I recently ran into a curious deadlock issue. I have a process that performs a lot of updates in a “state” table using multiple, concurrent connections. The business logic in the application guarantees that two connections won’t try to update the same item, so we shouldn’t ever run into any locking issues. And yet, we keep getting deadlocks.
What’s going on here? Hint: it has to do with isolation levels and range locks.
A single statement that does everything.
Let’s set up a very simple test table and give it some test data:
CREATE TABLE dbo.ApplicationState (
id int NOT NULL,
val int NOT NULL,
PRIMARY KEY CLUSTERED (id)
);
INSERT INTO dbo.ApplicationState (id, val)
VALUES (100, 0),
(10000, 0);
We have an app that very frequently and highly concurrently updates the ApplicationState table with a MERGE statement. The great thing with the MERGE statement is that you don’t have to check if the row exists. With a single statement, SQL Server updates or inserts a row depending on if it already exists or not:
MERGE INTO dbo.ApplicationState WITH (HOLDLOCK) AS t
USING (
VALUES (@id, @val)
) AS s(id, val) ON t.id=s.id
WHEN NOT MATCHED THEN
INSERT (id, val)
VALUES (s.id, s.val)
WHEN MATCHED THEN
UPDATE
SET t.val=s.val;
You’ll notice that there’s a HOLDLOCK hint on the target table. We’ll need to talk a little about this.
MERGE has some issues
Years ago, Aaron Bertrand compiled an excellent blog post with all the reported issues with the MERGE statement (there are many), and a surprising amount of them are marked as “Won’t fix” by Microsoft – either because it’s “By design” or because it’s just plain-old not important enough for Microsoft to fix them.
My own takeaway from this post is that if you’re on an older SQL Server version, or if you do funky things like filtered indexes or indexed views, you should carefully review the list if there are issues that might impact you. For a very simple use-case like the one we’re working on here, we’ll probably be fine. One of the generally accepted recommendations to avoid most of these issues is to add a WITH (HOLDLOCK) hint to the target table.
The HOLDLOCK hint tells SQL Server to use the Serializable transaction isolation level. I have a whole post on isolation levels, but you can think of isolation levels as the server’s “SLA”, a promise if you will, to the client application.
- The default “Read Committed” isolation level, basically means: “I promise that what I showed you was accurate and committed at the time.”
- You may have played around with “Read Uncommitted” (the NOLOCK hint). It roughly translates to “To somebody, this may have been accurate at the time, but we don’t know if that transaction will even be committed.”
- The “Serializable” isolation level is the strictest of them all. “I promise that what you saw will still be true if and when you look again.”
What HOLDLOCK does to a MERGE statement
Disclaimer: Simplifications ahead. If you want to dig a little deeper, check out Klaus Aschenbrenner’s posts on Lock Escalation, Update Locks, and Intent lock.
To maintain an isolation level’s promise, and certainly that of the Serializable isolation level, SQL Server needs to place locks. With Read Committed, locks are placed on objects that you modify, in order to prevent other processes from reading something that you may or may not choose to commit later on.
But Serializable places locks even on things you look at – because if you’ve looked at it, SQL Server makes sure that it looks the same if you come back and look at it later on.
Here’s what our MERGE statement looks like in the execution plan. This explains pretty well what the MERGE statement does:
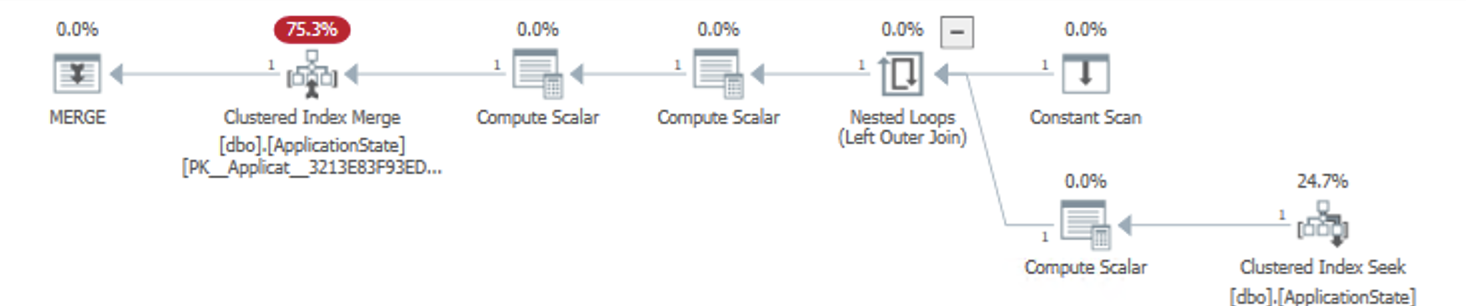
From right to left, the first order of business is to establish if the row exists or not. That’s the Clustered Index Seek in our case. A tiny fraction of a millisecond later, the outcome of that Seek determines if we perform an UPDATE or an INSERT in the Clustered Index Merge operator to the left.
In a database with high transaction throughput, there’s always the risk that the table could change in the short time after we perform the Seek, but before we execute the Merge. If that were to happen, we would get an unexpected outcome, like update a row that no longer exists, or inserting a row that someone else has already created.
Key lock vs. Range lock
If the Seek hits an existing row, SQL Server will place a key lock on that specific row. This prevents other processes from changing this exact row until we’re finished with it. Remember, because we’re in Serializable, we expect the row we saw to be there next time we need it, and to look just the way we found it.
But if we didn’t find a row, there’s nothing specific to lock, because locks can only be placed on keys (rows), pages, partitions, tables and schemas. SQL Server cannot lock an arbitrary search criteria like “WHERE id=123”, because that would create a computational nightmare. To solve this, SQL Server will place a range lock, which holds not a specific key, but everything between two existing keys.
As you can see, our single-point lookup just got a little more invasive.
If we have a table with two rows, id=100 and id=10000, a Seek on id=123 would place a Range lock on 100>id≥1000.
Reconstructing the deadlock
Because a single-row update in a MERGE statement happens in a fraction of a millisecond, and because it’s essentially a two-phase operation, we can rewrite the logic of the MERGE like this:
DECLARE @id int=500, @val int=1234;
--- THIS IS SPID 93
BEGIN TRANSACTION;
IF (EXISTS (SELECT NULL
FROM dbo.ApplicationState WITH (HOLDLOCK)
WHERE id=@id)
) BEGIN;
WAITFOR DELAY '00:00:10';
UPDATE dbo.ApplicationState
SET val=@val
WHERE id=@id;
END ELSE BEGIN;
WAITFOR DELAY '00:00:10';
INSERT INTO dbo.ApplicationState (id, val)
VALUES (@id, @val);
END;
COMMIT TRANSACTION;
I’ve added the 10-second delay to artificially slow down the query. Immediately after starting this in one connection, let’s update an entirely different row in another connection. It doesn’t matter if we use the regular MERGE statement here:
DECLARE @id int=1000, @val int=5678;
--- THIS IS SPID 94
MERGE INTO dbo.ApplicationState WITH (HOLDLOCK) AS t
USING (
VALUES (@id, @val)
) AS s(id, val) ON t.id=s.id
WHEN NOT MATCHED THEN
INSERT (id, val)
VALUES (s.id, s.val)
WHEN MATCHED THEN
UPDATE
SET t.val=s.val;
Here’s what happens in chronological order:
- SPID 93 checks dbo.ApplicationState for a row with id=500. There’s no such row, but because of the HOLDLOCK hint, it places a shared range lock for [100>id≥1000]. Shared means it’s readable to other processes, but nobody else can change what’s locked.
- SPID 94 checks dbo.ApplicationState for a row with id=1000. Again, no such row exists, so this process also places a range lock on [100>id≥1000]
- SPID 93 wants to INSERT a row with id=500, but it needs to wait on SPID 94’s range lock before proceeding.
- SPID 94 wants to INSERT a row with id=1000, and ends up waiting for SPID 93’s range lock.
- Both SPIDs are waiting on each other, and that’s the deadlock. SQL Server will (after a few seconds) terminate the process that has performed the least work by rolling back its transaction.
Msg 1205, Level 13, State 48, Line 4
Transaction (Process ID 94) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
The simplest fix
The easiest fix is not to fix the problem. Your application should retry failed transactions, and that could be the end of this.
This may be fine if you can wait for the deadlock to be resolved. But remember that there is a background process in SQL Server that looks for and kills deadlocks, and it runs every few seconds, so you could end up waiting 5-7 seconds (worst case) for your chance to retry the transaction.
The simple fix
The root cause of our deadlock was the HOLDLOCK hint. You could remove it, if you’re sure that you don’t need an isolation level this strict – say, if your application keeps track of changes, so you know that it will never try to update the same row from two connections at the same time.
This could, for instance, apply if you have one connection per user and every user has logically segmented keys in the table (user A uses id range 100-199, user B uses 200-299, etc).
Rewriting the MERGE
In our “upsert” scenario, you can rewrite the MERGE statement in one of two ways. The choice of strategy depends on if you expect mostly updates or inserts.
Expecting mainly updates
BEGIN TRANSACTION;
UPDATE dbo.ApplicationState
SET val=@val
WHERE id=@id;
IF (@@ROWCOUNT=0)
INSERT INTO dbo.ApplicationState (id, val)
VALUES (@id, @val);
COMMIT TRANSACTION;
We’ll try to update the row first, and if we don’t hit any rows, we immediately do an INSERT. Even if you place HOLDLOCK hint on the UPDATE, this pattern will not cause deadlocks like the MERGE example did!
Expecting mainly inserts
If, on the other hand, expect to have mainly insert transactions with the occasional update, we can try the other way around:
BEGIN TRANSACTION;
BEGIN TRY;
INSERT INTO dbo.ApplicationState (id, val)
VALUES (@id, @val);
END TRY
BEGIN CATCH;
UPDATE dbo.ApplicationState
SET val=@val
WHERE id=@id;
END CATCH;
COMMIT TRANSACTION;
We’ll simply try to insert the row, and if that doesn’t work, try an UPDATE.
The performance aspect
For my client workload, using SQLQueryStress, I found that rewriting a MERGE statement to an UPDATE/INSERT or INSERT/UPDATE statement both added about 20% to the execution time. That may be relevant to your workload, or it may mean absolutely nothing compared to not having to deal with deadlock issues.
I am familiar with the HOLDLOCK pros and cons, but what if I change the database locking to READ COMMITTED SNAPSHOT, do I still have to use the HOLDLOCK hint? I am trying to eliminate the massive amount of NOLOCK hints …
The reason for the HOLDLOCK hint is to mitigate a known issue with MERGE. In my specific case, that issue wasn’t a problem, but the HOLDLOCK created another issue with the range locks.
Whether RCSI will solve or create a problem for you depends on a lot of variables. As a general rule, I like to think that Snapshot isolation mostly eliminates deadlocks, but it can set you up for update conflicts instead (again, subject to your specific workload). But RCSI or not, HOLDLOCK will by definition run your statement as Serializable…
Thanks for the write up, it really is a tricky problem. Note that in the “mainly updates” alternative, you’re not locking ranges of values that don’t exist, which means that two sessions could try to insert concurrently. Adding the HOLDLOCK to the update should solve this, but I think you’re not seeing the deadlocks because the update immediately takes RangeX-X locks, while the merge takes RangeS-U locks and only upgrades to X locks if touching some rows, which allows for more concurrency but can get deadlocked. I believe you could basically add the XLOCK hint to the merge statement and get the same effect as the rewrite (with HOLDLOCK of course).
And the “mainly inserts”, in addition to the overhead of trying to insert, getting an exception and handling it and doing an update, is also dangerous as other errors could happen, so at least it should be catching the specific pk/unique violations.
Good points! In my case, the app guaratees that there are no primary key collisions. I didn’t try the XLOCK hint, but that would be a great place to start, combined with ROWLOCK, just to make sure. 😉
HI Daniel,
I am facing this deadlock issue in oracle PL/sql and oracle DB has no such hints. can you plz suggest the workaround for merge deadlock issue fix.
I don’t know enough about Oracle to help you with this. I would recommend you to check out dba.stackexchange.com or google for it.
ok..Thank you for your reply!
I believe a HOLDLOCK, UPDLOCK hint will prevent this deadlock.
I would be curious to see how this would improve deadlock problems in practice. I imagine that the serializable isolation level that follows from the HOLDLOCK would already have placed the locks that the UPDLOCK would.
No, it seems it doesn’t, it will only take an IU lock, see https://docs.microsoft.com/en-us/archive/blogs/dbrowne/why-is-tsql-merge-failing-with-a-primary-key-violation-isnt-it-atomic