You may have discovered that the use of DISTINCT is not supported in windowed functions. A query that uses a distinct aggregate in a windowed function,
SELECT COUNT(DISTINCT something) OVER (PARTITION BY other) FROM somewhere;
will generate the following error message:
Msg 10759, Level 15, State 1, Line 1 Use of DISTINCT is not allowed with the OVER clause.
There are, however, a few relatively simple workarounds that are suprisingly efficient.
Some sample data
Here’s a temp table with a sample of a million rows to work with:
CREATE TABLE #CountDistinct (
Part int NOT NULL,
CountCol int NOT NULL,
ID int NOT NULL,
PRIMARY KEY CLUSTERED (Part, CountCol, ID)
);
--- Insert sample data:
INSERT INTO #CountDistinct (Part, CountCol, ID)
SELECT TOP(1000000)
_row-_row%100, _row%200-_row%20, _row
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS _row
FROM sys.columns AS c1
CROSS JOIN sys.columns AS c2
CROSS JOIN sys.columns AS c3
) AS x;
“Part” is our partitioning column, “CountCol” is the column that we’ll want to perform the distinct aggregates on, and ID is an identity column. The clustered primary key should be optimal for this type of query.
COUNT(DISTINCT ..) OVER ()
Probably the most common distinct aggregate is COUNT(DISTINCT). In some respects, it’s similar to the windowed function DENSE_RANK(). DENSE_RANK(), as opposed to ROW_NUMBER(), will only increment the row counter when the ordering column(s) actually change from one row to the next, meaning that we can use DENSE_RANK() as a form of windowed distinct count:
SELECT Part, CountCol, ID, --- Windowed MAX() on the DENSE_RANK() column: MAX(_dense_rank) OVER ( PARTITION BY Part) AS CountDistinct FROM ( SELECT *, --- DENSE_RANK() on the CountCol column: DENSE_RANK() OVER ( PARTITION BY Part ORDER BY CountCol) AS _dense_rank FROM #CountDistinct ) AS sub;
The query generates the following plan:
![]()
The DENSE_RANK() calculation appears as Segment and Sequence Project (top-center). The windowed MAX() manifests itself as a Table Spool and Stream Aggregate. The query is non-blocking and requires no memory grant, making it extremely efficient.
SUM(DISTINCT ..) OVER ()
You could construct the equivalent of a SUM(DISTINCT) query in a similar fashion:
SELECT Part, CountCol, ID, --- Windowed SUM() of the calculated column: SUM(_countcol) OVER ( PARTITION BY Part) AS SumDistinct FROM ( SELECT *, --- If this is the first row of the --- partition and CountCol, add CountCol --- to the tally: (CASE WHEN ROW_NUMBER() OVER ( PARTITION BY Part, CountCol ORDER BY ID)=1 THEN CountCol ELSE 0 END) AS _countcol FROM #CountDistinct ) AS sub;
The query plan also looks similar to the previous example:
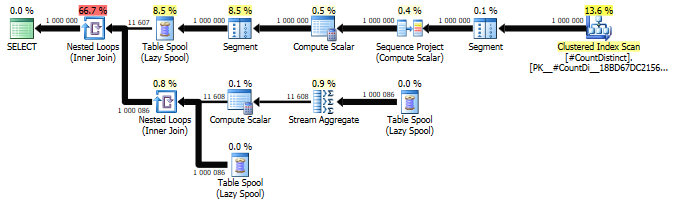
Loved the sum of distinct windowed values..solved my problem. Thanks
Glad to hear it!
Have a great weekend!
Hello, is it possible to accomplish this with a trailing 12 month distinct sum using a window function. Rolling 12 month like:
2019:01 – 2019:12 (Distinct sum within the period)
2019:02 – 2020:01 (Distinct sum within the period)
2019:03 – 2020:02 (Distinct sum within the period)
Yeah, that’s a little trickier than I can fit in a comment. 🙂
If you find the time to do it and are up for it, please get back to me with the solution. It feels like I’ve been looking everywhere for an answer, but to no avail.