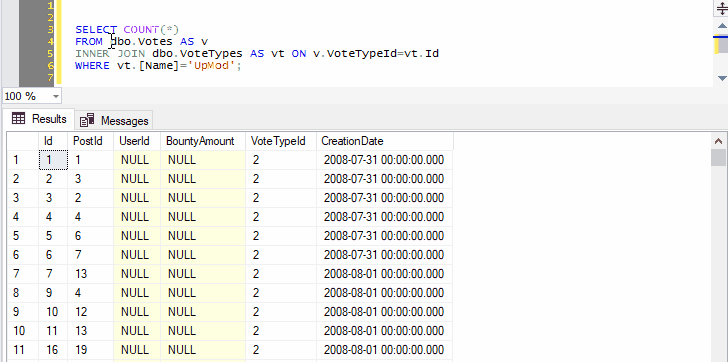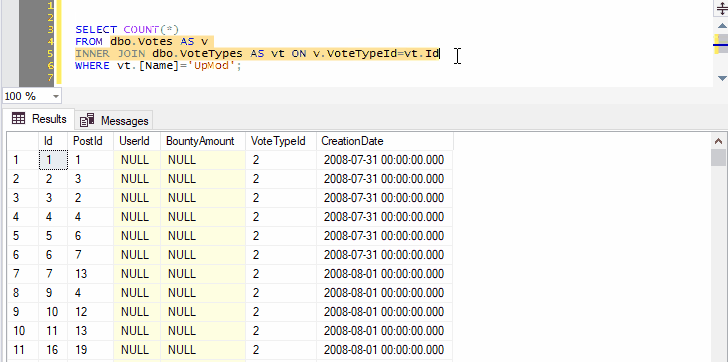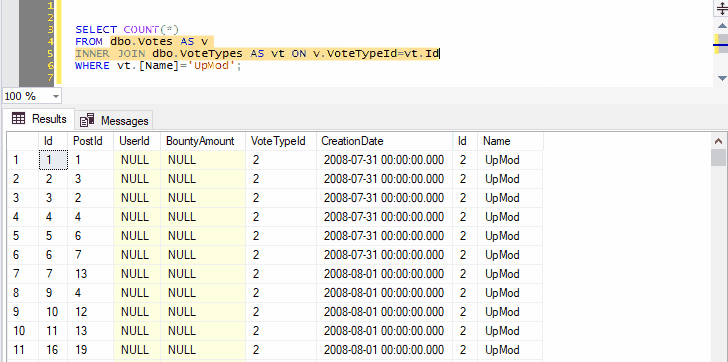
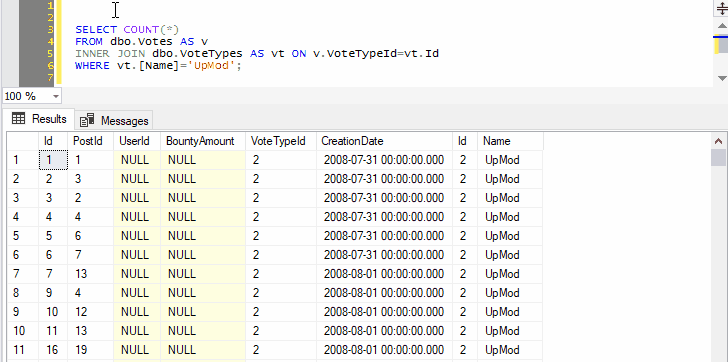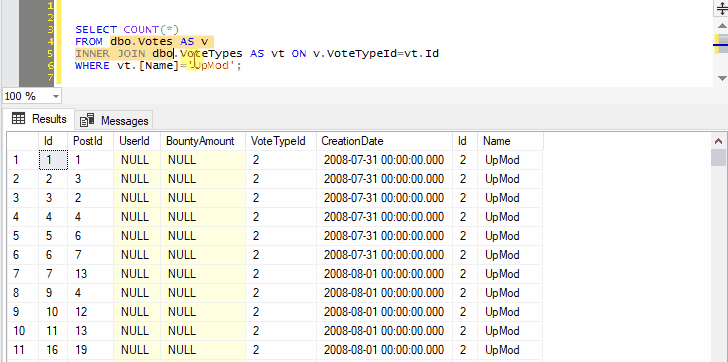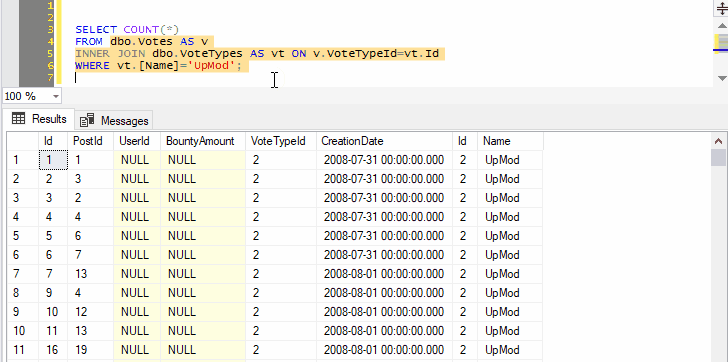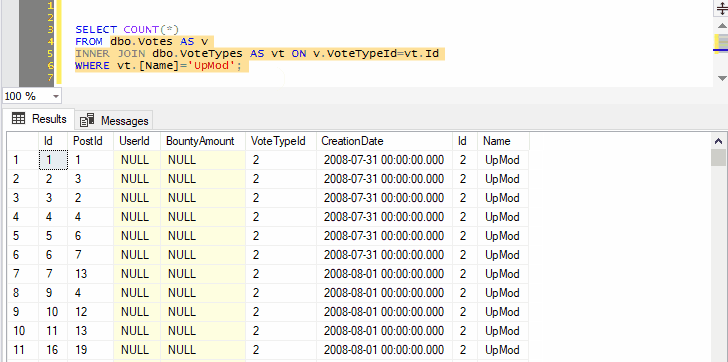
Because we’ve selected both the name of a table and the next line, pressing Ctrl+F1 in SSMS will effectively run the following command:
SELECT TOP (1000) * FROM dbo.Votes AS v
INNER JOIN dbo.VoteTypes AS vt ON v.VoteTypeId=vt.Id
You can go on to include as many joins, WHERE clauses, ORDER BY, as long as the syntax makes sense:
Remember that query shortcuts only apply to new windows, so if you change them, you’ll have to open a new window for the change to take effect.
Implicit conversions in SQL Server follow a specific, predictable order, called data type precedence. This means that if you compare or add/concatenate two values, a and b, with different data types, you can predict which one will be implicitly converted to the data type of the other one in order to be able to complete the operation.
I stumbled on an interesting exception to this rule the other day.
I did some googling to see just how simple I could make a database deployment pipeline. I keep the DDL scripts in a git repository on the local network, but I can’t use Azure DevOps or any other cloud service, and I don’t have Visual Studio installed, so the traditional database project in SSDT that I know and love is unfortunately not an option for me.
So I googled a little, and here’s what I ended up doing.
Using a local service account for your SQL Server service, your server won’t automatically have permissions to access to other network resources like UNC paths. Most commonly, this is needed to be able to perform backups directly to a network share.
Using a domain account as your SQL Server service account will allow the server to access a network share on the same domain, but if the network share is not on your domain, like an Azure File Share, you need a different solution.
There’s a relatively easy way to make all of this work, though.
We’re no strangers to doing things in T-SQL that would perhaps be more efficient in a procedural language. Love it or hate it, a T-SQL solution is easier in some situations, like my sp_ctrl3 procedure that I use as a drop-in replacement for the standard sp_help procedure to display object information in a way that simplifies copying and pasting.
One of the things that sp_ctrl3 does is plaintext database search. If you pass a string to the procedure that does not match an existing object, it’ll just perform a plaintext search of all SQL modules (procedure, views, triggers, etc) for that string. The search result includes line numbers for each result, so it needs to split each module into lines.
I’ve found that this takes a very long time to run in a database with large stored procedures, so here’s how I tuned it to run faster.
You have a table that you want to add “created” and “updated” timestamp columns to, but you can’t update the application code to update those columns. In the bad old times, you had to write a trigger to do the hard work for you. Triggers introduce additional complexity and potentially even a performance impact.
It’s almost like a myth – one that I’ve heard people talk about, but never actually seen myself. The “shock absorber” is a pretty clever data flow design pattern to ingest data where a regular ETL process would choke on the throughput or spikes. The idea is to use a buffer table to capture incoming data, and then run an asynchronous process that loads that data in batches from the buffer into its intended target table.
While I’ve seen whitepapers and blog posts mention the concept loosely along with claims of “7x or 10x performance”, none of them go into technical detail on how it’s done, so I decided to try my hand at it.
I’ve compiled my findings, along with some pre-baked framework code if you want to try building something yourself. Professional driver on closed roads. It’s gonna get pretty technical.
I recently ran into a curious deadlock issue. I have a process that performs a lot of updates in a “state” table using multiple, concurrent connections. The business logic in the application guarantees that two connections won’t try to update the same item, so we shouldn’t ever run into any locking issues. And yet, we keep getting deadlocks.
What’s going on here? Hint: it has to do with isolation levels and range locks.