A number of OLTP systems store dimension data in SCD2-like tables in order to retain all the revisions whenever the dimension information changes. In certain situations, you may come across a need to join two or more SCD tables, while keeping all the versions information intact. Sound tricky? Not really.
In the following examples, I’m going to use the LEAD() windowed function introduced in SQL Server 2012 as well as common table expressions. And if you haven’t read my post on date ranges, this may be a good time to do that as well.
An example
First off, some sample data to get us started. Let’s assume you have two tables, Clients and Projects. A client can have multiple projects, and in a non-versioned database schema, there would normally be a foreign key constraint to ensure this relation.
CREATE TABLE dbo.Clients (
clientCode varchar(10) NOT NULL,
startDate date NOT NULL,
[name] varchar(200) NOT NULL,
CONSTRAINT PK_Clients PRIMARY KEY CLUSTERED (clientCode, startDate)
);
CREATE TABLE dbo.Projects (
clientCode varchar(10) NOT NULL, --- Each project belongs to a client.
projectCode varchar(10) NOT NULL,
startDate date NOT NULL,
[name] varchar(200) NOT NULL,
CONSTRAINT PK_Projects PRIMARY KEY CLUSTERED (projectCode, startDate)
);
Now to add some sample data:
INSERT INTO dbo.Clients (clientCode, startDate, [name])
VALUES ('A', {d '2010-01-01'}, 'Client A (first)'),
('A', {d '2011-04-01'}, 'Client A (second)'),
('A', {d '2011-09-01'}, 'Client A (third)'),
('A', {d '2012-02-01'}, 'Client A (fourth)'),
('A', {d '2014-01-01'}, 'Client A (fifth)'),
('B', {d '2010-01-01'}, 'Client B (first)'),
('B', {d '2011-02-01'}, 'Client B (second)'),
('B', {d '2011-08-01'}, 'Client B (third)'),
('B', {d '2011-12-01'}, 'Client B (fourth)'),
('B', {d '2012-11-01'}, 'Client B (fifth)');
INSERT INTO dbo.Projects (clientCode, projectCode, startDate, [name])
VALUES ('A', '1', {d '2010-01-15'}, 'Project 1, first revision'),
('A', '1', {d '2012-04-22'}, 'Project 1, second revision'),
('A', '2', {d '2010-02-08'}, 'Project 2, first revision'),
('A', '2', {d '2010-09-12'}, 'Project 2, second revision'),
('A', '2', {d '2012-08-18'}, 'Project 2, third revision'),
('B', '3', {d '2011-04-01'}, 'Project 3, first revision'),
('B', '3', {d '2011-12-01'}, 'Project 3, second revision'),
('B', '3', {d '2014-02-28'}, 'Project 3, third revision');
For the purpose of illustration, all that happens in these tables is that the names of the clients and projects change over time.
Calculating the date interval
Note that the sample tables only have a startDate column. Because of this, we’ll have to calculate an endDate column based on the next startDate occurrence for each respective client and project. As of SQL Server 2012, there’s a very efficient windowed function called LEAD() that does just that.
SELECT clientCode, [name], startDate,
--- Find the next record's startDate, ordered by startDate.
LEAD(startDate, 1, {d '2099-12-31'}) OVER (
PARTITION BY clientCode
ORDER BY startDate) AS endDate
FROM dbo.Clients;
Like any other windowed function, we’ve designated a PARTITION BY clause, in this case in order to separate (partition) between different clients. Within that partition, the ORDER BY clause declares the order of the records within which you want the next record. The different arguments of the LEAD() function break down like this:
LEAD(startDate, 1, {d '2099-12-31'})
- “startDate” is the return value,
- “1” is how many rows ahead (leading) in the sort order, and
- “2099-12-31” is the value returned when there is no next row.
Note: The opposite of LEAD() is LAG() – they both work exactly the same, but in opposite directions. In fact, instead of LEAD(a, b, c) you could use LAG(a, -b, c) or vice versa.
Note 2: By “efficient”, you should be aware that the LEAD() function uses the Sequence Project operator, which means it won’t execute in a parallel zone in your execution plan.
Since we’re going to need the endDate for both clients and projects, we’re calculating the LEAD() on both those tables and putting them both in common table expressions for easy future reference.
--- Clients: WITH c (clientCode, [name], startDate, endDate) AS ( SELECT clientCode, [name], startDate, --- Find the next record's startDate, ordered by startDate. LEAD(startDate, 1, {d '2099-12-31'}) OVER ( PARTITION BY clientCode ORDER BY startDate) AS endDate FROM dbo.Clients), --- Projects: p (projectCode, clientCode, [name], startDate, endDate) AS ( SELECT projectCode, clientCode, [name], startDate, --- Find the next record's startDate, order by startDate LEAD(startDate, 1, {d '2099-12-31'}) OVER ( PARTITION BY projectCode ORDER BY startDate) AS endDate FROM dbo.Projects) ...
Joining the date ranges (intervals)
Here’s the tricky part – actually joining the two SCD2 tables together. If you don’t take the start and end dates into account, you’ll end up with a cartesian product. Also, you can’t really just join the start and end date columns, because they’ll most certainly be different because project and client rows overlap each other.
The join between clients (“c”) and projects (“p”) consists of two parts; the non-versioned part and the versioning logic. The non-versioned part is fairly simple, like you would join the two tables if they weren’t versioned in the first place:
FROM c
INNER JOIN p ON
c.clientCode=p.clientCode
As I said, this creates a cartesian product, where you get every version of the client for every version of the project. This is where the second part of the join comes in:
AND c.startDate<p.endDate
AND c.endDate>p.startDate
These two conditions basically make sure that the client’s start and end dates overlap the project’s start and end dates.
WITH... ... SELECT c.clientCode, c.startDate, c.endDate, c.[name] AS clientName, p.projectCode, p.startDate, p.endDate, p.[name] AS projectName FROM c INNER JOIN p ON c.clientCode=p.clientCode AND c.startDate<p.endDate AND c.endDate>p.startDate ORDER BY c.clientCode, p.projectCode;
Here’s the output of this query:
clientCode startDate endDate clientName projectCode startDate endDate projectName ---------- ---------- ---------- ----------------- ----------- ---------- ---------- -------------------------- A 2010-01-01 2011-04-01 Client A (first) 1 2010-01-15 2012-04-22 Project 1, first revision A 2011-04-01 2011-09-01 Client A (second) 1 2010-01-15 2012-04-22 Project 1, first revision A 2011-09-01 2012-02-01 Client A (third) 1 2010-01-15 2012-04-22 Project 1, first revision A 2012-02-01 2014-01-01 Client A (fourth) 1 2010-01-15 2012-04-22 Project 1, first revision A 2012-02-01 2014-01-01 Client A (fourth) 1 2012-04-22 2099-12-31 Project 1, second revision A 2014-01-01 2099-12-31 Client A (fifth) 1 2012-04-22 2099-12-31 Project 1, second revision A 2010-01-01 2011-04-01 Client A (first) 2 2010-02-08 2010-09-12 Project 2, first revision A 2010-01-01 2011-04-01 Client A (first) 2 2010-09-12 2012-08-18 Project 2, second revision A 2011-04-01 2011-09-01 Client A (second) 2 2010-09-12 2012-08-18 Project 2, second revision A 2011-09-01 2012-02-01 Client A (third) 2 2010-09-12 2012-08-18 Project 2, second revision A 2012-02-01 2014-01-01 Client A (fourth) 2 2010-09-12 2012-08-18 Project 2, second revision A 2012-02-01 2014-01-01 Client A (fourth) 2 2012-08-18 2099-12-31 Project 2, third revision A 2014-01-01 2099-12-31 Client A (fifth) 2 2012-08-18 2099-12-31 Project 2, third revision B 2011-02-01 2011-08-01 Client B (second) 3 2011-04-01 2011-12-01 Project 3, first revision B 2011-08-01 2011-12-01 Client B (third) 3 2011-04-01 2011-12-01 Project 3, first revision B 2011-12-01 2012-11-01 Client B (fourth) 3 2011-12-01 2014-02-28 Project 3, second revision B 2012-11-01 2099-12-31 Client B (fifth) 3 2011-12-01 2014-02-28 Project 3, second revision B 2012-11-01 2099-12-31 Client B (fifth) 3 2014-02-28 2099-12-31 Project 3, third revision
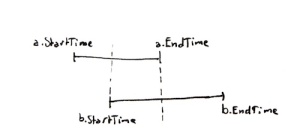
The aim of our query is to return discrete intervals in sequence, i.e. where no two intervals reference the same date. The trick to doing this is to identify which dates where the client and project ranges actually overlap each other. To do this, the output startDate has to be the last of the two start dates (chronologically), while the output endDate has to be the first of the two endDates.
I’ve recycled the image on the right from another post, but the concept is the same: The output interval is defined by the larger of (a.startTime, b.startTime) and the smaller of (a.endTime, b.endTime).
In the SELECT part of the query, it looks like this:
SELECT (CASE WHEN c.startDate<p.startDate THEN p.startDate ELSE c.startDate END) AS actualStart, (CASE WHEN c.endDate<p.endDate THEN c.endDate ELSE p.endDate END) AS actualEnd
Putting it all together
Here’s the finished product:
--- Clients: WITH c (clientCode, [name], startDate, endDate) AS ( SELECT clientCode, [name], startDate, --- Find the next record's startDate, ordered by startDate. LEAD(startDate, 1, {d '2099-12-31'}) OVER ( PARTITION BY clientCode ORDER BY startDate) AS endDate FROM dbo.Clients), --- Projects: p (projectCode, clientCode, [name], startDate, endDate) AS ( SELECT projectCode, clientCode, [name], startDate, --- Find the next record's startDate, order by startDate LEAD(startDate, 1, {d '2099-12-31'}) OVER ( PARTITION BY projectCode ORDER BY startDate) AS endDate FROM dbo.Projects) SELECT c.clientCode, c.[name] AS clientName, p.projectCode, p.[name] AS projectName, --- Start date is the last of (c.startDate, p.startDate) (CASE WHEN c.startDate<p.startDate THEN p.startDate ELSE c.startDate END) AS startDate, --- End date is the first of (c.endDate, p.endDate) (CASE WHEN c.endDate<p.endDate THEN c.endDate ELSE p.endDate END) AS endDate FROM c INNER JOIN p ON c.clientCode=p.clientCode AND c.startDate<p.endDate AND c.endDate>p.startDate ORDER BY c.clientCode, p.projectCode, 5;
You may recognize some of the logic from a recent post on distributing values with overlapping ranges.
As always, check back next week for more T-SQL related articles.
I found this approach didn’t work for me in all cases, particularly joining two tables where there was only one row of data per customer.
The approach outlined at https://blog.oraylis.de/2014/11/combining-multiple-tables-with-valid-fromto-date-ranges-into-a-single-dimension/ did although it is more intensive.
Interesting. This is a fairly old post, but I’ll take a look at it if/when I get the time.
Thanks for your feedback!
New URL: https://www.oraylis.de/blog/2014/combining-multiple-tables-with-valid-from-to-date-ranges-into-a-single-dimension
Hi, if anyone is checking on this solution, you may also take another approach (if your infra do not get into spool space error)
say, if you need to join 3 scd tables
– join by sys calendar and get the data from all three tables for each day
– of the above, then apply preceeding function and compare the change columns (columns which defines scd change) from current record to next record; if there’s a change have a new column as ‘change’ else ‘duplicate’
– remove all the ‘duplicate’ records
– with the above set as subquery, have another preceeding function to get the end date (next occurrence date)
hope this helps
thanks!
This is a perfectly good solution, but it may blow up if you have a lot of versions in short timeframes. In order to not get duplicates, you would need a calendar table with the same or greater granularity as the SCD2 dimensions – and you probably don’t have or want a date/time table with millisecond grain. 🙂
This is a soul saving query. I’ll keep it in my heart forever.
Coming at you in 2022; I consider this a very important post on a problem that is still relatively under-documented elsewhere. Thank you so much.
Here are a couple findings on my journey with this problem:
If your database supports it, GREATEST() and LEAST() work as great replacements for the final CASE statements calculating start/end.
Additionally, regarding joining 3+ scd tables (as others have discussed above):
My approach has been to follow the same solution as two tables, with one added twist. Three or more tables (with this solution) yield occasional duplicate rows with impossible start/end dates (e.g. start 12pm / end 8am). I’ve removed these with a filter: WHERE GREATEST(a.start, b.start) < LEAST(a.end, b.end). That has taken care of the problem. If anyone has additional suggestions or improvements from their experience, I'd love to hear it.
Cheers and thanks again for your post!
Those are great points! Maybe I should revisit this post. 🙂