Windowed functions are a powerful feature of T-SQL, allowing you to perform advanced aggregates. They provide a very efficient way of doing this as soon as you just get the hang of the OVER() clause.
OVER()
The common denominator for every windowed function i T-SQL is the OVER() clause. OVER() is added to any aggregate function that you want to turn into a windowed function, as well as those that are always windowed functions. The OVER() clause can contain PARTITION BY and ORDER BY or both, depending on the function.
You can use OVER() on all aggregate functions except GROUPING(), GROUPING_ID() and COUNT(DISTINCT).
PARTITION BY, and why it’s not the same as GROUP BY
Both standard aggregate functions and windowed aggregates using the OVER() clause perform aggregations. The main difference, however, is that whereas a standard aggregation uses a GROUP BY clause that is common to all of the aggregations, PARTITION BY allows you to define the GROUP BY expression for each aggregate function separately.
The following example will aggregate the minimum and maximum values for each currency code using aggregate functions and a GROUP BY:
SELECT ToCurrencyCode, MIN(EndOfDayRate) AS min_Rate, MAX(EndOfDayRate) AS max_Rate FROM Sales.CurrencyRate GROUP BY ToCurrencyCode;
Now, if you add the date column to the GROUP BY, this would be the equivalent of removing GROUP BY alltogether, because the GROUP BY would then encompass the entire primary key of the table. This effectively eliminates the MIN() and MAX() functions – those columns will always show each day’s rate:
SELECT CurrencyRateDate, ToCurrencyCode, MIN(EndOfDayRate) AS min_EODRate, MAX(EndOfDayRate) AS max_EODRate FROM Sales.CurrencyRate GROUP BY CurrencyRateDate, ToCurrencyCode;
So the problem is that you can’t get each day’s rates and the minimum and maximum rates over time in the same recordset without messing with subqueries and potentially killing performance. So here’s where we’ll use OVER() to define the grouping columns for each individual aggregate column:
SELECT CurrencyRateDate, ToCurrencyCode,
EndOfDayRate AS EODRate,
MIN(EndOfDayRate) OVER (
PARTITION BY ToCurrencyCode) AS min_EODRate,
MAX(EndOfDayRate) OVER (
PARTITION BY ToCurrencyCode) AS max_EODRate
FROM Sales.CurrencyRate;
So the EODRate column is row-for-row the daily rate from Sales.CurrencyRate, without any aggregate (note that we’ve removed the GROUP BY!)
The MIN() and MAX() columns are calculated as windowed aggregates over all rows with the same FromCurrencyCode and ToCurrencyCode.
In conclusion: GROUP BY applies to all columns and requires all columns to either be in an aggregate function or in the GROUP BY clause. PARTITION BY defines an individual “GROUP BY” for each function.
ROW_NUMBER(), RANK() and DENSE_RANK()
There are a number of ranking and ordering functions available as windowed functions. This means that they also use the OVER() clause, but in addition to the (optional) PARTITION BY keyword, they also work with ORDER BY, still within the OVER() clause. Here’s how they work:
- ROW_NUMBER() is the simplest one, returning a running row number, starting at 1 and incrementing by 1 for each row. If you use PARTITION BY, the counter will start over at 1 for each “partition”.
- RANK() works like ROW_NUMBER(), except it employs a ranking function similar to what you would see in sporting results, with “shared” ranks.
- DENSE_RANK() works like RANK(), but distincts the values before ranking them.
The following example will demonstrate how the three work:
SELECT x,
ROW_NUMBER() OVER (ORDER BY x),
RANK() OVER (ORDER BY x),
DENSE_RANK() OVER (ORDER BY x)
FROM dbo.dummyTable
 Using ROW_NUMBER(), RANK() and DENSE_RANK() with DISTINCT resultsets
Using ROW_NUMBER(), RANK() and DENSE_RANK() with DISTINCT resultsets
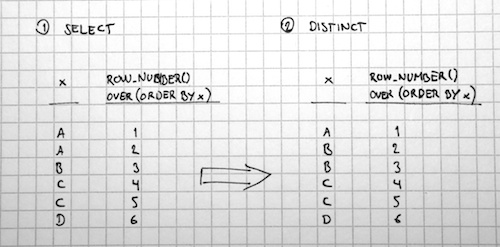
If you have a DISTINCT result set with windowed functions, you need to take into consideration the effect of how the logical processing order works. As you may recall, SELECT is performed before DISTINCT, which means that the windowed function will be calculated before the result set it DISTINCT’ed. This means that the following statement will return the same result sets whether you use DISTINCT or not:
SELECT DISTINCT x, ROW_NUMBER() OVER (ORDER BY x) FROM dbo.dummyTable
The reason is, of course, that the ROW_NUMBER() column is calculated first, and because it contains a unique number on every row, there are no duplicate rows to remove using the DISTINCT operator.
 However, the RANK() and DENSE_RANK() functions return unique values for each x. This makes them better suited for use with a DISTINCT keyword.
However, the RANK() and DENSE_RANK() functions return unique values for each x. This makes them better suited for use with a DISTINCT keyword.
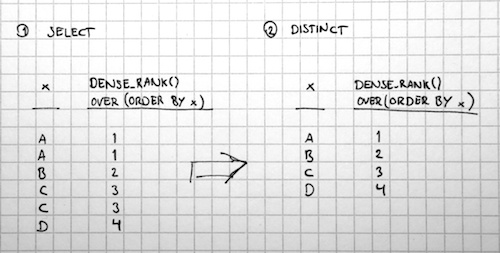 In other words, if you want a row numbering function to work with a DISTINCT query, you’re better off using DENSE_RANK().
In other words, if you want a row numbering function to work with a DISTINCT query, you’re better off using DENSE_RANK().
SELECT DISTINCT x, DENSE_RANK() OVER (ORDER BY x) FROM dbo.dummyTable
SQL Server 2012: Sliding window functions with LEAD() and LAG()
As of SQL Server 2012, there are two new functions called LEAD() and LAG(), among other new, practical windowed functions. These functions return the “next” and “previous” rows respectively from the result set. But they will be the subject of another post entirely.
As usual, if you have any questions or ideas, let me know!
11 comments