I just remembered a pretty common data challenge the other day. Suppose you have a number of tables, all with similar information in them. You want to union their contents, but you need to prioritize them, so you want to choose all the rows from table A, then rows from table B that are not included in A, then rows from C that are not included in A or B, and so on.
This is a pretty common use case in data cleansing or data warehousing applications. There are a few different ways to go about this, some more obvious than others.
For the sake of simplicity, I’ll assume that our example data has a clustered index on the “primary key” that we want to use to determine which rows have already been included in the set – in our example, the primary key is (FirstName, LastName). The data I’m using is a fictional example, but here’s the jist:
- #Employees has about 33 000 rows.
- #Customers has about 44 000 rows.
- #Passengers has about 500 000 rows.
The data is constructed in a way that these queries should return 530 000 rows, so we’re looking at some overlap but far from totally overlapping rows.
The terrible one
At first glance, particularly if you’re not a seasoned query tuner, you may try to write the query just the way you imagine it.
--- Start off with all employees: SELECT e.FirstName, e.LastName, e.EmploymentDate, NULL AS CreditLimit, 1 AS [Source] FROM #Employees AS e UNION ALL --- .. then all customers that are not employees: SELECT c.FirstName, c.LastName, NULL AS EmploymentDate, c.CreditLimit, 2 AS [Source] FROM #Customers AS c WHERE NOT EXISTS (SELECT NULL FROM #Employees AS e WHERE e.FirstName=c.FirstName AND e.LastName=c.LastName) UNION ALL --- .. finally all passengers that are not customers and not employees: SELECT p.FirstName, p.LastName, NULL AS EmploymentDate, NULL AS CreditLimit, 3 AS [Source] FROM #Passengers AS p WHERE NOT EXISTS (SELECT NULL FROM #Customers AS c WHERE c.FirstName=p.FirstName AND c.LastName=p.LastName) AND NOT EXISTS (SELECT NULL FROM #Employees AS e WHERE e.FirstName=p.FirstName AND e.LastName=p.LastName);
You can see how this gets ugly in a hurry. Imagine if you had five or even ten source tables, or if some of those were even views. Anyway, this query clocks in at a pretty impressive 6.5 CPU seconds with about 3000 reads. You can see from the query plan that the large number of reads is because we scan #Passengers once, #Customers twice and #Employees three times:
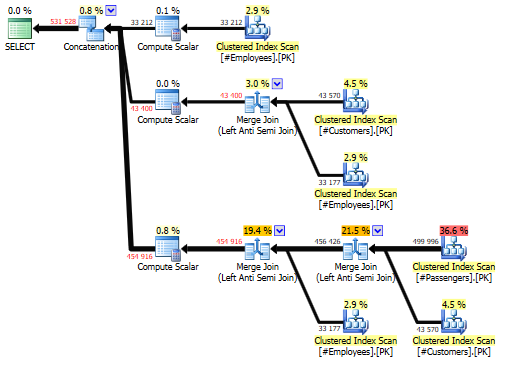
Our saving grace in this example is the fact that all three tables have identical clustered indexes, which allows for a very efficient Merge Join operator. The fact that we have Merge Joins everywhere is also the reason this plan doesn’t require a memory grant.
In a more realistic, more heterogenous example, performance would probably be a lot worse.
FULL JOINing all of the sources
“Hah!” I hear you say, “this is a regular FULL JOIN between the three tables.” It could be written like this:
SELECT (CASE x.[Source] WHEN 1 THEN e.FirstName WHEN 2 THEN c.FirstName WHEN 3 THEN p.FirstName END) AS FirstName,
(CASE x.[Source] WHEN 1 THEN e.LastName WHEN 2 THEN c.LastName WHEN 3 THEN p.LastName END) AS LastName,
e.EmploymentDate,
c.CreditLimit,
x.[Source]
FROM #Employees AS e
FULL JOIN #Customers AS c ON
c.FirstName=e.FirstName AND
c.LastName=e.LastName
FULL JOIN #Passengers AS p ON
p.FirstName IN (c.FirstName, e.FirstName) AND
p.LastName IN (c.Lastname, e.LastName)
CROSS APPLY (
VALUES ((CASE WHEN e.LastName IS NOT NULL THEN 1
WHEN c.LastName IS NOT NULL THEN 2
WHEN p.LastName IS NOT NULL THEN 3 END))
) AS x([Source]);
You can replace the CASE expressions with the more readable COALESCE() function, but that can produce inaccurate results if one or more of your columns are nullable.
To my surprise, this query didn’t even complete within five minutes. The execution plan gives us a pretty good insight into why that is:
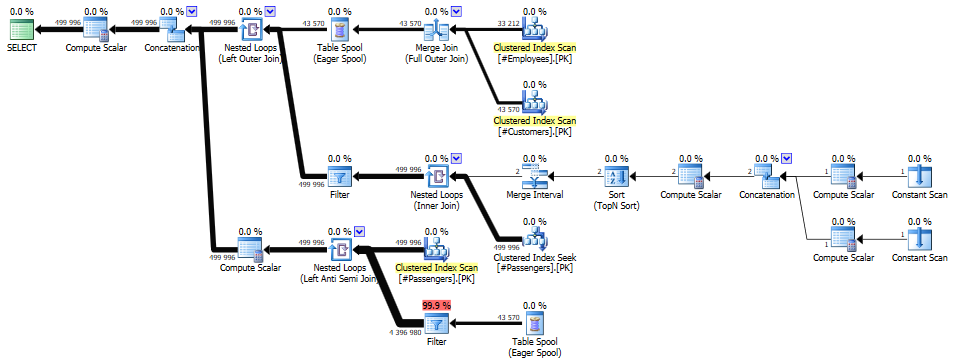
Joining #Employees and #Customers is still very efficient, using a Merge Join, but from there on things get a bit funky. The results are stored in a Table Spool, which is then queried once for each and every row in #Passengers. You can do the math on this one.
The temp table
Or you could just create a temp table and insert each source table, one at a time. This splits the operation into controlled batches, but on the flip side, it hits the temp table multiple times (once for each batch). Here’s how that query could look (without the code for actually creating the temp table).
--- First batch, doesn't have to join the target table: INSERT INTO #Results (FirstName, LastName, EmploymentDate, [Source]) SELECT FirstName, LastName, EmploymentDate, 1 AS [Source] FROM #Employees; --- Second batch: INSERT INTO #Results (FirstName, LastName, CreditLimit, [Source]) SELECT c.FirstName, c.LastName, c.CreditLimit, 2 AS [Source] FROM #Customers AS c WHERE NOT EXISTS ( SELECT NULL FROM #Results AS r WHERE c.FirstName=r.FirstName AND c.LastName=r.LastName); --- Third batch: INSERT INTO #Results (FirstName, LastName, [Source]) SELECT p.FirstName, p.LastName, 3 AS [Source] FROM #Passengers AS p WHERE NOT EXISTS ( SELECT NULL FROM #Results AS r WHERE p.FirstName=r.FirstName AND p.LastName=r.LastName);
I’ve added the same clustered index (LastName, FirstName) to the temp table as for the three source tables, allowing for a smooth Merge Join. Here’s how the resulting query plan looks:
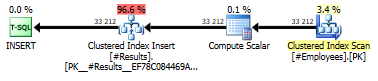
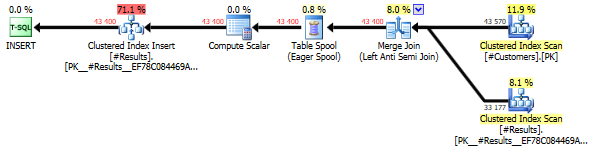

Note that on the third plan, the volumes are large enough to create a parallel plan, which generates a memory grant. If you’re short on memory, you could add a MAXDOP=1 hint to the third batch, obviously at the cost of lower performance.
Seeing as you’re doing large bulk inserts, you might even be able to make this a minimally logged operation if the stars align in your favor.
This query came in at 16 CPU seconds (13 actual seconds) and a whopping 1.8 million reads. Parallelism adds to the large I/O count as well.
UNION ALL and a window function
You could union all three sets and use a window function to determine which one has the highest priority.
WITH cte AS ( --- First set: SELECT FirstName, LastName, EmploymentDate, NULL AS CreditLimit, 1 AS [Source] FROM #Employees UNION ALL --- Second set: SELECT FirstName, LastName, NULL, CreditLimit, 2 AS [Source] FROM #Customers UNION ALL --- Third set: SELECT FirstName, LastName, NULL, NULL, 3 AS [Source] FROM #Passengers) SELECT FirstName, LastName, EmploymentDate, CreditLimit, [Source] FROM ( --- Determine ranking in case of duplicates: SELECT *, ROW_NUMBER() OVER (PARTITION BY LastName, FirstName ORDER BY [Source]) AS _rownum FROM cte ) AS sub --- Filter only the top-ranked rows: WHERE sub._rownum=1;
Myself, I think this is probably the most elegant solution. You’ll agree when you see the plan:
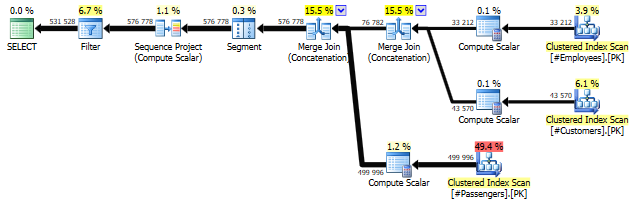
Two Merge Join (Concatenation) operators, no sorting, no hashing, no memory grant, this query clocks in at 8.2 CPU seconds. Though not quite as fast as “the terrible one”, it does less I/O work with just 2300 reads and just a single scan for each source table. This is one very efficient query.
Conclusion
In my tests, “the terrible” solution turned out to be the fastest, which is a bit counter-intuitive. However, I’m pretty sure that this comes down to scale: if you add more sources, 4, 5, 6, even 10, it’ll probably bog down completely.
The union all/window function pattern, on the other hand, will scale very well, particularly if the indexes are aligned. This will normally be my go-to pattern.
The full join method looked smart in theory, but turned out to be an awful performer in this case. As with the others, a different distribution of rows (fewer rows in #Passengers, in this case) would have made a notable difference.
The temp table solution has merit in situations where you want a little more control and don’t want to blow up your plan with lots and lots of source tables and operators. This is particularly true if your indexes aren’t perfectly aligned as they are here, or if you’re using views as data sources. Many database professionals will argue that a temp table in and of itself is a performance bottleneck, and this may well be true – you might actually want to create a regular table for this purpose.
If anything, “it depends” is still true – there are a number of patterns, but there’s no guarantee any one of them will fit everyone.
Another approach may be to use EXCEPT. (And it makes handling NULL values easier too).
Agree, it’s a very readable syntax and it generates a possibly even better plan, but it matches the entire row, not just the primary key columns, so in this example it would have generated duplicates.
what about cascading the “ugly” solution
select * from table3
union all
(
select * from table 2
union all
select * from table1 where not exists (select 1 from table2 ….)
)
where not exists (select 1 from table3 )…. ..
Yikes. 🙂
Yeah, I’ve seen this done in production a few times.. You’ll probably see loads and loads and loads of joins, particularly when you scale the query by adding more sources.