Do you ever compare the values of a lot of columns in two tables? Sure you do. Like, for instance, in a cross update, when you need to figure out which rows you should actually update. But it gets worse if the columns are nullable. The fact that any value could potentially be NULL vastly complicates the comparison and might wreak havoc not only on your code but also on your query performance.
But there’s hope.
Ok, so you’d love to just do this:
FROM #a AS a
INNER JOIN #b AS b ON a.pk=b.pk
WHERE a.x!=b.x OR
a.y!=b.y OR
a.z!=b.z;
But this won’t work in ANSI SQL, because NULL values cannot be compared. This means that two NULL values aren’t the same, nor are they different. You could make this work by setting ANSI_NULLS OFF, but that breaks a lot of other things and is generally considered ugly.
So this is what you’ll probably end up doing:
FROM #a AS a
INNER JOIN #b AS b ON a.pk=b.pk
WHERE a.x!=b.x OR
a.x IS NULL AND b.x IS NOT NULL OR
a.x IS NOT NULL AND b.x IS NULL OR
a.y!=b.y OR
a.y IS NULL AND b.y IS NOT NULL OR
a.y IS NOT NULL AND b.y IS NULL OR
a.z!=b.z OR
a.z IS NULL AND b.z IS NOT NULL OR
a.z IS NOT NULL AND b.z IS NULL;
Now, if those two tables contain about a million rows each, your query plan will look like this:
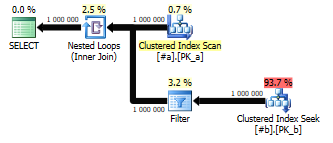
Because we’ve added OR conditions into the mix, we’re forced to use the Nested Loop join, which loops over table B for every single row in A. That’s a lot of index scans and it comes with a hefty price tag.
Here’s an absolutely eye-watering beautiful pattern that I found on the Interwebs (though I forgot where) the other day.
FROM #a AS a INNER JOIN #b AS b ON a.pk=b.pk WHERE NOT EXISTS ( SELECT a.x, a.y, a.z INTERSECT SELECT b.x, b.y, b.z);
Take a moment to admire the ingenious simplicity. Like I said, equality comparisons (=) won’t work between two NULL values, but UNION, EXCEPT and INTERSECT do. And this query contains only equi-joins (join conditions where two columns should be equal to each other), which means you can choose the best join operator for the task – in this case, we got the super-fast MERGE JOIN because the two tables have aligned clustered indexes.
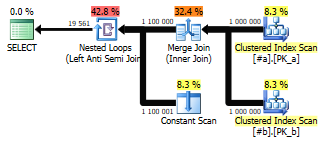
Reading the plan from right-to-left, both tables are joined using a Merge Join, then for each row in the joined dataset, x, y and z from each side are intersected. An “anti-semi join” returns unmatched rows, which is what we want here.
This is T-SQL art, I have no more words.
Except, perhaps, I wish I would have thought of it first.
http://sqlblog.com/blogs/paul_white/archive/2011/06/22/undocumented-query-plans-equality-comparisons.aspx
This is an excellent read, as is the blog post that Hans has referenced
This was awesome sir.
Great article! Although, Paul White’s article (linked-to by Hans’ “though” above) from 5 years prior does offer some interesting explanation as to why / how it works.
We have numerous code in SPs that check for and logs changes to Column values when updating a Row. Based on your article, I derived the following for equality comparisons of Nullable values while treating a Null as a comparable value.
”
declare @a int = null
declare @b int = 1
–Equality comparisons treating Nulls as comparable values:
–If (@a = @b), …
if exists (select @a intersect select @b) select ‘true’ as [=] else select ‘false’ as [=]
–If (@a != @b), …
if not exists (select @a intersect select @b) select ‘true’ as [!=] else select ‘false’ as [!=]
“