A popular form of organizing dimensions is in parent-child structures, also known as “unbalanced” or “ragged” dimensions, because any branch can have an arbitrary number of child levels. There are many advantages to this type of representation, but their recursive nature also brings some challenges. In this post, we’re going to look at circular references, and how you can trap them before they run out of control.
Suppose you have a tree hierarchy where (among other members) “3” is the parent of “8”, “8” is the parent of “B” and “B” is the parent of “E”. You could easily draw this as a branch structure where the members could be profit centers of a company, divisions of government, managers and employees, product lines, cell references in an Excel sheet or pretty much anything that can be described as a hierarchy.
3
--8
--B
--E
Now, if we say that “E” is the parent of “3”, we’ve created a circular reference, and we end up with an infinite recursion. What that means is that if you follow the tree from the root to the leaf level, you’ll end up going round and round in circles. In terms of a database query, that means that the query will go on forever until it either fills up your log file or tempdb, or until the maximum number of recursions (OPTION MAXRECURSION) is reached, whichever happens first.
The error message will look something like this:
Msg 530, Level 16, State 1, Line 1 The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
And that’s not a problem – you could trap this error using a TRY-CATCH block, but that won’t show you the actual circular reference in your table that you need to fix for your fancy hierarchy to work.
Some test data
Let’s create a temp table with some 14 000 rows in a parent-child structure.
CREATE TABLE #table (
id int NOT NULL,
name varchar(10) NOT NULL,
parent int NULL,
PRIMARY KEY CLUSTERED (id)
);
CREATE UNIQUE INDEX IX_table_parent
ON #table (parent, id)
INCLUDE (name);
--- Add 14 000 rows to the table:
INSERT INTO #table (id, name, parent)
SELECT x.n+v.id, v.name, x.n+v.parent
FROM (
SELECT TOP (999)
100000*ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n
FROM sys.columns
) AS x
CROSS JOIN (
VALUES (1, '1', NULL), (2, '2', 1),
(3, '3', 14), (4, '4', 1),
(5, '5', 2), (6, '6', 2),
(7, '7', 3), (8, '8', 3),
(9, '9', 5), (10, 'A', 7),
(11, 'B', 8), (12, 'C', 9),
(13, 'D', 10), (14, 'E', 11)
) AS v(id, name, parent);
--- Intentionally create a circular reference:
UPDATE #table SET parent=700014 WHERE id=700003;
Finding the recursion
If you’re new to recursive common table expressions, this next part is not going to make any sense at all to you, so go ahead and read up on that first.
The plan for our query is simple enough. Start with an anchor row (any row can be an anchor), and from that row, find its children, their children, etc until we either reach the leaf level – or until we get back to the anchor again. If we reach the leaf level, all is fine. If we come back to the anchor, we’ve found a circular reference. Then we’ll want to have a trail of “breadcrumbs”, a path, of how we got there.
Break any one of those links in that path, and you’ve resolved the circular reference.
Let’s look at all the pieces one at a time.
The anchor
SELECT parent AS start_id, id, CAST(name AS varchar(max)) AS [path] FROM #table
Every row is a potential anchor. In this result set, we have three columns. The “start_id” is the id of the anchor row, which we’ll keep throughout the recursion. Whenever our recursion returns to “start_id”, we’ve found a circular reference.
“id” is the current row of the recursion. It starts as the child of “start_id”, then its grandchild, great grandchild, and so on.
“path” is a textual representation, our trail of breadcrumbs. This will be used to show a human reader how a potential circular reference happened.
The recursion
SELECT rcte.start_id, t.id, CAST(rcte.[path]+' -> '+t.name AS varchar(max)) AS [path] FROM rcte INNER JOIN #table AS t ON t.parent=rcte.id WHERE rcte.start_id!=rcte.id
The recursion finds all children of “id”, thereby traversing the tree towards the leaf level. “start_id” stays the same (it’s our anchor), “id” is the new child row, and we’re adding plaintext breadcrumbs to the end of the “path” column.
This recursion will end when there are no more children available, which means that we’ve reached the leaf level.
But we also need it to stop if we were to find a circular reference, and that’s why we’ve added that last WHERE clause. When “id” is “start_id”, we’ve gone full circle, and it’s time to pull on the brakes.
The complete solution
Putting it all together, here’s the final product:
WITH rcte AS ( --- Anchor: any row in #table could be an anchor --- in an infinite recursion. SELECT parent AS start_id, id, CAST(name AS varchar(max)) AS [path] FROM #table UNION ALL --- Find children. Keep this up until we circle back --- to the anchor row, which we keep in the "start_id" --- column. SELECT rcte.start_id, t.id, CAST(rcte.[path]+' -> '+t.name AS varchar(max)) AS [path] FROM rcte INNER JOIN #table AS t ON t.parent=rcte.id WHERE rcte.start_id!=rcte.id) SELECT start_id, [path] FROM rcte WHERE start_id=id OPTION (MAXRECURSION 0); -- eliminates "assert" operator.
That MAXRECURSION hint is there to simplify the plan. You trust me, right?
Here’s the output from the sample data.
start_id path ---------- -------------------- 700014 3 -> 8 -> B -> E 700011 E -> 3 -> 8 -> B 700008 B -> E -> 3 -> 8 700003 8 -> B -> E -> 3
You may notice that it’s actually the same recursion, represented in four different ways. You could argue that this is by design, or you could spend time trying to eliminate the “duplicates” of the chain.
The query plan
Thanks to some optimal indexing, we’ve found a very efficient plan, with zero memory grant and no blocking operators.
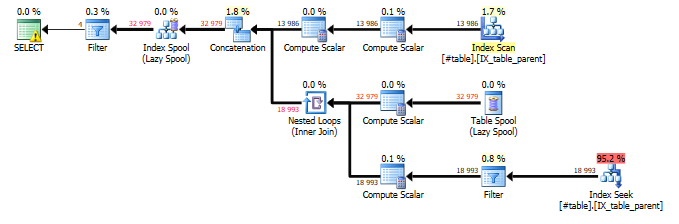
Here’s how to read the plan: For the sake of brevity, you can completely ignore the Compute Scalar operators, which are just scalar operations like string parsing, incrementing counters, etc.
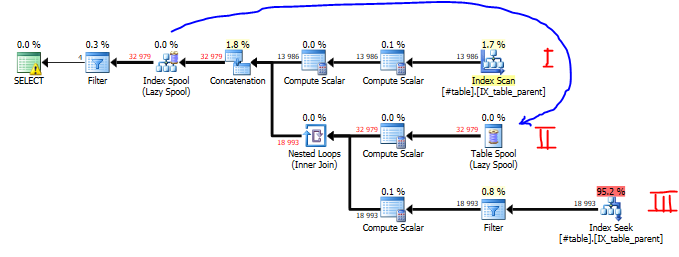
I: The Index scan collects all the anchors of the query. The anchor rows move left in the diagram until they’re stored in an Index Spool, which is kind of an internal high-performance temp table.
II: The rows that were just stored in the Spool are then retrieved, and joined…
III: … using an Index Seek (finding rows that are children of each row from II). The filter operator then makes sure to eliminates rows where “start_id” is equal to “id” (corresponding to the WHERE clause in the recursive part).
This whole process generates even more rows that are moved into the Index Spool, and the process repeats itself over and over, until there are no more recursions. Finally, the top-left Filter operator isolates only rows where “id” equals “start_id”, so we only see just the circular references we’re looking for.
Indexing
Making a recursive query like this run smoothly relies on an index on (parent_id, id). This allows the Nested Loop operator in the recursive part of the CTE to issue an Index Seek on all rows with a specific “parent_id”, rather than having to scan through the entire table looking for matching children.
Remember that Nested Loop Join means that anything that happens “below” the operator in the graphical plan is performed once for each row, so performance here is key.
I really do not like this approach. It is called an adjacency list model and its how non-SQL programmers model their old pointer chain programming in SQL when their first learning.
The design is nonrelational, has to be traversed (SQL is a declarative language. We do not do traversals) and it eats up an awful lot of resources. Another problem of course is that it is flawed in your example, all of the nodes in the tree are distinct. Now consider a parts explosion of a 747 airplane were number five machine screws appear in literally hundreds of places.
Unfortunately the DDL you posted is not a table! It has no key and you did not even bother with a check constraint to prevent apparent from being its own child. This is very poor design.
If you look up the nested set model for hierarchies you get a correct design. The nested set model separates the nodes from the structure (remember the first day of ER modeling? Entities and their relationships appear in separate tables).
You can literally use declarative constraints to prevent any cycles in your data.
Hi, Joe! Thanks for your feedback.
The DDL is, in my humble opinion, indeed a table, and it does have a primary key. Unfortunately, it’s not possible to create foreign key constraints on temp tables, and even if I did create check constraints and/or a self-referencing FK on the table, I still don’t see how to purely declaratively prevent circular references.
Remember that I’m designing a solution to display circular references (for troubleshooting purposes, for instance), not necessarily to just prevent them.
I would love your thoughts on how to improve the solution.
No you do not have a key. The key is, by definition, a subset of attributes of the entity being modeled in the table. Your vague generic physical role locator is an integer; an integer is a numeric data type; numeric datatypes are used for quantities and magnitudes. They are not used for identifiers. What you are doing is faking a pointer in 1960’s assembly language program. Furthermore, the rest of your columns are wrong. There is no such thing as a “generic name” in RDBMS; this model of data is based on the laws of logic in the first law of logic is the law of identity. To be is to be something in particular, to be nothing in particular or everything in general is to be nothing at all. Remember that from your freshman logic class?
Then the parent node should be the same data type as the child node. The role of parent or child does not completely change the nature of a node. But in your world, the parents node becomes a magnitude or quantity. Think about how insane that is. Your unique index is simply a bad attempt to somehow fix an incredibly bad design.
CREATE TABLE Generic_Tree
(vague_generic_physical_row_locator INTEGER NOT NULL PRIMARY KEY,
node_name VARCHAR(10) NOT NULL,
parent_node_vague_generic_physical_row_locator INTEGER);
REATE UNIQUE INDEX Fake_Key
ON Generic_Tree(vague_generic_physical_row_locator_)
INCLUDE (node_name);
>> I still don’t see how to purely declaratively prevent circular references.< 0),
rgt iNTEGER NOT NULL UNIQUE
CHECK (rgt > 1),
CHECK (lft < rgt),
UNIQUE (lft, rgt));
See how the combination of left and right constraints keep everything nested? The unique (lft, rgt) constraint could be the primary key, if you are hierarchy is essentially a fancy coordinate system in a two dimensional space. But otherwise the node name could be the primary key. If this is a personnel model in which everyone is unique and holds only one position in the hierarchy.
Since everything can be done with between predicates, the indexing makes this run extremely fast. Furthermore, by separating the nodes from the data structure (relationship), we get a very small compact table to search they can be they can have a covering index.
You might want to get my book on trees and hierarchies in SQL.
A bit of graph theory here. One of the properties a tree is that the number of edges equals the number of nodes -1 or E= (N-1).
This is actually pretty easy to write in SQL, but you have to remember to remove the possibility that a node can be its own parent simple check constraint. Imagine a graph made up of four nodes; three of them are connected in the triangle and the fourth node sits by itself with no edge at all. It would still meet this condition. Very quickly, here is the code:
CREATE TABLE Adjaceny_List
(node_name CHAR(1) NOT NULL PRIMARY KEY,
parent_node_name CHAR(1),
CHECK (node_name CHAR(1) parent_node_name));
INSERT INTO Adjaceny_List
VALUES
(‘1’, NULL),
(‘2’, ‘1’),
(‘3’, ‘E’),
(‘4’, ‘1’),
(‘5’, ‘2’),
(‘6’, ‘2’),
(‘7’, ‘3’),
(‘8’, ‘3’),
(‘9’, ‘5’),
(‘A’, ‘7’),
(‘B’, ‘8’),
(‘C’, ‘9’),
(‘D’, ‘A’),
(‘E’, ‘B’);
SELECT COUNT(*) AS edge_cnt FROM Adjaceny_List ;
SELECT COUNT(*)AS node_cnt
FROM (SELECT node_name
FROM Adjaceny_List
UNION
SELECT parent_node_name
FROM Adjaceny_List) AS X(node_name);
edge_cnt = 14;
node_cnt = 15
Thanks!
I encountered this problem and hoped that your article would help. Unfortunately, it assumes that the circular reference is to the anchor node which is not necessarily the case…it could be to any prior node in the chain.
No, because the anchor node is defined in the first part of the recursive cte, so it can be any node in the table. Feel free to post an example where the query doesn’t work, and I’ll take a look at it.
Thanks for this post !
You’ve got an infinite loop in this case :
3 -> 8 -> B -> E -> 8 -> B -> E -> 8 -> B -> E -> …..
3 (the start_id) is never encountred, so the recursion never ends (WHERE rcte.start_id!=rcte.id)
I haven’t looked at this post for some time, but if memory serves, the cte will create an anchor on every node, including 8, so it should detect the infinite recursion.
Ah, I see what you mean. I guess you would add a TOP(1) or something to the query output to resolve it. After all, I guess we’re really just looking for a pointer to an infinite loop, not an exhaustive list of them. 🙂