Can SQL Server piece together two different indexes in a single-table query, rather than just giving up and scanning a suboptimal clustered index? The short answer is: yes, in a fairly narrow band of conditions.
Let’s create a demo table to play with:
CREATE TABLE dbo.Demo (
ClusteredKey int NOT NULL,
A int NOT NULL,
B int NOT NULL,
C int NOT NULL,
D int NOT NULL,
CONSTRAINT ClusteredIndex PRIMARY KEY CLUSTERED (ClusteredKey)
);
WITH numbers AS (
SELECT i
FROM (VALUES (0), (1), (2), (3), (4),
(5), (6), (7), (8), (9)) AS n1(i))
--- 10 million rows:
INSERT INTO dbo.Demo (ClusteredKey, A, B, C, D)
SELECT x.i AS ClusteredKey, x.i/100 AS A, x.i/10 AS B, x.i AS C, x.i*10 AS D
FROM (
SELECT n1.i+n2.i*10+n3.i*100+n4.i*1000+n5.i*10000+n6.i*100000+n7.i*1000000 AS i
FROM numbers AS n1, numbers AS n2,
numbers AS n3, numbers AS n4,
numbers AS n5, numbers AS n6,
numbers AS n7
) AS x;
Here are two non-clustered indexes that we want to play around with:
CREATE INDEX Index1
ON dbo.Demo (B) INCLUDE (C)
WITH (DATA_COMPRESSION=PAGE);
CREATE UNIQUE INDEX Index2
ON dbo.Demo (C) INCLUDE (D)
WITH (DATA_COMPRESSION=PAGE);
You can see that as long as we stick to querying the B and C columns, Index1 will usually be perfectly sufficient. But if we query B, C and D, could we make use of Index1 and Index2, or will SQL Server give up and revert to just scanning the entire clustered index?
What I wanted vs. what I got
I want this query
SELECT B, AVG(1.0*D)
FROM dbo.Demo
GROUP BY B
ORDER BY B
OPTION (MAXDOP 1);
To generate a plan like this – joining Index1 with Index2 using column C:
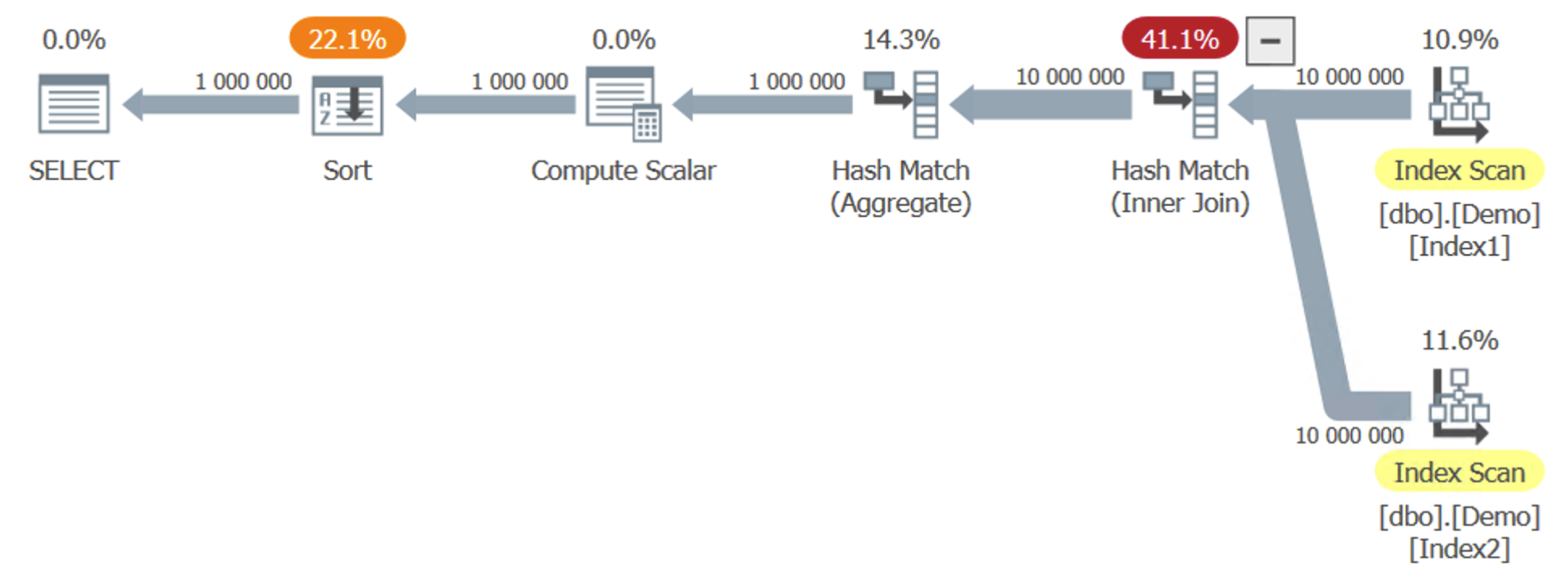
… but it ends up just looking like this:

Changing the query around a few times to include a subset of the table’s rows, I finally got the plan I was looking for:
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 113110
GROUP BY B
OPTION (MAXDOP 1);
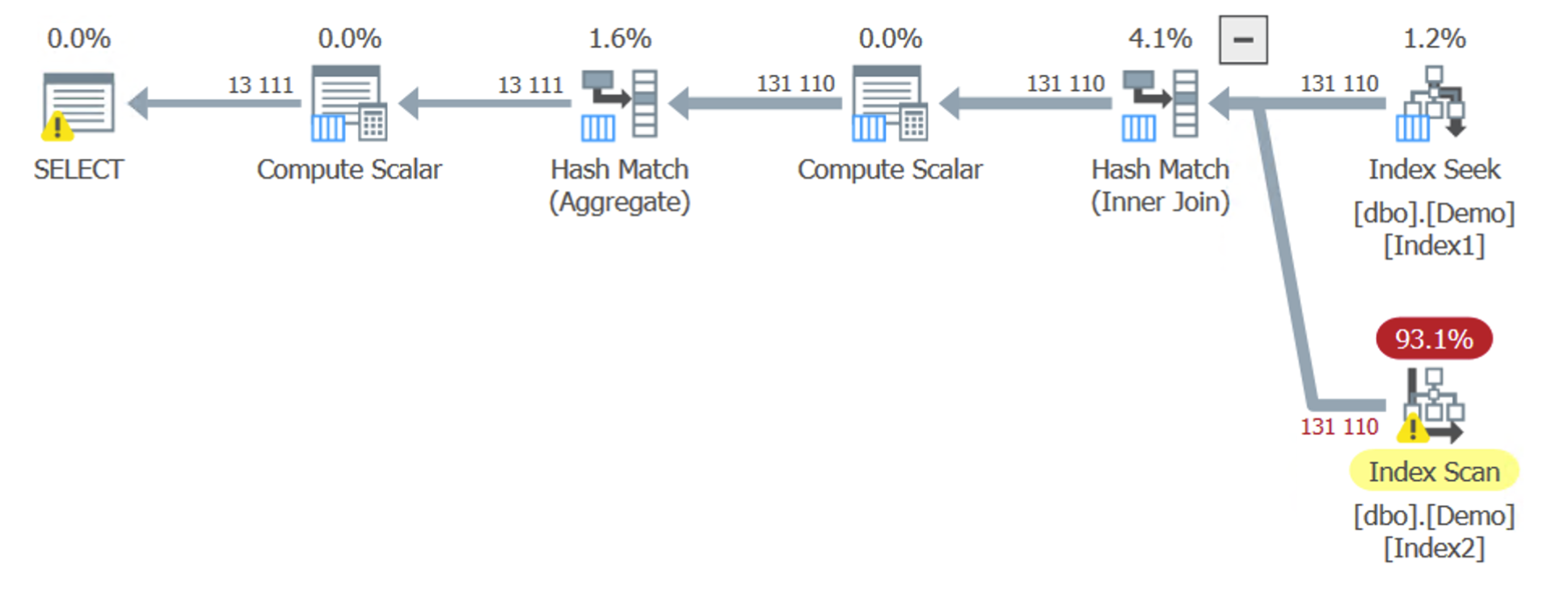
As with everything else, optimization is a game of thresholds. The SQL Server optimizer will try on a couple of different plans until it finds the one that works best. How many rows your selection generates will inform which plan is the most effective.
Three ranges, three outcomes
Most queries will resort to the brute force Clustered Index Scan.
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 113000
GROUP BY B
OPTION (MAXDOP 1)
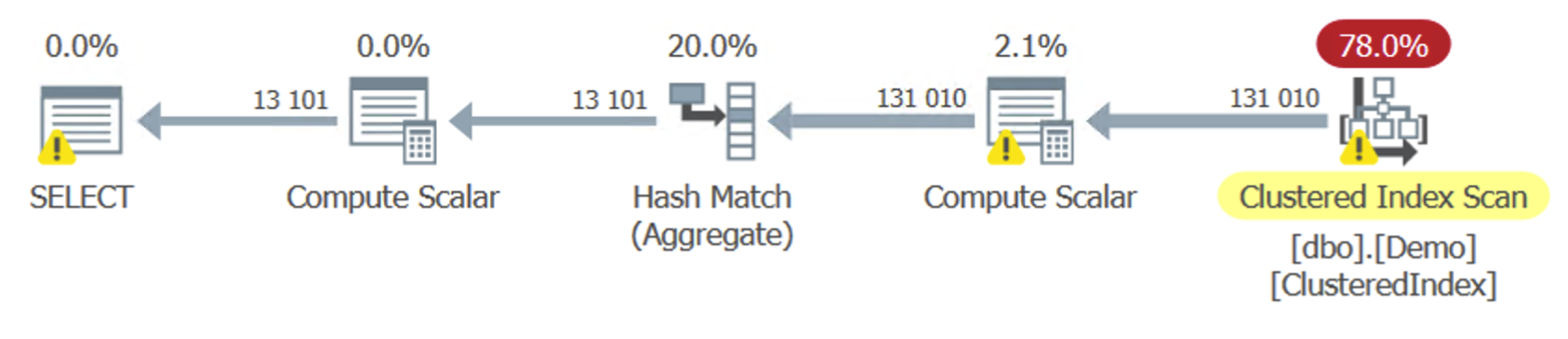
With a little less data to check for, we can benefit from an Index Seek on Index1 and an Index Scan on Index2. And while we’re still scanning one of the indexes, the overall I/O is reduced by about 50%. But we’re introducing a Hash Match (Join) operator, which adds CPU cost. The cost of this join operator is what makes this an efficient plan as long as we deal with relatively few rows, but makes it too expensive to use for the entire table.
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 113250
GROUP BY B
OPTION (MAXDOP 1)
If you use a relatively tiny selection of rows, SQL Server will find a Key Lookup most effective. The hypothesis of this post was to see if SQL Server could perform a “Key Lookup” on a non-clustered index – in this case on Index2, but this does not appear to be the case. Instead, we get a classic old Key Lookup on the clustered index:
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 101000
GROUP BY B
OPTION (MAXDOP 1)
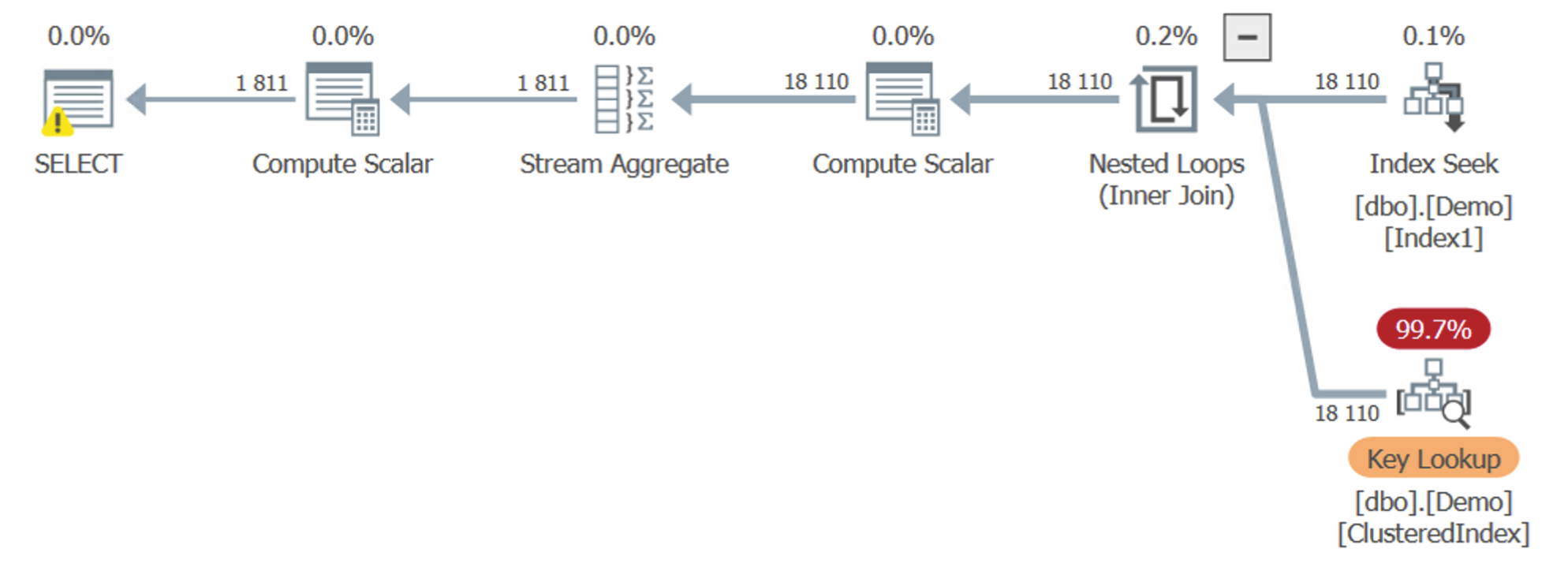
Conclusion
I was curious to see if there was such a thing as a “Key Lookup” on a non-clustered index, but now that I think of it, I don’t see what benefit it would bring. However, I was pleasantly surprised that SQL Server will actually construct a join between two indexes on the same table, even though the absolute majority of queries will either hit the full Clustered Index Scan or the Key Lookup scenario.
But occasionally, you could benefit from using this pattern explicitly by building out a query that does this for you when SQL Server won’t automatically choose the index join plan. Either because IOs are more important than CPU, or because you think you know something the SQL Server optimizer doesn’t. 😉
SELECT Demo.B, AVG([lookup].D)
FROM dbo.Demo WITH (INDEX=Index1)
INNER JOIN dbo.Demo AS [lookup] WITH (INDEX=Index2) ON Demo.C=[lookup].C
GROUP BY Demo.B
ORDER BY Demo.B
OPTION (MAXDOP 1);
2 comments