Understanding indexes in SQL Server can help you build much more efficient database solutions. Often, performance problems can be adressed with indexes, so knowing how indexes work and how to set them up for the best performance are a great asset in your optimization work.
What is an index?
An index is a “map” or a “table of contents” to a table. If you’re looking for data in a table, an index can tell you where to start looking. Technically speaking, indexes on SQL Server are B-trees (binary trees). Each node in the binary tree is an 8 kB data page. Here’s a graphical representation of what it could look like.
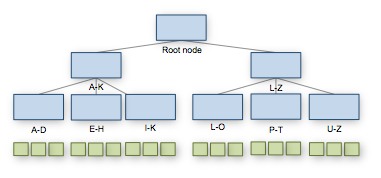 Every B-tree has one root node. The green boxes at the bottom of the diagram are leaf nodes. Depending on the number of leaf nodes (i.e. how much data there is in the index) the number of levels between the root node and its leaf nodes can vary considerably.
Every B-tree has one root node. The green boxes at the bottom of the diagram are leaf nodes. Depending on the number of leaf nodes (i.e. how much data there is in the index) the number of levels between the root node and its leaf nodes can vary considerably.
Clustered vs non-clustered
There are basically two different types of indexes in SQL Server, clustered and non-clustered. Each object can have one clustered index and up to 249 non-clustered indexes. The reason you can only have one clustered index is that the leaf nodes of a clustered index contain the actual row data of the table. Because of this, the way you sort the columns of a clustered index defines how the table is physically sorted when stored in the database.
If you can, try to make your clustered index unique – a non-unique index will add an invisible key column, called a “uniquifier”, which takes up space in the index.
A table that does not have a clustered index is stored in the order you insert rows into it, and any time you want to find a value in it, you will have to look through the entire table for it, which is time consuming. Consequently, tables without clustered indexes are called “heaps“. In 99.9% of all cases, you should give a table a clustered index.
Non-clustered indexes work the same way as the clustered index, except the leaf nodes don’t store the entire row, but a pointer to the row.
Index scans, index seeks and table scans
When you run a query that needs to access information in a table, the optimizer will normally auto-select the most optimal index from those available to accomplish the task at hand. How the index or heap is accessed depends on what search criteria you’ve set in your query, for instance JOIN conditions or WHERE clauses, and the order in which the columns are indexed. It comes down to two kinds of operations, basically.
An index seek uses the tree structure of the index to find a specific data page.
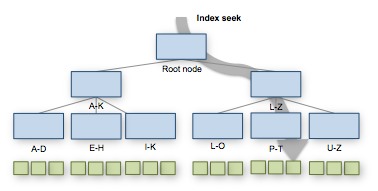 This is a very fast operation, but it can only be used when you want to retrieve single records. The other way to access an index is with an index scan:
This is a very fast operation, but it can only be used when you want to retrieve single records. The other way to access an index is with an index scan:
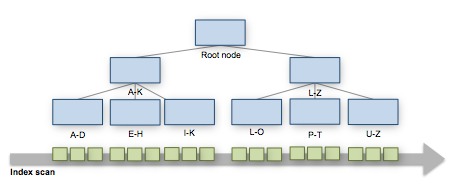
Index scans go through the data pages directly, so they are very suitable for selecting ranges of data or looking for data in columns that aren’t first in the indexing order.
Similarly, a table scan goes through a heap, row by row. If you see a table scan operator in your query plan graph, this means that you should add a clustered index!
Keeping indexes narrow
Every page in an index can store 8 kB of data. This means that the more data there is, the more data pages you need, the larger the index becomes, and the more time it will take to scan or seek through it.
Because of this, try to keep your indexes “narrow”. By narrow, I mean that the size of the column(s) in the index should be kept as small as possible. If you can, don’t index a varchar column, if an int column would do just as well.
Fill factor and ordering
The fill factor of an index determines how much of the page (in percent) is initially allocated. If your data is very static, you can have a high fill factor, so you don’t waste disk space and I/O performance.
But if you regularly insert data in the middle of the index, you may fill up the free space in the data pages, and then SQL Server will have to shuffle data or insert new pages, which fragments your index, which in turn is detrimental to performance. A lower fill factor will leave you more space in the pages so you can insert records.
The T-SQL
Creating an index is very simple in T-SQL:
CREATE UNIQUE CLUSTERED INDEX indexname
ON tablename (column_a, column_b, column_c)
The UNIQUE keyword ensures that the index is unique – which means it does not allow duplicates. CLUSTERED makes the index clustered. You can add other keywords and hints to set a file group, determine the sort order of the column(s), include non-indexed columns and more. See Books Online for more detail.
12 comments