A question from a client got me thinking. Relational databases (at least the ones I know and love) can’t really index for queries that use LIKE queries for a substring of a column value. If you want to search for strings beginning with a given string, a regular rowstore index will have you covered. If you’re looking for entire words or sentences, a full text index might be a good call. But because of the very way indexes work, you’ll never get great performance searching for just arbitrary parts of a string.
So today I’ll put on my lab coat and do a little rocket surgery, just to prove to the world that it can be done.
Professional driver on closed roads, always wear protection. Your mileage may vary.
Disclaimer: This is not production-quality code. There are hard-coded limitations and assumptions that may not work in your environment.
Demo data setup
To test out string searches in text fields, I needed something with a lot of text, so for this post I’m using the 50 GB Stack Overflow database. The Posts table has 17 million rows. I want to be able to search the “Title” field, an nvarchar(300) column, for an arbitrary string.
Attempt 1: Brute force
Ok, how hard could it be. Just scan the entire posts table, right?
SELECT *
FROM dbo.Posts
WHERE Title LIKE '%physical reads%';
No surprises. SQL Server scans through the table’s clustered index, a healthy 33 GB of data. It’s actually so much work that it runs parallel.
Table 'Posts'. Scan count 5, logical reads 4192450, physical reads 950. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0. (1 row affected) SQL Server Execution Times: CPU time = 27562 ms, elapsed time = 10886 ms.
It finishes in around 11 seconds on 4 cores, But that’ll bring your server to it knees in a hurry if you have just a couple of concurrent users running searches.
Attempt 2: How about a compressed, non-clustered index?
So what happens if we slap an index on the Title column? Even though we’d still have to scan the entire index, we could design the index to just include the Title column so it’s much narrower. To even further reduce the number of logical reads, let’s add some PAGE compression on it:
CREATE INDEX IX_Title
ON dbo.Posts (Id)
INCLUDE (Title)
WITH (DATA_COMPRESSION=PAGE);
Our search runs twice as fast as before, but 5.5 seconds to search 17 million rows still isn’t great.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0. Table 'Posts'. Scan count 5, logical reads 57823, physical reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0. (1 row affected) SQL Server Execution Times: CPU time = 20280 ms, elapsed time = 5539 ms.
Attempt 3: Full text indexes
Full text indexing works on words and has some pretty cool logic to index for variations (“stems”) of the same word. But it is inherently designed for searches on words and sentences, not parts of words or strings. Full text search and LIKE are two completely different animals.
Fair warning.
This is probably where I should have called it a day. But that’s not why you’re here.
Attempt 4: The caveman suffix tree
Probably the most optimal way to solve this task is with a Suffix Tree index. A Suffix Tree is a binary tree structure where every character in a string is a node in a tree. Descentants represent the characters that would follow in sequence, so you can recurse through the tree to find specific strings just like you would traverse a SQL Server rowstore index in an Index Seek. If you do the math, those trees can become huge, unmanageable structures, so they may not be a great fit for a relational database. Needless to say, you can’t natively create suffix trees in SQL Server.
But maybe we could just create a simple lookup table, around which we can design our search?
CREATE TABLE dbo.PostTitle (
Id int NOT NULL,
Offset smallint NOT NULL,
TitleChar nchar(1) NOT NULL,
CONSTRAINT PK_PostTitle PRIMARY KEY CLUSTERED (Id, Offset) WITH (DATA_COMPRESSION=PAGE),
INDEX IX_TitleChar UNIQUE (TitleChar, Id, Offset) WITH (DATA_COMPRESSION=PAGE)
);
For every row in Posts, we’ll split the Title column into characters, and store each character in its own row in dbo.PostTitle, along with the Offset where it appears. This way, if we’re looking for the string “physical reads”, we’d look for all the titles with the character P, and then gradually narrow down the results by checking if the character in line (the next Offset) is an “H”, and the one after that an “Y”, and so on.
I designed a little table value function to split a string into its character components.
CREATE OR ALTER FUNCTION dbo.CHAR_SPLIT(@string nvarchar(1000))
RETURNS TABLE
AS
RETURN (
WITH num AS (
SELECT i
FROM (VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9)) AS n(i))
SELECT o.Offset, ch.[Char]
--- Number table, up to the length of @string:
FROM (
SELECT TOP (LEN(@string))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS i
FROM num AS a, num AS b, num AS c, num AS d
) AS o(Offset)
--- One character for each offset in the number table:
CROSS APPLY (
VALUES (SUBSTRING(@string, o.Offset, 1))
) AS ch([Char])
--- Empty strings will break things
WHERE LEN(@string)>0
);
In short, the function creates a common table expression called “num” that contains 10 rows. It then cross-joins this CTE a couple of times with a TOP() clause to create just as many rows as there are characters in the @string variable. Then, for each of those rows, it returns an offset and the character at that offset.
SELECT * FROM dbo.CHAR_SPLIT('physical reads');

To stuff all this data into our dbo.PostTitle, our lookup table, we can just:
TRUNCATE TABLE dbo.PostTitle;
INSERT INTO dbo.PostTitle (Id, Offset, TitleChar)
SELECT p.Id, cs.Offset, cs.[Char] AS TitleChar
FROM dbo.Posts AS p
CROSS APPLY dbo.CHAR_SPLIT(p.Title) AS cs
WHERE LEN(p.Title)>0
OPTION (NO_PERFORMANCE_SPOOL);
Sidebar: minimizing the sorts
Did you notice the query hint at the end? I put it there because this was what my plan looked like when SQL Server added a Lazy Spool:

Because SQL Server doesn’t know the data in my table, it makes an educated guess. And an educated guess in a 17 million row table with an nvarchar column would be that there are bound to be a fair number of duplicate values in Title. You and I, dear reader, know that there are honestly not that many duplicate posts on Stack Overflow, but again, SQL Server doesn’t know this.
So to try to optimize this query, SQL Server will sort the entire Posts dataset by Title, and then buffer the output of the table value function for each row, in order to perhaps be able to re-use that output if the same Title comes back more than once.
But in an almost-unique dataset, this Sort makes for a pretty severe performance hit with no real upside, because we’re sorting hundreds and hundreds of megabytes, so I’ve added the OPTION (NO_PERFORMANCE_SPOOL) at the end to try to claw back a few minutes of execution time. Again, your mileage may vary. But here’s what the plan looks after:

First attempt at a search query
Here’s the first draft of a stored procedure to query our shiny new index table:
CREATE OR ALTER PROCEDURE dbo.SearchPostTitle_1st_attempt
@searchString nvarchar(300)
AS
WITH search AS (
SELECT t1.Id,
t1.Offset,
SUBSTRING(@searchString, 2, LEN(@searchString)) AS searchString
FROM dbo.PostTitle AS t1
WHERE t1.TitleChar=SUBSTRING(@searchString, 1, 1)
UNION ALL
SELECT search.Id,
t.Offset,
SUBSTRING(search.searchString, 2, LEN(search.searchString)) AS searchString
FROM search
INNER JOIN dbo.PostTitle AS t ON search.Id=t.Id AND search.Offset+1=t.Offset
WHERE t.TitleChar=LEFT(search.searchString, 1)
AND search.searchString!=N'')
SELECT *
FROM dbo.Posts
WHERE Id IN (
SELECT Id
FROM search
WHERE searchString=N'');
It’s a recursive common table expression:
- The anchor looks for all Ids where the first character of the search string appears.
- Using the anchor, we’ll look for the next offset for the same Id, but only if that character is also the next character in the search string.
- We’ll recurse this step until we run out of search string.
- Finally, we’ll collect all the rows in dbo.Posts matching the remaining Ids from the recursion.
This query has a few problems, which makes it run for a whopping 67 seconds.
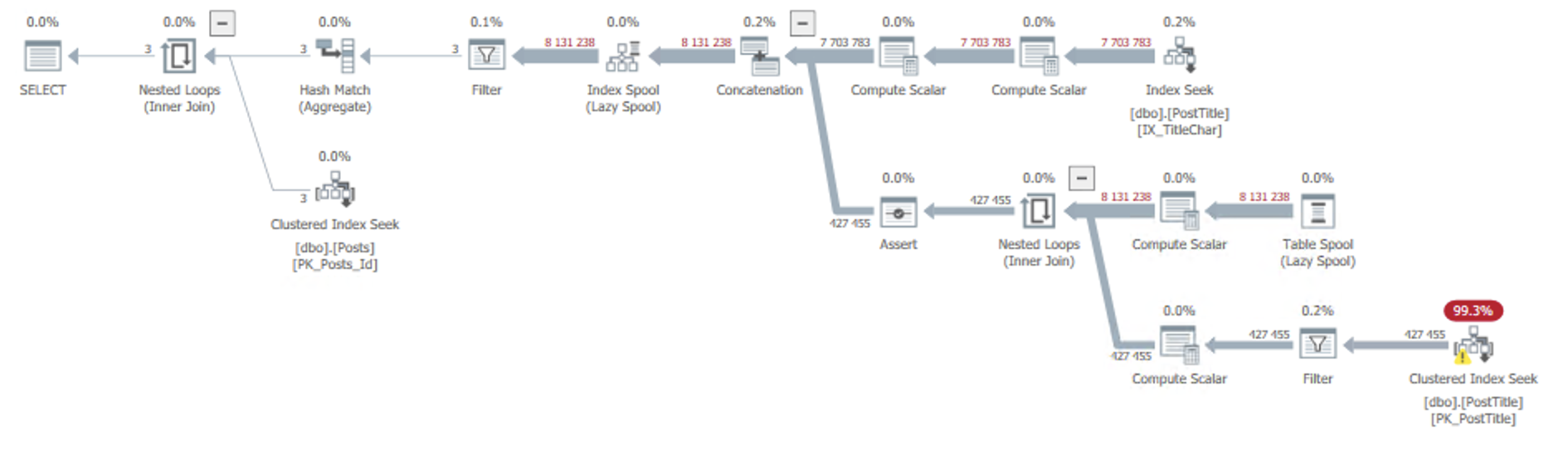
- Because it’s a recursive common table expression, it won’t go parallel.
- Because most characters in the title fall within the A-Z range of the alphabet, most characters are very common. Space appears 43 million times, the letter “R” 7 million times, and “S” 15 million times. This means that the anchor can become very large, and every subsequent join can become rather large.
Second attempt: we’re gonna need a smaller anchor
I think one of the main problems here is that the anchor is potentially huge. Maybe we can narrow down the anchor if we force the user to use at least three characters in the search string, then construct the anchor to use not just the first character, but the first three characters.
CREATE OR ALTER PROCEDURE dbo.SearchPostTitle_2st_attempt
@searchString nvarchar(300)
AS
WITH search AS (
SELECT t1.Id, t3.Offset, SUBSTRING(@searchString, 4, LEN(@searchString)) AS searchString
FROM dbo.PostTitle AS t1
INNER JOIN dbo.PostTitle AS t2 ON t1.Id=t2.Id AND t2.Offset=t1.Offset+1
INNER JOIN dbo.PostTitle AS t3 ON t1.Id=t3.Id AND t3.Offset=t2.Offset+1
WHERE t1.TitleChar=SUBSTRING(@searchString, 1, 1)
AND t2.TitleChar=SUBSTRING(@searchString, 2, 1)
AND t3.TitleChar=SUBSTRING(@searchString, 3, 1)
UNION ALL
SELECT search.Id, t.Offset, SUBSTRING(search.searchString, 2, LEN(search.searchString)) AS searchString
FROM search
INNER JOIN dbo.PostTitle AS t ON search.Id=t.Id AND search.Offset+1=t.Offset
WHERE t.TitleChar=LEFT(search.searchString, 1)
AND search.searchString!=N'')
SELECT *
FROM search
WHERE searchString=N'';
This query shows some promise, coming in at four seconds!
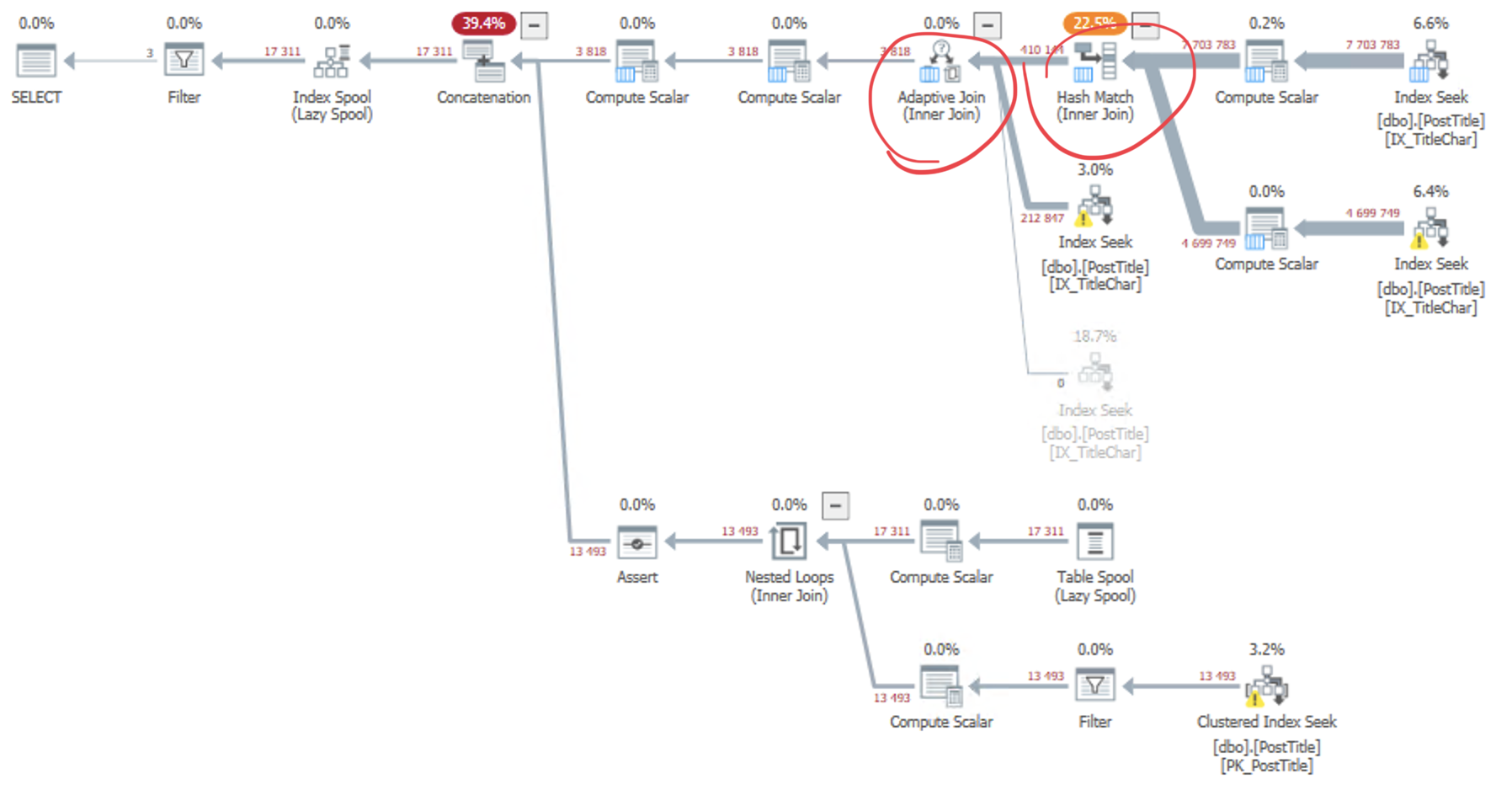
But all those Hash Match (Inner Join) operators are not free. This query consumes an impressive 808 MB memory grant. That won’t scale at all on a busy system. The query runs about as fast as the Non-Clustered Index Scan, but it uses twice the I/O and a huge memory grant.
Improved second attempt: offloading the anchor
To improve performance, I offloaded the creation of the anchor in the recursive CTE to a separate query, in order to get it out of the CTE. This way, it would go parallel, which turned out to improve performance a bit:
CREATE OR ALTER PROCEDURE dbo.SearchPostTitle_3rd_attempt
@searchString nvarchar(300)
AS
CREATE TABLE #anchor (
Id int NOT NULL,
Offset smallint NOT NULL,
PRIMARY KEY CLUSTERED (Id, Offset)
);
--- Build the anchor:
INSERT INTO #anchor (Id, Offset)
SELECT t1.Id, CAST(t1.Offset+2 AS smallint) AS Offset
FROM dbo.PostTitle AS t1
WHERE TitleChar=SUBSTRING(@searchString, 1, 1)
AND Id IN (SELECT Id FROM dbo.PostTitle WHERE TitleChar=SUBSTRING(@searchString, 2, 1) AND Offset=t1.Offset+1)
AND Id IN (SELECT Id FROM dbo.PostTitle WHERE TitleChar=SUBSTRING(@searchString, 3, 1) AND Offset=t1.Offset+2);
-- Recursive CTE:
WITH search AS (
SELECT Id, Offset, SUBSTRING(@searchString, 4, 300) AS searchString
FROM #anchor
UNION ALL
SELECT search.Id, t.Offset, SUBSTRING(search.searchString, 2, 300) AS searchString
FROM search
INNER JOIN dbo.PostTitle AS t ON search.Id=t.Id AND search.Offset+1=t.Offset
WHERE t.TitleChar=LEFT(search.searchString, 1)
AND search.searchString!=N'')
-- Results:
SELECT *
FROM dbo.Posts
WHERE Id IN (
SELECT Id
FROM search
WHERE searchString=N'');
The memory grant is down to 300 MB, which is still very high, but we’ve also got parallelism, so the anchor now builds in about 0.25 seconds:

The recursion is very similar to before, but without the expensive Hash Matches:

The complete search finishes in 1.2 seconds! Reads are still about twice the Non-Clustered Index Scan, so at this point, you’re choosing one of two evils.
Attempt 5: The wide hashed caveman suffix tree
Edit: as one commenter noted, the following pattern is apparently called a trigram search, and Paul White already wrote a very thorough post on this back in 2017.
The dbo.PostTitle table weighs in at over 6 GB with compression, to essentially fit about 300 MB of post titles. And all our search queries so far have generated massive reads and huge memory grants. None of these are particularly desirable, so let’s see if we can do another take on this:
- A lookup table that contains three characters at a time, rather than just one. This lets us build the anchor dataset with a single Index Seek rather than joining three relatively expensive ones.
- Skipping the Offset column, because three characters gives us a much, much more narrow search result.
- Hashing the three characters using the CHECKSUM() function saves us a little space (from 6 bytes to 4 per row), but again, it requires the search string to be at least three characters long.
Here’s what I have in mind for the lookup table:
CREATE TABLE dbo.PostTitle_block (
Id int NOT NULL,
Chksum int NOT NULL,
CONSTRAINT PK_PostTitle_block PRIMARY KEY CLUSTERED (Id, Chksum) WITH (DATA_COMPRESSION=PAGE),
INDEX IX_TitleBlock UNIQUE (Chksum, Id) WITH (DATA_COMPRESSION=PAGE)
);
To populate this table, we’ll need to update our character split function:
CREATE OR ALTER FUNCTION dbo.BLOCK_SPLIT(@string nvarchar(1000))
RETURNS TABLE
AS
RETURN (
WITH num AS (
SELECT i
FROM (VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9)) AS n(i))
SELECT DISTINCT CHECKSUM(LOWER(ch.[Block])) AS Chksum
FROM (
SELECT TOP (LEN(@string)-2) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS i
FROM num AS a, num AS b, num AS c, num AS d
) AS o(Offset)
CROSS APPLY (
VALUES (SUBSTRING(@string, o.Offset, 3))
) AS ch([Block])
WHERE LEN(@string)>0
);
It’s very similar to the one we used before, but it returns a CHECKSUM() of three characters, starting at the Offset.
SELECT * FROM dbo.BLOCK_SPLIT('physical reads');
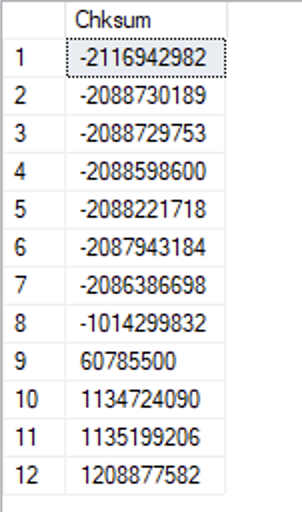
Same deal with the NO_PERFORMANCE_SPOOL as with the previous load, for the same reason:
TRUNCATE TABLE dbo.PostTitle_block;
INSERT INTO dbo.PostTitle_block (Id, Chksum)
SELECT p.Id, cs.Chksum
FROM dbo.Posts AS p
CROSS APPLY dbo.BLOCK_SPLIT(p.Title) AS cs
WHERE LEN(p.Title)>0
OPTION (NO_PERFORMANCE_SPOOL);
The resulting table is still about 5.4 GB, so no significant space saving. But let’s see how the search query fares:
CREATE OR ALTER PROCEDURE dbo.SearchPostTitle_block
@searchString nvarchar(300)
AS
CREATE TABLE #id (
Id int NOT NULL,
PRIMARY KEY CLUSTERED (Id)
);
WITH search AS (
SELECT Id, SUBSTRING(@searchString, 4, 300) AS searchString
FROM dbo.PostTitle_block AS t1
WHERE t1.Chksum=CHECKSUM(LOWER(SUBSTRING(@searchString, 1, 3)))
UNION ALL
SELECT search.Id, SUBSTRING(search.searchString, 4, 300) AS searchString
FROM search
INNER JOIN dbo.PostTitle_block AS t ON search.Id=t.Id
WHERE t.Chksum=CHECKSUM(LOWER(SUBSTRING(search.searchString, 1, 3)))
AND LEN(search.searchString)>=3)
INSERT INTO #id (Id)
SELECT DISTINCT Id
FROM search
WHERE LEN(searchString)<=3;
SELECT *
FROM dbo.Posts
WHERE Id IN (SELECT Id FROM #id)
AND Title LIKE N'%'+@searchString+N'%';
This time around, we’re creating a temp table for the #id resultsets, which contains candidates for the search result, based on hashes. These are not the final search results, so we need to join the #id table to the dbo.Posts table and perform a LIKE comparison to return the actual search results to the user.
The recursive common table expression looks in the dbo.PostTitle_block table, both for the anchor and the recursion. This table, as opposed to the previous character-based one, is much more selective, because each hash value represents the unique combination of three characters, rather than just a single character. So the anchor will be smaller by a factor of about 600 times, and every recursion will also be much more selective and narrow down the results much faster.
I’ll leave it to you if you want to try to further optimize this procedure. Hint: I would try ending the recursion before exhaustion – maybe finding 5 000 rows and matching them to dbo.Posts is faster than recursing down every single hash.
So how does it perform? The recursive common table expression has only a 2 MB memory grant, and uses about the same IO as the Non-Clustered Index Scan, and runs completes in just 75 ms!

Displaying the results is trivial.

The entire search runs for less than 200 ms.
Table '#id'. Scan count 0, logical reads 310, physical reads 0... Table 'Worktable'. Scan count 2, logical reads 42313, physical reads 0... Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0... Table 'PostTitle_block'. Scan count 1, logical reads 32393, physical reads 0... SQL Server Execution Times: CPU time = 78 ms, elapsed time = 75 ms. (155 rows affected) (3 rows affected) Table 'Posts'. Scan count 0, logical reads 638, physical reads 0... Table '#id'. Scan count 1, logical reads 2, physical reads 0... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 78 ms, elapsed time = 78 ms.
Conclusion
The performance will probably vary wildly with the data you’re searching, the length if the search string, and the number of search results, to name a few. Please don’t just go copy-pasting this code into your own environment without properly testing and evaluating it. Think of this post as a fun trial-and-error adventure.
I hope you learned something, or at least got a giggle out of it.
Did you read this ?https://sqlperformance.com/2017/09/sql-performance/sql-server-trigram-wildcard-search
I did not, but now that I read it, I’m not at all surprised that Paul White would have found a solution that at first glance also appears to outperform mine. 🙂
At University I was told to always start research with a literature review, I think both approaches have similarities & the checksum on substrings looks rather nice.
Procrastinatiom is the number one enemy of my productivity. Trust me when I say that any kind of literature review wouldn’t exactly make things easier. 😉
The thing I am worried about is are false positives.SELECT CHECKSUM(‘ADA’), CHECKSUM(‘ACQ’);
Yup, this is by design. You’ll notice that I make a second pass where I run an actual LIKE on the dbo.Posts table.