I personally find the UNPIVOT syntax in T-SQL a bit unwieldy and not entirely easy to read. In this article, I’m going to show you an alternative way to perform UNPIVOT, using the CROSS APPLY operator.
In this article, I’ll be using the AdventureWorks demo database. The task at hand is to “unpivot” the following recordset, so each type of amount ends up on one row.
SELECT p.ProductID, p.ProductNumber, p.Color, p.SafetyStockLevel, p.ReorderPoint, p.StandardCost, p.ListPrice, p.[Weight] FROM Production.Product AS p;
What we want to end up with is a recordset where each product has five rows, one for each of the columns SafetyStockLevel, ReorderPoint, StandardCost, ListPrice and Weight.
Using UNION ALL
Here’s the good old brute-force approach, using UNION ALL:
SELECT p.ProductID, p.ProductNumber, p.Color,
'SafetyStockLevel' AS [key], p.SafetyStockLevel AS val
FROM Production.Product AS p
UNION ALL
SELECT p.ProductID, p.ProductNumber, p.Color,
'ReorderPoint' AS [key], p.ReorderPoint AS val
FROM Production.Product AS p
UNION ALL
SELECT p.ProductID, p.ProductNumber, p.Color,
'StandardCost' AS [key], p.StandardCost AS val
FROM Production.Product AS p
UNION ALL
SELECT p.ProductID, p.ProductNumber, p.Color,
'ListPrice' AS [key], p.ListPrice AS val
FROM Production.Product AS p
UNION ALL
SELECT p.ProductID, p.ProductNumber, p.Color,
'Weight' AS [key], p.[Weight] AS val
FROM Production.Product AS p;
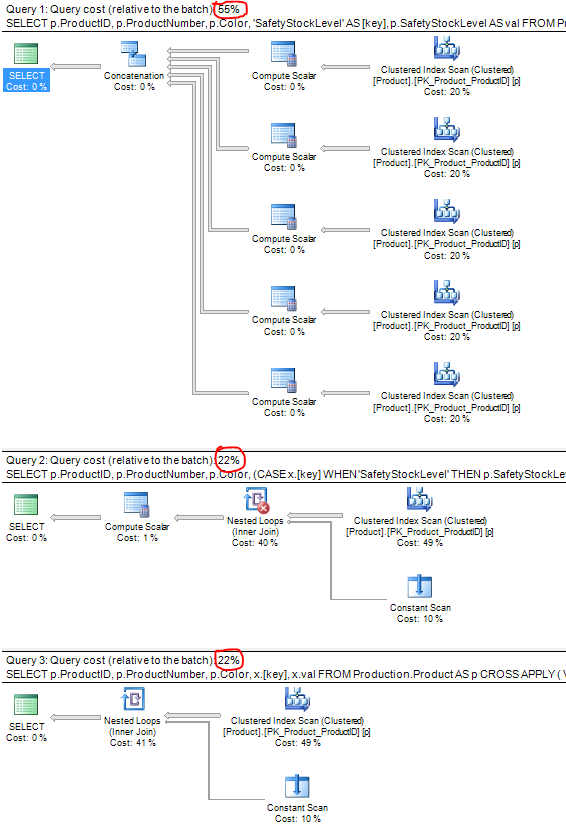
This code isn’t very pretty, and if you review the query plan (see the bottom of this article), it actually scans the base table once for each column value and then UNIONs all those result sets together, which is potentially very costly if you have a large number of rows in the table or a large number of values to unpivot.
Using a CROSS JOIN
The following code performs a CROSS JOIN with a virtual table of keys to the base table. The CROSS JOIN will also create a cartesian join, which is what we want, but it will only scan the base table once, which saves us a lot of I/O.
SELECT p.ProductID, p.ProductNumber, p.Color, (CASE x.[key]
WHEN 'SafetyStockLevel' THEN p.SafetyStockLevel
WHEN 'ReorderPoint' THEN p.ReorderPoint
WHEN 'StandardCost' THEN p.StandardCost
WHEN 'ListPrice' THEN p.ListPrice
WHEN 'Weight' THEN p.[Weight] END) AS val
FROM Production.Product AS p
CROSS JOIN (
VALUES ('SafetyStockLevel'),
('ReorderPoint'),
('StandardCost'),
('ListPrice'),
('Weight')
) AS x([key]);
Still, we have to list all the columns explicitly, both in the CASE expression and in the subquery. Incidentally, the VALUES() construct evaluates the same was as if you would write the five values in a SELECT with UNION ALLs – it’s just less work typing and easier to read.
Using CROSS APPLY
Now, if we use CROSS APPLY, we can create the same type of cartesian join as with the CROSS JOIN, but within the CROSS APPLY we can reference columns from the “outside”, which means we can eliminate the bulky CASE expression alltogether.
SELECT p.ProductID, p.ProductNumber, p.Color, x.[key], x.val
FROM Production.Product AS p
CROSS APPLY (
VALUES ('SafetyStockLevel', p.SafetyStockLevel),
('ReorderPoint', p.ReorderPoint),
('StandardCost', p.StandardCost),
('ListPrice', p.ListPrice),
('Weight', p.[Weight])
) AS x([key], val);
On datatype conversions
With all three of these solutions, an implicit datatype conversion is performed, because the different value columns have different datatypes. The output datatype is determined by “data type precedence“, so if you want a specific output datatype, make sure you make an explicit conversion (for instance, within the CROSS APPLY) to be sure.
Performance
The query plan clearly shows the difference in performance impact between the three different solutions. Notice that the cost of the first (the UNION ALL) solution lies in the multiple scans of the base table. The CROSS JOIN and CROSS APPLY queries are roughly equivalent with regard to performance, but the CROSS APPLY has the advantage of being more readable, and as with all things CROSS APPLY, it provides a good bit of flexibility when it comes to continuing building on your query.
Thanks for reading! I’ll be back next week with more T-SQL goodies.
1 comment