Few things deserve the attention of a long rant as much as unneccessarily complicated syntaxes. When you want to achieve something that is clearly defined and supported, but you have to look up the the syntax. PIVOT and UNPIVOT are examples of such features, and in this case, I’ll even show you a more well-performing alternative.
A more detailed description of what pivoting is and when it’s applicable is beyond the scope of this post, but if in doubt, ask any Excel user you may know.
Setting up
We’re going to need some sample data to play around with, preferably enough to cause SQL Server to parallellize the query plan if possible. This script will create a temp table with about two million rows.
CREATE TABLE #unpivoted ( ColName char(1) NOT NULL, RowName char(1) NOT NULL, Amount numeric(10, 2) NOT NULL ); CREATE CLUSTERED INDEX #unpivoted_ix ON #unpivoted (ColName, RowName); --- A single row.. INSERT INTO #unpivoted (ColName, RowName, Amount) SELECT CHAR(65+FLOOR(RAND(CHECKSUM(NEWID()))*10)), CHAR(65+FLOOR(RAND(CHECKSUM(NEWID()))*4)), ROUND(1000.0*RAND(CHECKSUM(NEWID())), 2); --- ... which doubles over and over: WHILE (@@ROWCOUNT<1000000) INSERT INTO #unpivoted (ColName, RowName, Amount) SELECT CHAR(65+FLOOR(RAND(CHECKSUM(NEWID()))*4)), CHAR(65+FLOOR(RAND(CHECKSUM(NEWID()))*10)), ROUND(1000.0*RAND(CHECKSUM(NEWID())), 2) FROM #unpivoted;
PIVOT out of the box
Here’s how the PIVOT command looks.
SELECT p.RowName, p.A, p.B, p.C, p.D FROM #unpivoted AS x PIVOT ( SUM(x.Amount) FOR x.ColName IN (A, B, C, D) ) AS p ORDER BY p.RowName;
And the query plan looks like this:
![]()
Right-to-left, the query performs a scan of the table, aggregates this data with a Hash Match aggregate, and sorts the stream in order to be suitable for a Stream Aggregate. The scan and the hash match are the expensive operations here. On my system, this query consistently completes in about 1.7 seconds.
Do-it-yourself PIVOT
However, anytime I need to pivot anything myself, I tend to prefer the following approach mostly because I feel I have more control over it, the syntax is easier to remember (I know, very subjective), and it’s about as easy to read as the original.
SELECT RowName, SUM((CASE WHEN ColName='A' THEN Amount ELSE 0.0 END)) AS A, SUM((CASE WHEN ColName='B' THEN Amount ELSE 0.0 END)) AS B, SUM((CASE WHEN ColName='C' THEN Amount ELSE 0.0 END)) AS C, SUM((CASE WHEN ColName='D' THEN Amount ELSE 0.0 END)) AS D FROM #unpivoted GROUP BY RowName ORDER BY RowName;
You can already tell from the code that the query plan should look very similar indeed. And it does. See if you can spot the difference:
![]()
Did you notice the Compute Scalar operator that moved from the serial zone to the parallel? The operator itself hardly carries any cost at all, but anything in the serial zone will adversely affect the performance of the entire query, because at that point, all those parallel streams have been merged together into a single stream.
As a rule of thumb, the smaller that last serial zone is, the better your query is going to perform overall.
Speaking of performance, this “manual pivot” query performs about 25% better than the traditional PIVOT. The I/O reads and the estimated cost are both exactly the same, so I’ll chalk it up to the smaller serial zone.
UNPIVOT
Let’s set up some test data to try out UNPIVOT. This should give us some 300 000 pivoted rows to play with:
SELECT RowName, SUM((CASE WHEN ColName='A' THEN Amount ELSE 0.0 END)) AS A, SUM((CASE WHEN ColName='B' THEN Amount ELSE 0.0 END)) AS B, SUM((CASE WHEN ColName='C' THEN Amount ELSE 0.0 END)) AS C, SUM((CASE WHEN ColName='D' THEN Amount ELSE 0.0 END)) AS D INTO #pivoted FROM #unpivoted GROUP BY RowName ORDER BY RowName; CREATE CLUSTERED INDEX #pivoted_ix ON #pivoted (RowName); INSERT INTO #pivoted (RowName, A, B, C, D) SELECT RowName, A, B, C, D FROM #pivoted; WHILE (@@ROWCOUNT<100000) INSERT INTO #pivoted (RowName, A, B, C, D) SELECT RowName, A, B, C, D FROM #pivoted;
To UNPIVOT these rows, we would use something like this:
SELECT u.ColName, u.RowName, u.Amount FROM #pivoted AS p UNPIVOT (Amount FOR ColName IN (p.A, p.B, p.C, p.D) ) AS u;
This query produces 1.3 million rows in about 1.5 seconds. Here’s the query plan:

Do-it-yourself UNPIVOT
Yes, of course you can do your own UNPIVOT, and it’s a really neat solution as well, based on the use of CROSS APPLY.
SELECT u.ColName, p.RowName, u.Amount
FROM #pivoted AS p
CROSS APPLY (
VALUES ('A', p.A),
('B', p.B),
('C', p.C),
('D', p.D)
) AS u(ColName, Amount);
CROSS APPLY creates a nested loop join, the SQL Server-equivalent of a for-each loop. For each row in #pivoted, we create four rows in the CROSS APPLY, and because those rows are entirely constructed from constants and values from #pivoted, the result is just a constant scan, and thus very efficient. Here’s the query plan:
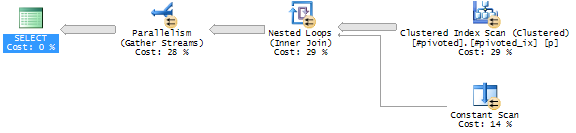
This plan excludes the Compute Scalar and Filter operators that we saw in the UNPIVOT plan, and it also parallellizes very neatly (no serial zone at all). The estimated cost is slightly lower, while both queries perform a single scan of the table. When we ramp up the data volumes, the UNPIVOT query also parallelizes, but the performance difference becomes more visible: there’s about a 10% performance gain in the home-grown version over UNPIVOT.
Bottom line
I personally really dislike the PIVOT and UNPIVOT constructs, because their syntaxes are unintuitive and hard to remember. Just for fun, I thought I’d build my own equivalents, and it turns out that SQL Server is actually better at optimizing those than the original PIVOT and UNPIVOT, which is a positive surprise to me.
Does it still apply when you have to pivot out to 130 columns?
Yes, I’m doing 150 columns
Whoah. No idea, but by all means, go ahead and try. 🙂
It represents lots of non aggregate-able columns relating to data points. Easy to manage as rows – Users love them as rows.
Do you know if PIVOT utilises the Columnstore indexes significantly?
Haven’t tried it. Pivot really breaks down to a bunch of query plan operators, so it depends on your query. I would say that there’s a good chance you might benefit from a columstore index, particularly if you have a large number of rows.
Thanks for your prompt follow up – Interesting article.
No problem, glad you liked it! 🙂
How could all this time pass and nobody noticed the fact that by leaving out ‘WHERE Amount IS NOT NULL’ your query doesn’t produce the same results as the UNPIVOT operator. Obviously that explains why your execution plan doesn’t include a filter that UNPIVOT has.
To be honest, I can’t figure out what computation the COMPUTE SCALER (also missing) is doing so I’m not sure you’ve lost anything other than some overhead by eliminating that.
I just noticed that in addition to my prior comment
SUM((CASE WHEN ColName=’A’ THEN Amount ELSE 0.0 END)) AS A,
should be
SUM((CASE WHEN ColName=’A’ THEN Amount END)) AS A,
in order to simulate what UNPIVOT does. Otherwise the WHERE clause I mentioned won’t find anything.
My results (years later): 10x faster with this method against a table that has 15+ million rows into 150 columns. Thanks!
That’s amazing. I’m not even upset about a query that returns 150 columns. 😃