Knowing how to read a query plan is absolutely key to optimizing SQL Server query performance. The query plan tells you how SQL Server goes about running your query, including what indexes are used (and how), what join strategies are applied and a lot of other information. If you can read the query plan, you can make the appropriate changes to indexes, query hints, join conditions, etc to tune your workload for optimum performance.
How to view a query plan
You can show an estimated query plan by selecting the query you want to evaluate and press Ctrl+L. This will set the SHOWPLAN flag in SQL Server, so the execution of the query is limited to just displaying the query plan, not actually executing the query.
The other way is to enable “Include actual query plan” (press Ctrl+M to toggle). The difference between these two is that the actual query plan is displayed as the query runs. The estimated query plan is, like the name implies, just an estimate. In my opinion, the two rarely differ significantly.
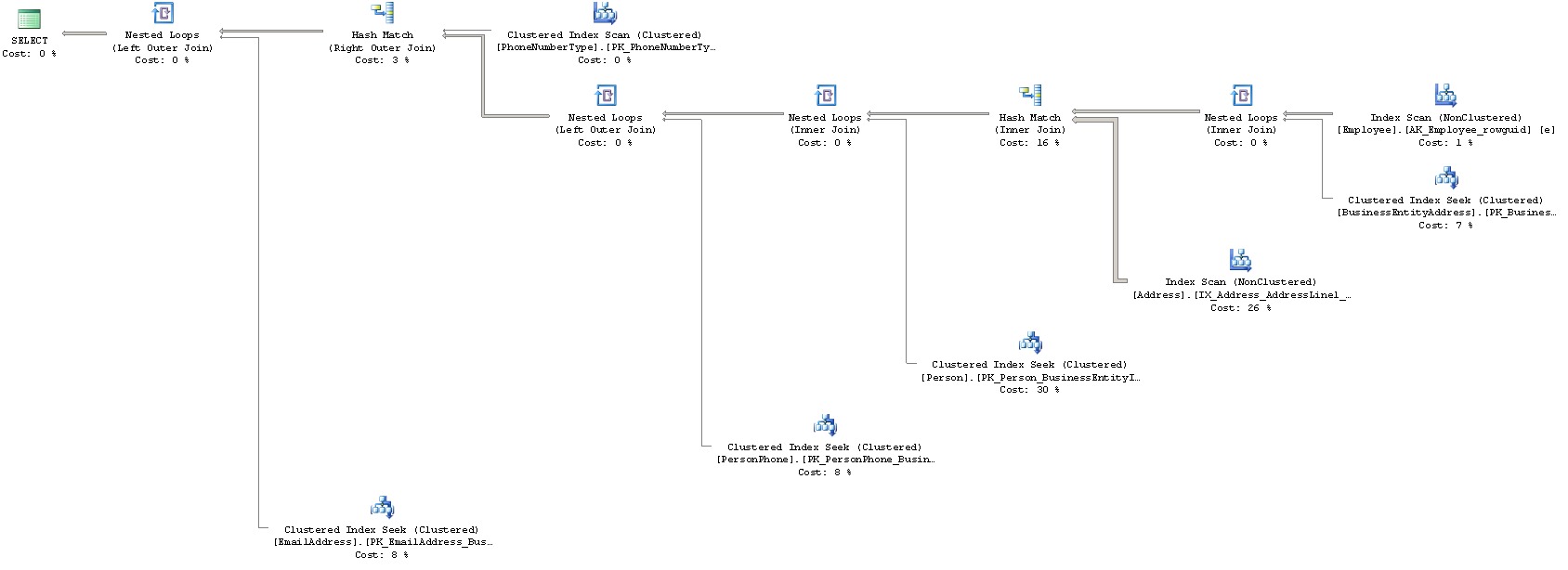
Here’s an example of how your query plan might look.
 The flow of it
The flow of it
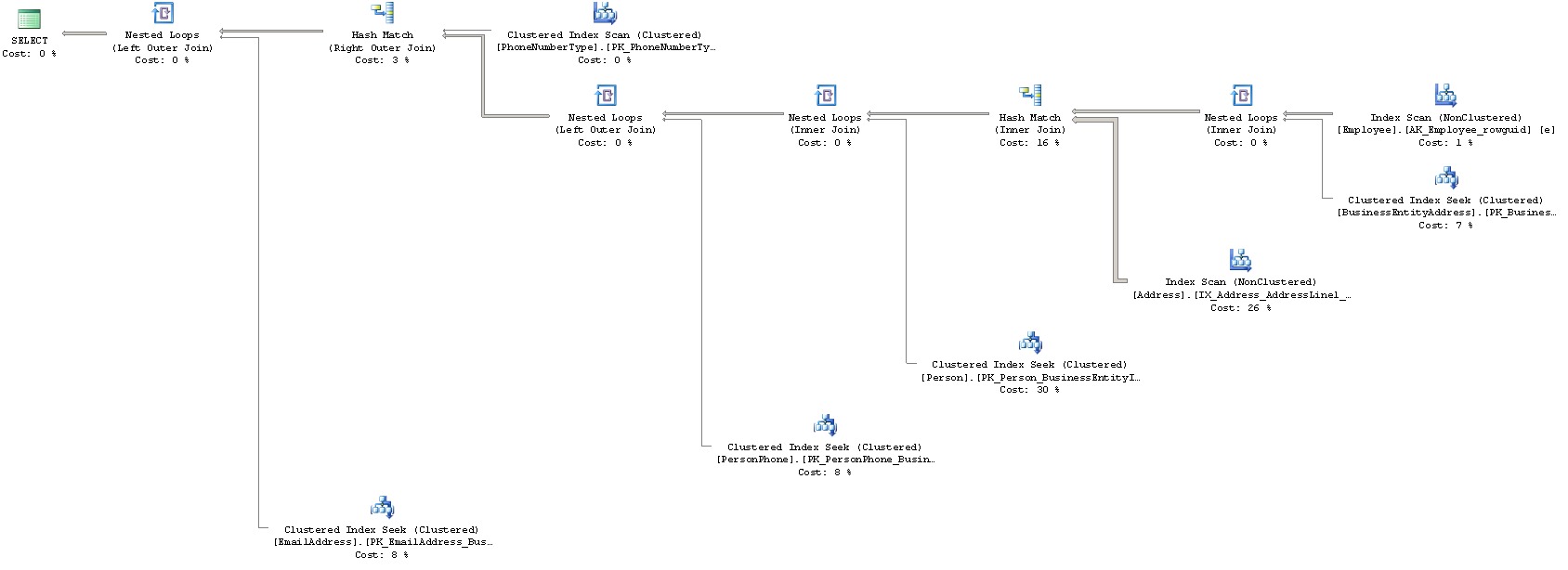
Query plans are read from right-to-left; that is, each table or index that is collected along the way is a “leaf” node, all the way out to the right, and the final result of the operation is the top-left node. In the example plan above, you can see that we’re joining 7 different tables into one big SELECT query.
It’s important to understand that while T-SQL is merely a language that describes what you want to do with your query, the actual query plan may actually differ significantly from how you write the query. The reason for this is that the SQL Server optimizer normally does a very good job in finding the most efficient method to solve the task at hand, but that method may not follow for instance the join order or methods that you imagined. It all comes down to how the data is physically arranged in the database.
Indexes and statistics
The primary help for the query optimizer in this task are the different indexes and statistics that exist on the different objects that are referenced in the query. For this reason, making sure that tables are well-indexed and that their statistics are up-to-date can dramatically improve your query performance.
Common query plan operators
Here’s a fairly common selection of operators you will probably encounter in query plans:
![]() Clustered index seek,
Clustered index seek, ![]() index seek
index seek
An index seek is where the server looks for a single value or a closed interval of values. Unless you want to return the entire index/table, a seek is generally preferrable to a scan (see below).
![]() Clustered index scan,
Clustered index scan, ![]() index scan
index scan
An index scan occurs when it’s not possible to “seek” a value in the index, for instance because you’re using a wildcard condition. It is also applied when you deliberately want to make use of the entire index or (clustered) table.
![]() Table scan
Table scan
If this operator turns up, you’ve forgotten to create a clustered index to your table. It goes through the entire table, top-to-bottom, which is resource-consuming and results in very poor performance and takes a heavy toll on the I/O. A table scan only happens when there is no suitable index available to complete the query.
![]() Nested loops
Nested loops
Nested loops is a way to JOIN two tables. This method is mostly practical when one table is considerably larger than the other. For each row in the “outer” table, it loops through the “inner” table.
![]() Merge join
Merge join
A merge join is the single most optimal join method from a performance standpoint, but in order to achieve it, the key columns of the two data sets to be joined need to match perfectly with regard to data types and sort orders.
![]() Hash match, hash join
Hash match, hash join
This is the JOIN method applied if a nested loop or merge join is not feasible. It uses internal hash tables to join two data sets.
![]() Filter
Filter
The filter operator most closely resembles the WHERE or HAVING clauses, where these operations cannot be performed directly on the index or table.
![]() Constant scan
Constant scan
Represents the use of constants, without the need to retrieve any value from an actual index or table, for instance
SELECT 123 AS my_integer;
![]() Compute scalar
Compute scalar
Any scalar calculation performed, for example arithmetic operations, string functions, etc.
![]() Sort
Sort
Sorting the dataset can be performed at the end of the query in order to comply with an ORDER BY directive, or for instance before a JOIN operator in order to prepare the data set for a more optimized join method.
Tooltip information
If you hover over a node in the query plan, you’ll see a lot of detailed information about each node. The most important ones to look for are the estimated I/O and CPU costs (how much disk input/output workload and computing power respectively that the step will consume), as well as the subtree cost.
Also, take a look at the output list and/or predicates, at the bottom of the tooltip. They provide more detail about columns are used in a join operator, what columns is output from an index scan, etc.
More details
Again, this is but a selection of common query plan operators that you’re likely to encounter. There are a lot more operators, with more detailed descriptions, available on MSDN. A deeper discussion on the performance aspects and requirements of different JOIN and indexing stragies will be the topic of a separate post. Stay tuned.
6 comments