Performance tuning the other day, I was stumped by a query plan I was looking at. Even though I had constructed a covering index, I was still getting a Key Lookup operator in my query plan. What I usually do when that happens is to check the operator’s properties to see what its output columns are, so I can include those columns in my covering index.
Here’s the interesting thing: there weren’t any output columns. What happened?
So this is what I expected… |
… but this is what I got |
Notice how my Key Lookup (the one on the right) completely lacks the “Output List” section, implying that it doesn’t actually look anything up.
What Key Lookup actually does
 When your query allows for it, it can be considerably cheaper to read from a non-clustered index than from the clustered index. Reading less is usually good for performance, and so SQL Server will often choose a non-clustered index over the clustered one. This is particularly true if the non-clustered index is sorted in a more suitable way with regards to your query needs.
When your query allows for it, it can be considerably cheaper to read from a non-clustered index than from the clustered index. Reading less is usually good for performance, and so SQL Server will often choose a non-clustered index over the clustered one. This is particularly true if the non-clustered index is sorted in a more suitable way with regards to your query needs.
In some cases, SQL Server will decide on using a non-clustered index even when it doesn’t contain all the columns you need from the table. In those cases, those columns can be retrieved using Key Lookups. But this is only a good idea if your non-clustered index scan/seek returns just a handful of rows, because Key Lookups are not scans or seeks/range lookups in a regular sense – they are “needle point” lookups that happen for each and every row, making them potentially very, very expensive.
Every non-clustered index row contains a clustering key, so you can fetch a specific row from the clustered index (the table itself), and this is what the Key Lookup operator does.
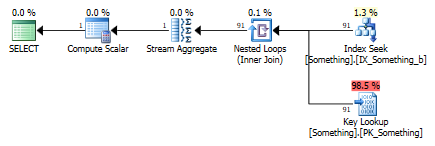
Here’s a query that uses a Key Lookup. The non-clustered index is in the top-right corner, and for each row from the non-clustered index, the Nested Loop operator will call a Key Lookup from the clustered index (lower-right).
Reproducing the issue
Here’s a test table to illustrate what happened:
CREATE TABLE dbo.Something ( i int NOT NULL, a int NOT NULL, b int NOT NULL, CONSTRAINT PK_Something PRIMARY KEY CLUSTERED (i) ); CREATE UNIQUE INDEX IX_Something_a ON dbo.Something (a); CREATE UNIQUE INDEX IX_Something_b ON dbo.Something (b);
Adding some data to the table,
INSERT INTO dbo.Something (i, a, b) SELECT TOP (100000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS i, ROW_NUMBER() OVER (ORDER BY (SELECT NULL))*10 AS a, ROW_NUMBER() OVER (ORDER BY (SELECT NULL))*11 AS b FROM sys.columns AS x CROSS JOIN sys.columns AS y CROSS JOIN sys.columns AS z;
Here’s the problematic query:
SELECT COUNT(*) FROM dbo.Something WHERE b>=200000 AND b<201000 AND a<1000000;
Now, any of the three indexes on the table could theoretically be used to solve the query, but none of them are perfect:
- Scanning the clustered index is not ideal since we’re actually looking for less than 100 rows out of the 100 000 in the table.
- An index seek on IX_Something_a will return rows where “a<1000000”, but this means nearly all of the rows. That would result in 100 000 Key Lookups to get the “b” column. This is by far the worst solution.
- An index seek on IX_Something_b will return rows where “b BETWEEN 200000 AND 201000”, which is about 100 rows. That means 100 Key Lookups to get the “a” column for those rows, which is manageable.
When evaluating the efficiency (the cost) of each alternative, SQL Server uses statistics to make an estimate of the number of rows each seek or scan will return. In this case, it’ll most probably go with IX_Something_b, even though that index does not cover the “a” column. This means that we’ll have to perform about 100 Key Lookups to verify that “a<1000000” for those rows where the “b” predicate is satisfied.
Conclusion, TL;DR
The Key Lookup doesn’t actually retrieve the “a” column – it doesn’t add the “a” column to the data stream. Instead, it functions as filter in conjuction with the Nested Loop join, so it filters out rows where the “a” condition is not satisfied.
So “a” is not an output column, it’s just a predicate. The output column is really the clustering key, “i”, which is used by the Nested Loop join operator, but you can’t see that in the query plan for some reason.
