It’s almost like a myth – one that I’ve heard people talk about, but never actually seen myself. The “shock absorber” is a pretty clever data flow design pattern to ingest data where a regular ETL process would choke on the throughput or spikes. The idea is to use a buffer table to capture incoming data, and then run an asynchronous process that loads that data in batches from the buffer into its intended target table.
While I’ve seen whitepapers and blog posts mention the concept loosely along with claims of “7x or 10x performance”, none of them go into technical detail on how it’s done, so I decided to try my hand at it.
I’ve compiled my findings, along with some pre-baked framework code if you want to try building something yourself. Professional driver on closed roads. It’s gonna get pretty technical.
Goal and prerequisites
I’m designing a database for a rather bursty workload of inserts and selects on a handful of large tables. In a perfect world, I would like to be able to ingest large amounts of transactions every second, while being able to query that data without significant locking or deadlocking issues.
Ingested rows need to be merged into the target table, as we’ll receive both new and updated rows from the data source. This prevents me from just bulk inserting rows into the target table.
For my lab environment, I’ve set up an L8s_v2 Azure VM, which comes with 8 CPU cores, 64GB of memory, and most importantly, locally attached ephemeral NVMe storage, where I can get low disk latency and high throughput comparable to good on-prem storage. The database server is a fully patched SQL Server 2019 (CU-10, at the time of writing).
An SSIS package that runs on another machine acts as the data source, and bulk inserts data into my demo database. I’ve tuned it to push up to 100,000 transactions/second sustained, which is more than enough to keep the target database busy and any DBA slightly nervous.
Setting a baseline
In a previous post, I designed another SSIS package to distribute row-by-row MERGE statements across a dozen connections in a round-robin pattern. I managed to get that package to maintain a sustained load of 14,000 batch requests/second. This is what that SSIS package looked like:
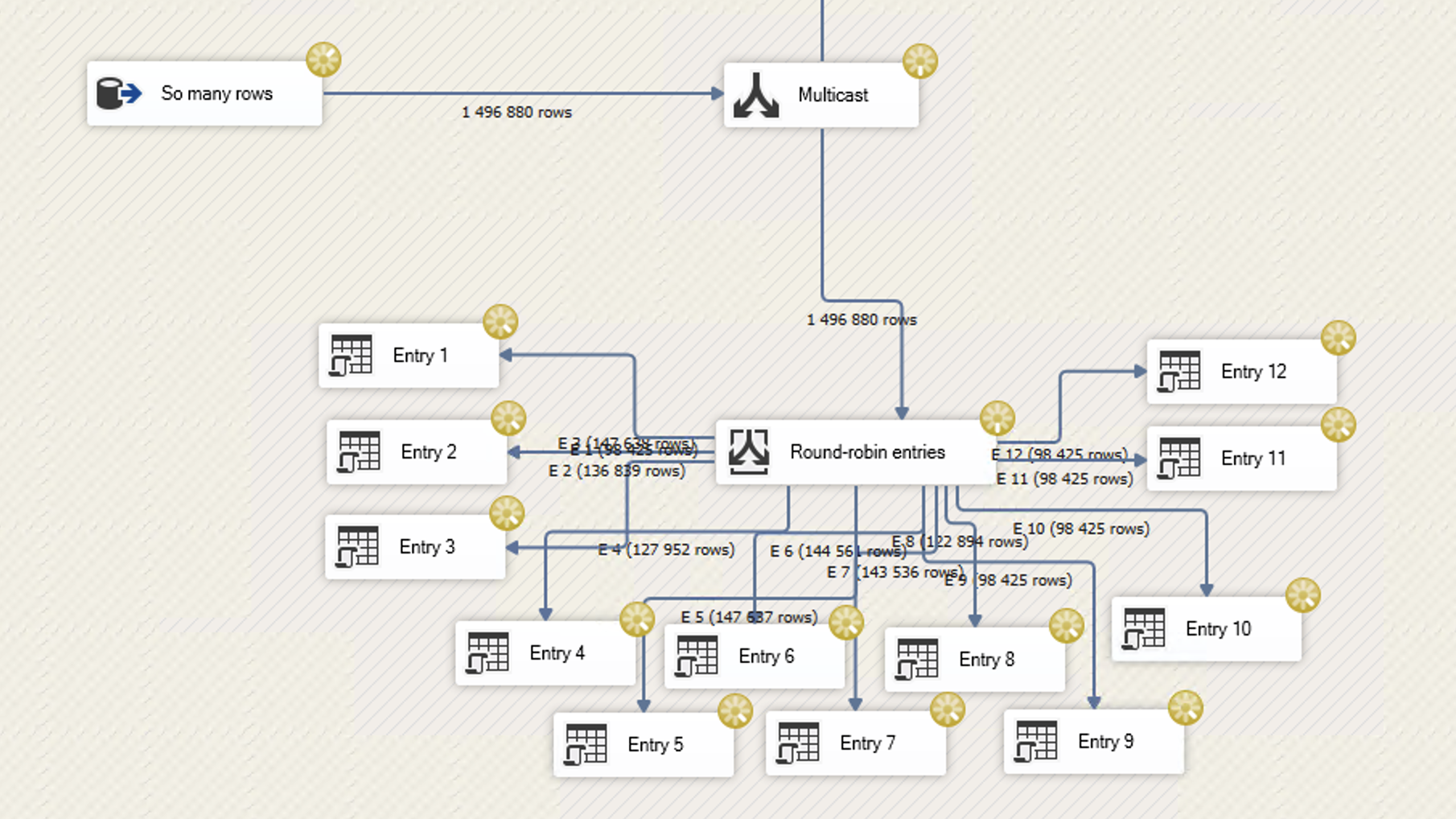
… and this is the SQL Server’s CPU while the package runs.
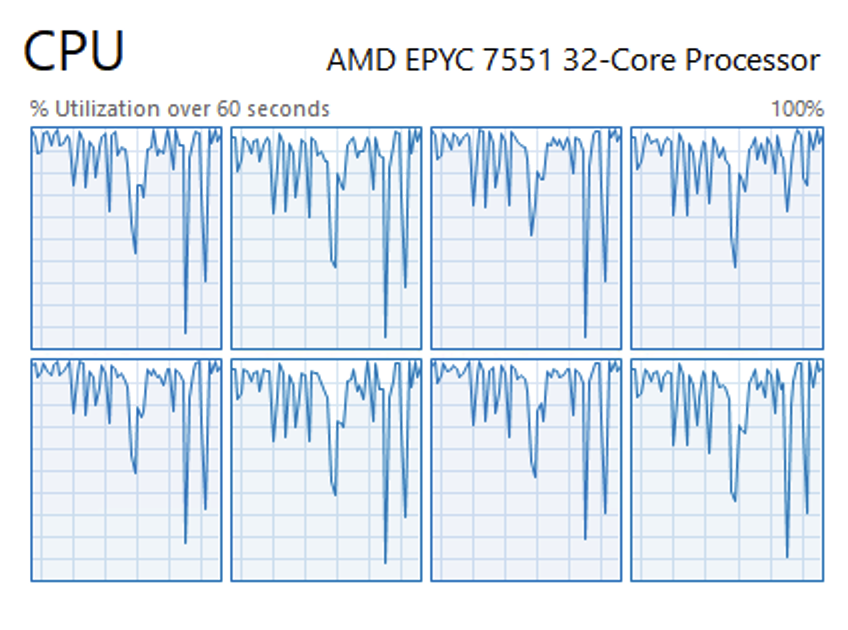
Needless to say, everything else grinds to a halt when this workload runs. But for a row-by-row OLTP workload, I’m pretty happy with 14,000 batch requests per second on an 8 core box.
The design pattern
Here’s a simple sketch of my shock absorber design:
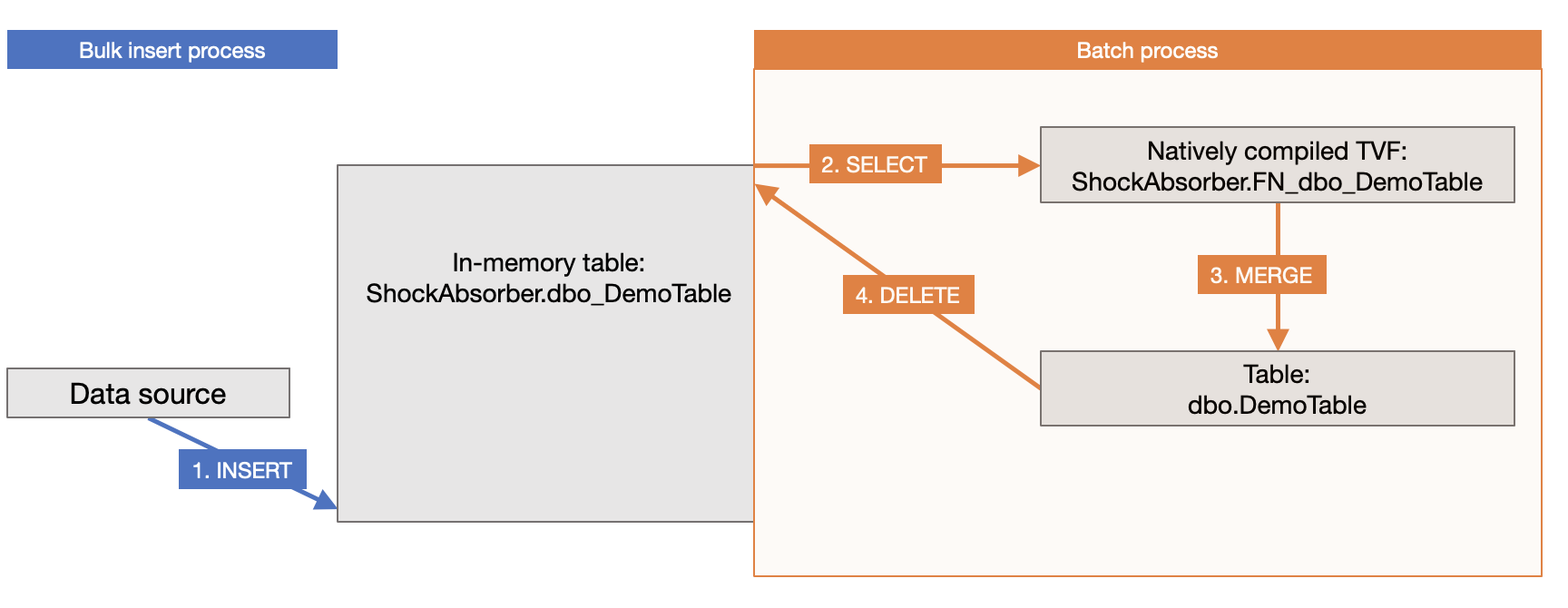
On the ingest side (left), our client application inserts rows directly into the in-memory table.
Asynchronously, the batch process (right) tries to keep up, packaging those rows in batches and merging the batches into the disk-based table. When that is done, those rows are removed from the in-memory table, and the cycle starts over.
The base table
Here’s a simple base table that we want to load data into:
CREATE TABLE dbo.DemoTable (
a int NOT NULL,
b int NOT NULL,
c int NOT NULL,
d varchar(100) NOT NULL,
e datetime2(6) NOT NULL,
PRIMARY KEY CLUSTERED (a, b)
);
The shock absorber table
The buffer table shares all of the columns from the base table, with the addition of an identity column.
We’ll use that identity column to maintain the sequence in which the rows are inserted. This is important, in order to be able to tell which rows are duplicates, and which ones of those duplicates are the most recent (current) ones.
Remember that the same primary key could arrive multiple times in the buffer table, as we want to MERGE those rows into the base table. Because we’re batching the data, we’ll need to isolate only the most recent row for each primary key value.
CREATE TABLE ShockAbsorber.dbo_DemoTable (
[##ShockAbsorberIdentity##] bigint IDENTITY(1, 1) NOT NULL,
a int NOT NULL,
b int NOT NULL,
c int NOT NULL,
d varchar(100) NOT NULL,
e datetime2(6) NOT NULL,
CONSTRAINT PK_DemoTable PRIMARY KEY NONCLUSTERED ([##ShockAbsorberIdentity##]),
UNIQUE INDEX IX (a, b, [##ShockAbsorberIdentity##])
);
The natively compiled table value function
An important key to get the best performance from in-memory tables is to keep the data and the logic inside the Hekaton engine for as long as possible. If you run a regular T-SQL procedure on a Hekaton table, the data needs to leave the Hekaton “container”, before being processed in the disk-based container. A natively compiled module will do the processing entirely inside the Hekaton container – technically in a compiled CLR assembly – which makes it much, much faster.
For this purpose, we’re designing a table value function to extract a given number of rows from the buffer table, and we’re making this TVF natively compiled.
CREATE FUNCTION ShockAbsorber.FN_dbo_DemoTable(@identity bigint)
RETURNS TABLE
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
RETURN (
SELECT [a],
[b],
[c],
[d],
[e]
FROM [ShockAbsorber].[dbo_DemoTable] WITH (INDEX=[PK_DemoTable])
WHERE [##ShockAbsorberIdentity##] IN (
SELECT MAX([##ShockAbsorberIdentity##])
FROM [ShockAbsorber].[dbo_DemoTable]
WHERE [##ShockAbsorberIdentity##]<=@identity
GROUP BY [a],
[b])
);
Notice how this function also removes duplicates. However, because of the limited instruction set for natively compiled modules, we have to use an old-style subquery with a GROUP BY, rather than a window function, but the performance is still much faster than a comparable disk-based query.
Putting it all together
A procedure called ShockAbsorber.SYNC_dbo_DemoTable runs in an infinite loop where it:
- Gets the highest identity value for the batch size defined (say, the 1,000th identity value, if we want to load 1,000 rows in a batch)
- Merges the data from the TVF (1,000 rows in that range of identity values) into the target table
- Deletes rows up to that identity value from the buffer table
- If no rows were loaded, wait the defined time until trying again. Otherwise, start over again immediately.
I chose not to put this into an explicit SQL transaction for a few reasons:
- Transactions are tricky when you work with in-memory tables and disk-based tables in the same transaction (“cross-container transactions”). You need to manually hint the isolation level.
- Isolation level hints are not allowed in natively compiled inline table value functions.
Ned Otter (b|t) wrote a two-part blog series about in-memory isolation levels (part 1 and part 2). This is a great read, and really helps in understanding of how transactions work when you’re working with in-memory tables.
In the end, even though I’m skipping the explicit transactions, we’ll still have some measure of transactional integrity, because we use a MERGE statement to batch the data into the disk-based table:
- If the procedure crashes getting the identity value, no changes have been done.
- If it crashes in the MERGE, that merge operation is rolled back.
- If it crashes in the DELETE, the rows in the buffer table will just be retried in the next batch, where it will essentially perform an update of all rows without changing any column values. No harm done.
- The batch procedure must not run on multiple sessions for the same table.
“But Daniel, this is a lot of code to write for each table”, I hear you say. And you’d be right:
Building a framework
So I’ve put all of this logic inside a configurable framework that does most of the hard work for you. You can download it from this Github repository.
A single procedure call generates all of the required database objects:
EXECUTE ShockAbsorber.[Create]
@Object='dbo.DemoTable',
@Persisted=0,
@Interval_seconds=0.5,
@Interval_rows=1000,
@Drop_existing=1,
@Maxdop=1,
@HashBuckets=NULL;
The parameters are:
- @Object, sysname: The name of the base table (required).
- @ShockAbsorber_schema, sysname: The schema where you want the shock absorber logic (buffer table, tfv, etc). Defaults to ‘ShockAbsorber’.
- @Persisted, bit: if the buffer table is persisted to disk. Defaults to 1.
- @Interval_seconds, numeric(10, 2): How often (in seconds) the procedure will poll the buffer table. Defaults to 1 second.
- @Interval_rows, bigint: Limits the batch size in number of rows. Defaults to NULL, meaning it batches all queued rows.
- @Drop_existing, bit: If an existing buffer table can be dropped and recreated. Defaults to 0.
- @Maxdop hints a maximum degree of paralellism. Defaults to 0.
- @HashBuckets, bigint: The number of hash buckets for a hash index on the buffer table. Defaults to NULL, which means a non-clustered index is used.
Once you’ve created the components, you can start polling the buffer table:
EXECUTE ShockAbsorber.SYNC_dbo_DemoTable;
This procedure is precompiled for your defined batch sizes, intervals, etc. There are a few parameters, if you want ’em:
- @RunOnlyOnce, bit: if set to 1, runs only a single batch. Defaults to 0.
- @PrintStats, bit: prints the number of rows and duration of each batch to the output. Defaults to 0.
- @MaxRows, bigint: the total number of rows after which the procedure will terminate. Defaults to NULL.
- @MaxErrors, int: the total number of errors after which the procedure terminates. Defaults to 3.
Performance testing
In development, I created an automated routine to generate a test table (not the same as the one above!) with different permutations of parameter values,
- Partitioned vs. unpartitioned
- Clustered primary key vs. a heap with a non-clustered primary key
- Disable statistics updates, enable auto statistics updates, or enable asynchronous statistics updates
- No compression, row compression, or page compression
Beyond these factors, the framework will also let you configure a couple of other parameters, such as if you want your in-memory table to be persisted to disk or not, if you want a non-clustered index or a hash index, and if so, how many hash buckets. However, in order to keep my testing at a feasible level, I opted to just go for one default setting.
And here are the first results, ordered by duration for 501 batches of 1,000 rows each:
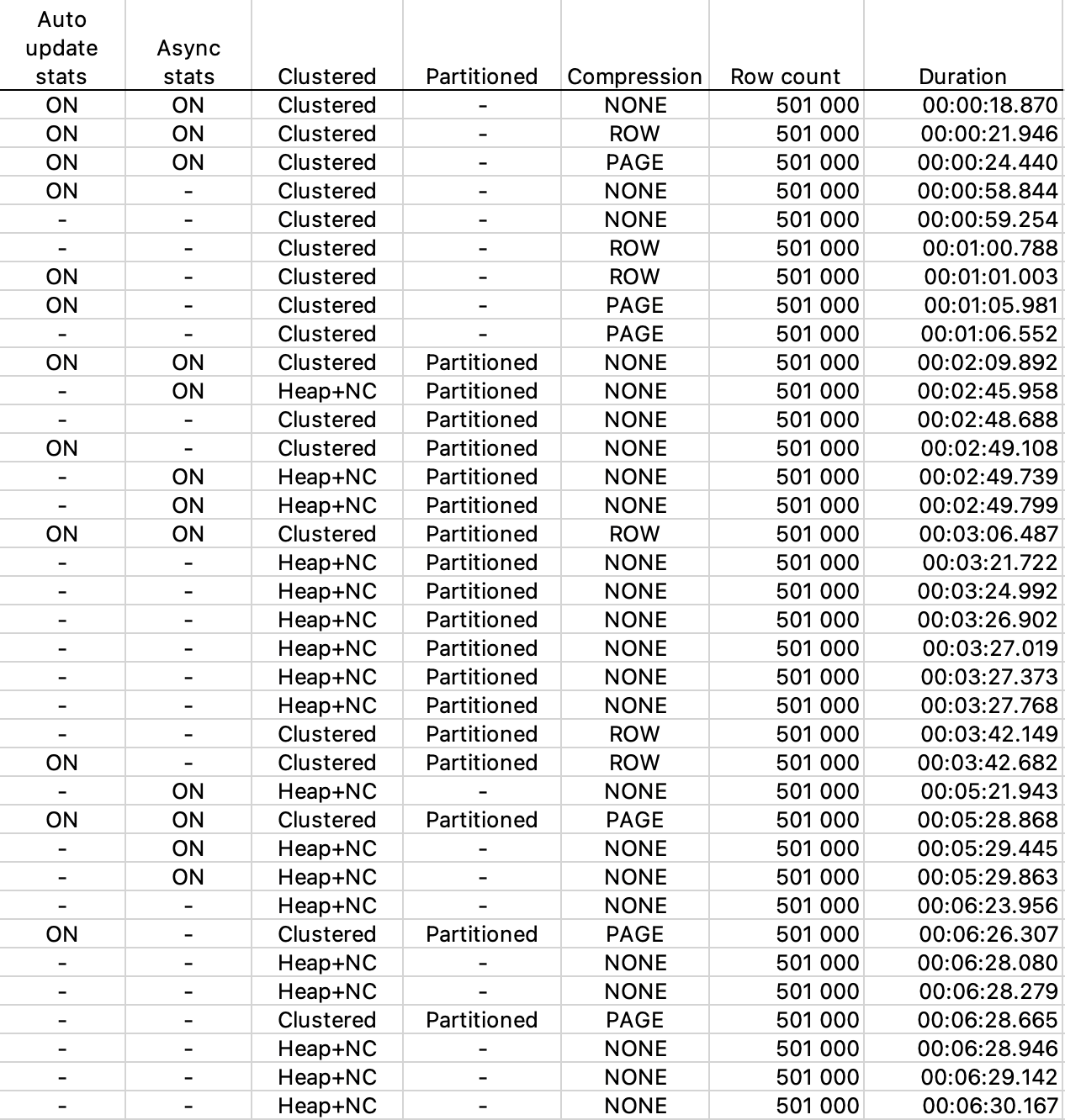
Right off the bat, the following stands out:
- Heaps are bad. This application is no exception.
- Partitioning affects performance negatively for clustered tables by a significant amount, but surprisingly, improves performance for a heap by about a factor of 2!
- Row compression and page compression add about 15 and 30% of overhead respectively.
- Asynchronously updating statistics help alleviate spikes where SQL Server appears to throttle writes to the table while it updates the statistics. I started with an empty table, so this may not be as significant on a table that already has a lot of data, and thus doesn’t hit the statistics update threshold as frequently.
Nothing surprising going on in the waits: we’re writing to the log, and working the CPU.
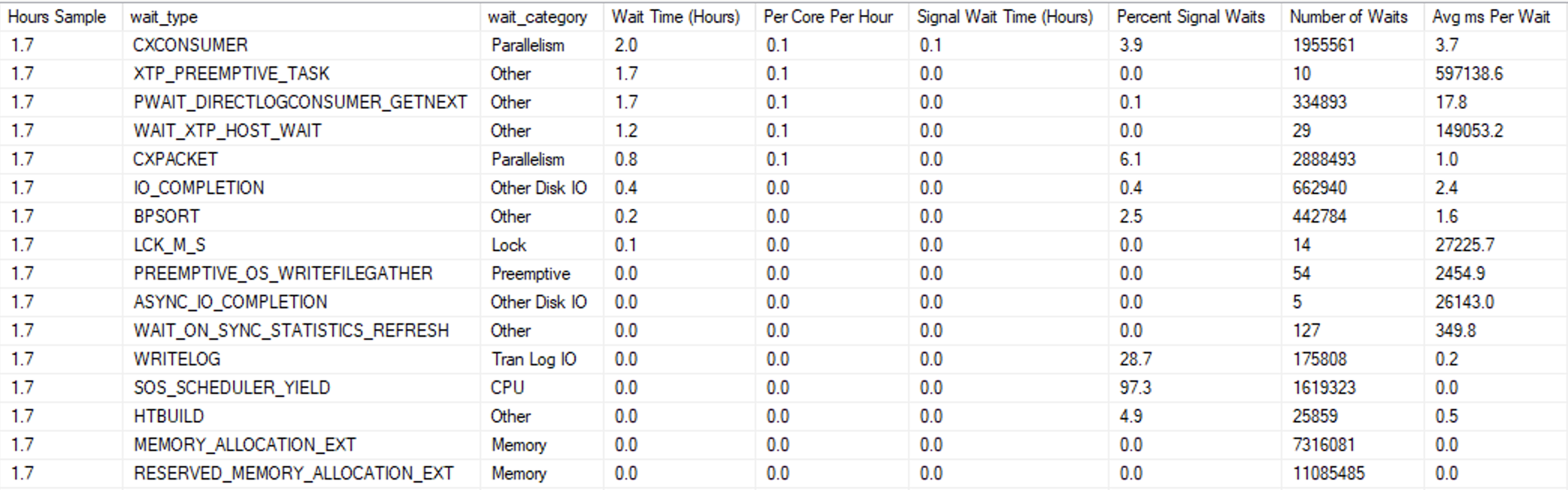
Particularly with larger batch sizes, parallelism waits are significant if you don’t set @Maxdop=1. But this is to be expected.
Drilling down: different batch sizes
I drilled down to look at the performance over time for the top-performing parameter set: asynchronously updated stats, clustered, no compression, max degree of parallelism unrestricted.
I ran the batch load multiple times with different batch sizes on both partitioned and non-partitioned tables.
It’s pretty interesting to see how the performance develops over time.
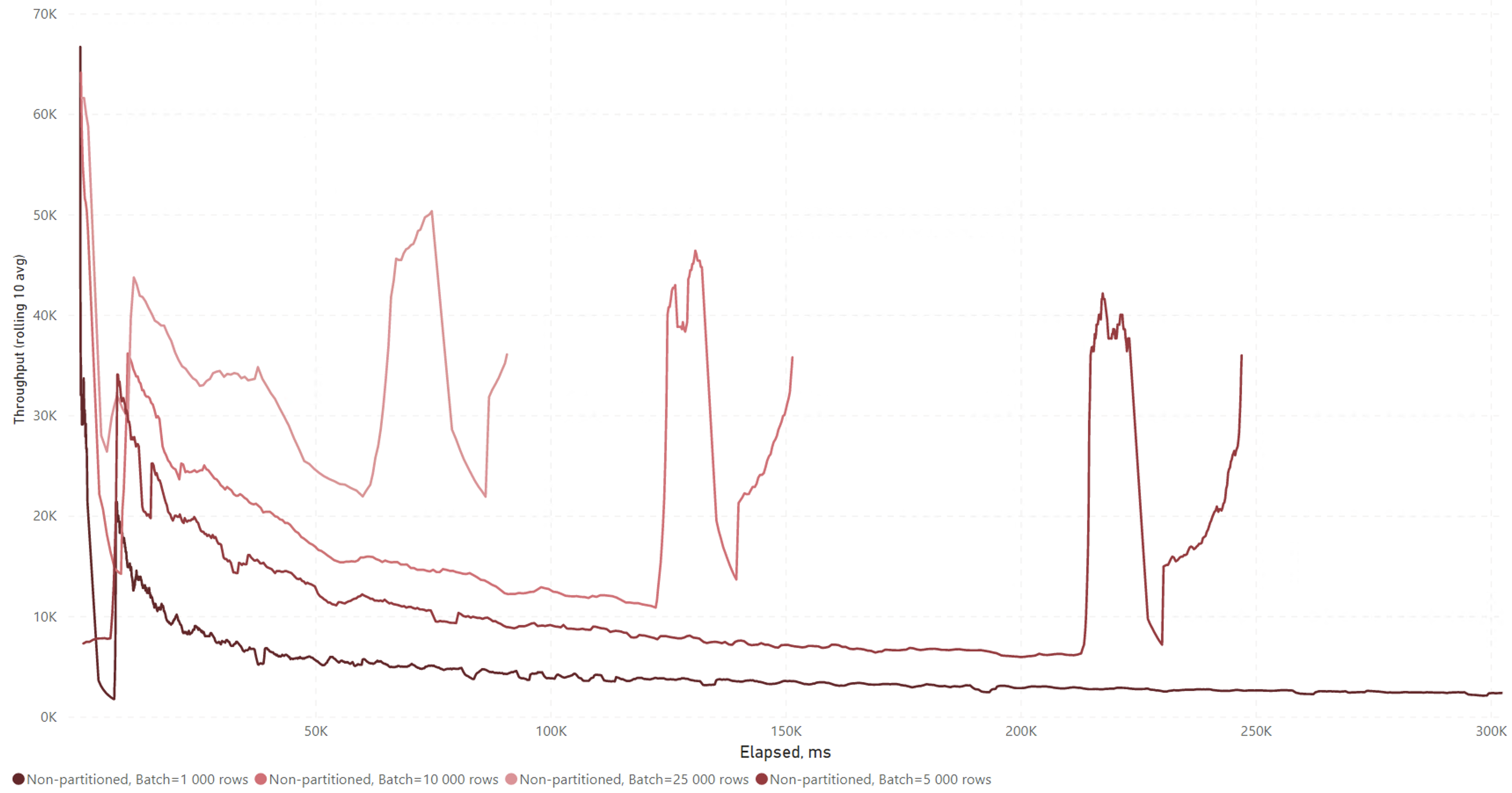
Irrespective of the batch size, we see the same performance pattern in the data: there’s a pretty short ramp-up time, after which the throughput drops gradually.
I suspect the “bump” near the end has to do with the dataset, which was the same for all attempts, but I haven’t verified this.
If I had to guess, the gradual decrease in write performance is probably due to page splits. The data arrives mostly randomly across the clustered index. As we start out with an empty table, the first few batches will just write to new, mostly sequential pages. After a short while, we’ll start inserting our data between existing rows in the clustered index, inevitably leading to page splits.
For the partitioned table, things look a little different:
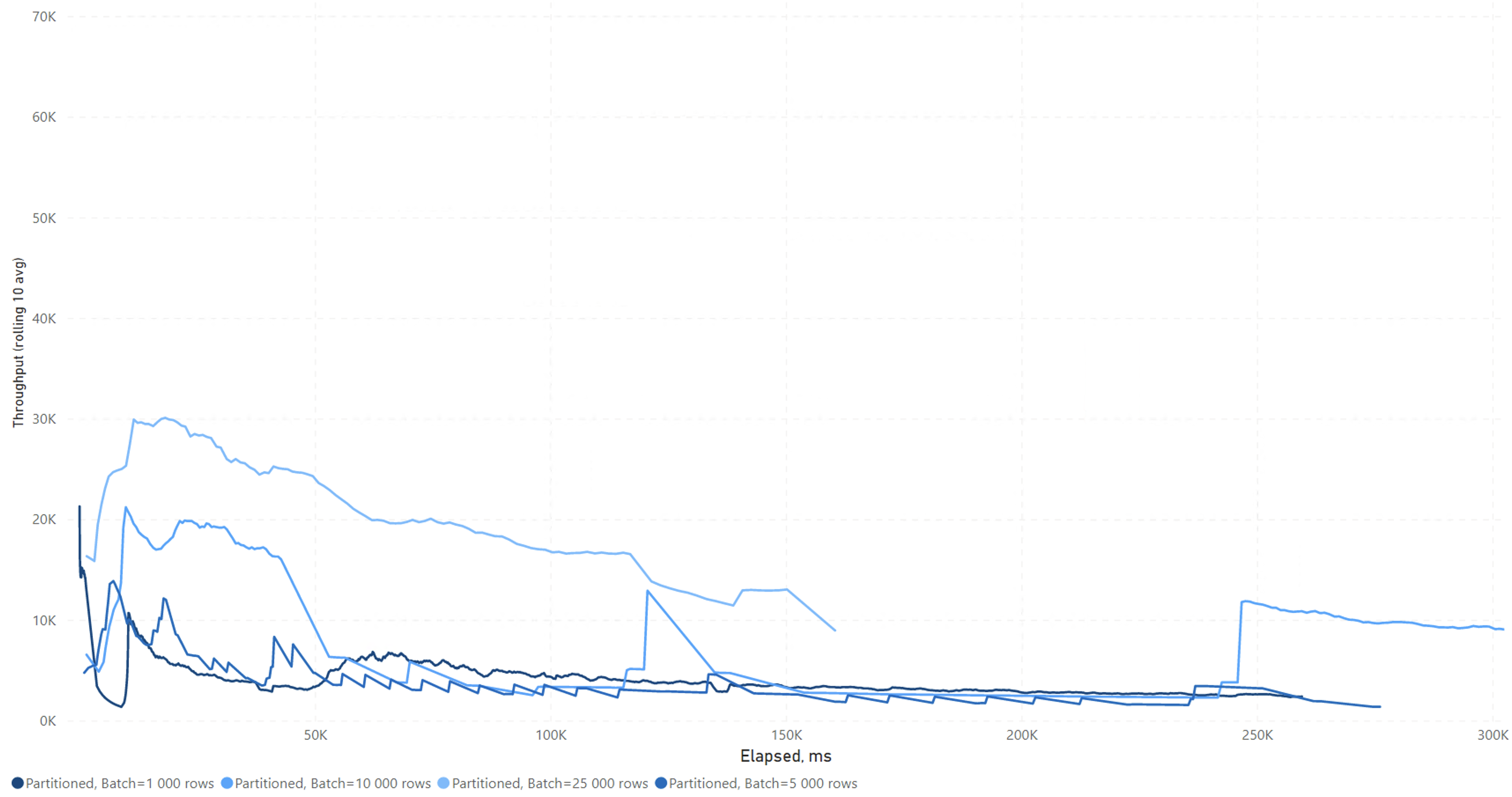
In the initial tests, where we used 1,000 row batches, partitioning dramatically decreased the write performance. But with larger batch sizes, this effect is less noticeable, although still significant.
It made very little performance difference if the clustered index was aligned or not (i.e. whether or not the partitioning column was the leading column of the clustered index).
Running inserts and batching simultaneously
When I run the SSIS package and the batch procedure (at a 10,000 row batch size, unpartitioned, uncompressed table) at the same time, the batch procedure initially keeps up, but quickly falls behind because of the sheer speed of the bulk insert.
The batch procedure maxes out around 40,000 rows/second, then falls back to 20,000. This performance is very similar to what we saw without the added load of the SSIS bulk insert.
Impressively, the two processes don’t appear to significantly block or throttle each other. The only place where they “touch” is the in-memory buffer table, and because it is a Hekaton table, it’s essentially free from latching and locking issues.
The SQL Server’s CPU looks much more comfortable now than before.
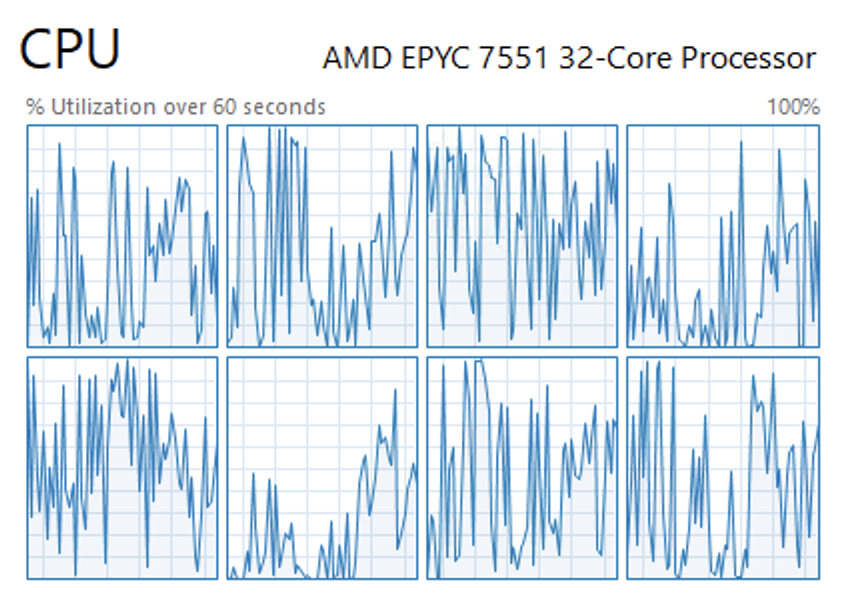
Setting @Maxdop=1 yielded similar performance with even lower CPU usage initially, but after a few minutes, with more data in the base table, performance appeared to degrade more quickly. In a production scenario, I would consider going with maxdop 1 if I was populating multiple tables, or if there are other processes that need some CPU cycles too.
Conclusions
The premise of this little experiment was to create a solution that would allow me to MERGE as many transactions per second as possible into a base table. When I tried a simple SSIS-based row-by-row solution, I could achieve about 14,000 batch requests per second on my hardware setup, but it absolutely hammered the server.
Bulk inserting the data would have been dramatically faster, but this was not an option because you can’t “bulk merge” in SQL Server.
The shock absorber pattern in this blog post allows us to split the ingest procedure into two asynchronous processes in order to quickly ingest bursty ETL loads from the source, while still keeping the target table reasonably available to other processes.
You would parameterize the batch procedure differently depending on how you expect your throughput to look – short high-speed bursts or sustained medium-high throughput.
Either way the performance of the shock absorber pattern is roughly comparable or better then the original row-by-row SSIS solution, but the CPU does only about half of the work. This leads me to believe that this solution could probably be tuned to perform even better.
Key findings:
- Avoid heaps is possible. A single clustered index (no non-clustered indexes) is optimal for write performance.
- Partitioned tables carry a performance penalty.
- Asynchronously updated statistics made all the difference for the shock absorber pattern, because synchronous statistics would frequently hold up the batch process for up to a minute or more while the stats are updated.
The code for the framework can be found in this Github repository. Pull requests appreciated.
Things I haven’t covered
There are so many options and settings I haven’t worked out for this post, including:
- Hash indexes on the in-memory table, and the impact of hash bucket count.
- Tweaking fill factor.
- I’ve used a MERGE JOIN hint in the batch query, but there may be better performing options.
- The impact of disk-persisted vs. non-persisted Hekaton tables. I suspect the impact would be minimal.
- Digging deeper into the page split performance impact.
Acknowledgements
Big thanks to William Durkin (b|t) who graciously took time out of his Sunday to provide me with valuable ideas!
For historical reference, look at the paper from 2009
We Loaded 1TB in 30 Minutes with SSIS, and So Can You
Writers: Len Wyatt, Tim Shea, David Powell Published: March 2009
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd537533(v=sql.100)?redirectedfrom=MSDN
For some reason, I seem to remember Thomas Kejser doing something like this, and instead of using Integers, used GUIDs, and got better load performance into a heap.