When you update a column that is tied to a foreign key constraint, SQL Server needs to validate (called “assert“) the new value, in order to make sure that you haven’t added a value with no matching primary key. But in some situations, it’ll assert more than just the column(s) you updated.
The setup
Here’s a test setup:
--- Primary key table "A" CREATE TABLE dbo.pkA ( keyA int NOT NULL, CONSTRAINT PK_a PRIMARY KEY CLUSTERED (keyA) ); --- Primary key table "B" CREATE TABLE dbo.pkB ( keyB int NOT NULL, CONSTRAINT PK_b PRIMARY KEY CLUSTERED (keyB) ); --- The fact table. CREATE TABLE dbo.fact ( keyA int NOT NULL, keyB int NOT NULL, amount int NOT NULL, CONSTRAINT PK PRIMARY KEY CLUSTERED (keyA, keyB), CONSTRAINT FK_a FOREIGN KEY (keyA) REFERENCES dbo.pkA (keyA), CONSTRAINT FK_b FOREIGN KEY (keyB) REFERENCES dbo.pkB (keyB) ); --- A common table expression that loops out a few values... WITH iterator (n) AS (SELECT 1 AS n UNION ALL SELECT n+1 AS n FROM iterator WHERE n<100) --- ... to populate "A" and "B": INSERT INTO dbo.pkA (keyA) SELECT n FROM iterator; INSERT INTO dbo.pkB (keyB) SELECT keyA FROM dbo.pkA; --- And finally, populate the fact table: INSERT INTO dbo.fact (keyA, keyB, amount) SELECT a.keyA, b.keyB, 0.01*ROW_NUMBER() OVER (ORDER BY keyA, keyB) FROM dbo.pkA AS a INNER JOIN dbo.pkB AS b ON a.keyA%2=0 AND b.keyB%2=0;
About the Assert operator
![]()
The “Assert” operator appears in a query plan when SQL Server needs to verify a value, commonly some sort of constraint like a CHECK or FOREIGN KEY (but there are other scenarios as well). In the case of a foreign key constraint, it’ll appear along with a JOIN operator to the primary key table in question. The operation of joining a primary key table to your fact table when you make an update or insert may be rather expensive, depending on factors such as table size.
Here are a few different updates:
A regular update
This one’s pretty straight-forward. An update that does not affect any foreign keys at all. As predicted, we won’t see any Assert operators, because there is really nothing going on with the foreign keys, and there are no check constraints involved.
UPDATE dbo.fact SET amount=amount+1;
Here’s the query plan:

Changing a foreign key column
But if we update a column that is tied to a foreign key, keyB, then the Assert operator appears. You’ll notice that SQL Server needs to join the “B” table to do this.
UPDATE dbo.fact SET keyB=keyB+1 WHERE keyB<98;
 This JOIN can place a severe performance load on your server if your update affects a lot of fact rows. In this example, the fact table is sorted (20%) to be able to merge-join it (10%) to the primary key table (1%), after which the assert (1%) is performed, which means that a total of 32% of the query is related to asserting the foreign key constraint integrity in the update.
This JOIN can place a severe performance load on your server if your update affects a lot of fact rows. In this example, the fact table is sorted (20%) to be able to merge-join it (10%) to the primary key table (1%), after which the assert (1%) is performed, which means that a total of 32% of the query is related to asserting the foreign key constraint integrity in the update.
Update that affects the clustered index
Here’s a somewhat different, unexpected result. If you update the “A” column, look what happens with the query plan now.
UPDATE dbo.fact SET keyA=keyA+1 WHERE keyA<98;
 Did you notice that SQL Server also joins and asserts the “B” table constraint, although we’ve only updated the “A” column?
Did you notice that SQL Server also joins and asserts the “B” table constraint, although we’ve only updated the “A” column?
When we update key values in the clustered index, SQL Server has to relocate the updated records. To do this, the UPDATE statement actually turns into a DELETE and an INSERT (though you can’t see this in the query plan to my knowledge).
The reason this happens is because the clustered index defines the physical sort order of the table, i.e. how records are stored in the pages of the database files. If we change the key values, the record needs to physically move from one place in the table to another. This is done by deleting the old record, and inserting the new record, and in this insert operation, we’re going to have to assert all the affected foreign keys.
Update-in-place
In this context, it’s fair to mention that there are two ways SQL Server can update a table record. The “default” method is the delete/insert method discussed above, as this works with all kinds of updates. However, there is a much more efficient method called “update-in-place“, which works pretty much like you would imagine an UPDATE operation.
An update-in-place actually overwrites just the individual cell values affected by the UPDATE statement. But in order for this to be possible, a number of criteria must be met. These are the main criteria for update-in-place, though there are others as well:
- The table cannot have an UPDATE trigger, because the trigger needs to be able to look at the values before and after the update (remember the special inserted and deleted tables used in triggers).
- There must be space for the new value without having to move an adjacent record in the page. An example of this is if you update an integer value to another integer value – they take up the same amount of space. Modifying a varchar value, however, may very well require more space than the row currently has allocated.
- You can’t update a key in a clustered index, because this would move the row, as we saw above. Moving the row implicitly deletes the old row and creates a new one.
Here’s a comparison between a delete-insert vs an update-in-place:
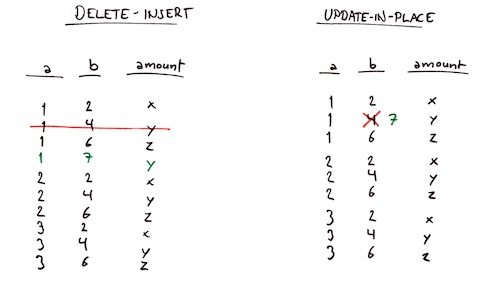
1 comment