![]() Everyone has a script, a hack or a checklist they can’t function without. In this edition of T-SQL Tuesday, Bert Wagner challenged us to write about our favorite scripts. This is my take.
Everyone has a script, a hack or a checklist they can’t function without. In this edition of T-SQL Tuesday, Bert Wagner challenged us to write about our favorite scripts. This is my take.
Category: Tips
Quick and dirty: How to right-align numeric columns in SSMS
Here are 50 random numbers:
--- 50 random numbers WITH cte AS ( SELECT 0 AS i, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) AS n UNION ALL SELECT i+1, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) FROM cte WHERE i<50) SELECT * FROM cte;
And in SSMS, with the variable-width default font, the output looks… slightly-less-than-readable in the grid view:
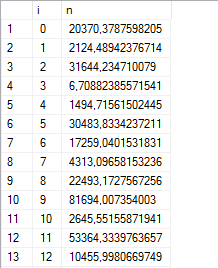
We could use STR() to format the output, but the indent looks a little off:
--- 50 random numbers WITH cte AS ( SELECT 0 AS i, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) AS n UNION ALL SELECT i+1, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) FROM cte WHERE i<50) SELECT *, STR(n, 12, 2) AS with_str FROM cte;
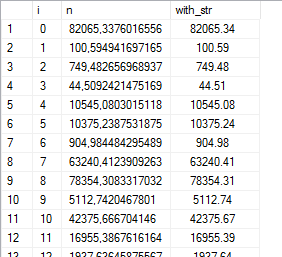
Here’s something I’ve found: the space character is roughly about half the width of a typical number character. So replace every leading space with two spaces, and it will look really neat in the grid:
--- 50 random numbers
WITH cte AS (
SELECT 0 AS i, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3) AS n
UNION ALL
SELECT i+1, 100000.*POWER(RAND(CHECKSUM(NEWID())), 3)
FROM cte WHERE i<50)
SELECT *, STR(n, 12, 2) AS with_str,
REPLACE(STR(n, 12, 2), ' ', ' ') AS with_replace
FROM cte;
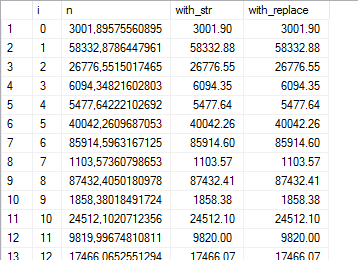
(and terrible everywhere else, obviously.)
An alternative to data masking
Dynamic data masking is a neat new feature in recent SQL Server versions that allows you to protect sensitive information from non-privileged users by masking it. But using a brute-force guessing attack, even a non-privileged user can guess the contents of a masked column. And if you’re on SQL Server 2014 or earlier, you won’t have the option of using data masking at all.
Read on to see how you can bypass dynamic data masking, and for an alternative approach that uses SQL Server column-level security instead.
Computed columns with scalar functions
Scalar functions can be a real headache when you’re performance tuning. For one, they don’t parallelize. In fact, if you use a scalar function in a computed column, it will prevent any query that uses that table from going parallel – even if you don’t reference that column at all!
Encrypting SQL Server connections with Let’s Encrypt certificates
Encrypting your SQL Server’s TDS connections should be high on your list of things to do if you’re concerned with the privacy of your data. This often boils down to one big problem: can you get a valid certificate without paying a ton of money, and will it work with SQL Server?
So follow me down the rabbit hole, as we work out the steps to using Let’s Encrypt to create (and auto-renew!) a certificate for SQL Server. This is going to get technical.
Legacy apps that don’t believe in schemas
Inspired by an actual customer scenario: what if you have a legacy app that doesn’t schema-prefix its database objects, but you want it to work with a specific assigned schema? There’s a quick and easy solution.
Speaking at the Group By conference!
This past Friday, I had the great privilege of speaking at the on-line Group By conference. Group By is a community-driven conference where anyone can submit an abstract. Site visitors will then rate sessions as well as help you build and improve your abstract.
My presentation was about various tips and tricks in SQL Server Management Studio, some of which I’ve already covered in previous articles on this blog.
Have you tried sp_ctrl3?
I frequently need to look up object definitions when I’m developing or query tuning. You could use Object Explorer in SSMS, but that takes a lot of time and clicking. Then there’s the Alt+F1 shortcut, which will trigger the sp_help stored procedure. That however, comes with a lot of annoying built-in limitations, so a few years ago I started building and maintaining a “better Alt+F1” of sorts.
I decided to call it “Ctrl+3“. But I suppose you could assign it to any keyboard shortcut you want.
A visual representation of SQL Server Agent jobs
If all you have is a hammer, everything will eventually start looking like a nail. This is generally known as Maslow’s hammer and refers to the fact that you use the tools you know to solve any problem, regardless if that’s what the problem actually needs. With that said, I frequently need a way to visualize the load distribution of scheduled jobs over a day or week, but I could never be bothered to set up a web server, learn a procedural programming language or build custom visualizations in PowerBI.
So here’s how to do that without leaving Management Studio.
The compelling case for using heaps
I’m an outspoken advocate of always using a clustered index on each and every table you create as a matter of best practice. But even I will agree that there’s a case for using the odd heap now and then.