We’ve talked a lot about optimizing queries and query performance, but we haven’t really touched that much on the storage and data modelling aspects. In this series of post, I’ll run through some basic tips on how you can more efficiently model and store your data, which may come in particularly handy when you’re working with large databases and large transaction volumes, but a lot of it also makes good design sense in smaller databases.
In this first article, we’ll cover the normalized data model.
Normalize it
This is often the first and most important tip for storing data efficiently. Unless you’re building a star-schema BI solution, your data should probably be normalized. Normalized data means that you separate the different elements in your data model and place them in a bunch of relational tables, linked by foreign key constraints, so that the same information does not appear twice anywhere in the database.
Modelling a normalized database is a core concept for relational databases, so it’s important to have a good understanding of this.
Here’s an example of a completely denormalized table, i.e. a single table that holds all the data. In essence, it’s just a flat file:
CREATE TABLE Denorm.person (
[ID] int IDENTITY(1, 1) NOT NULL,
firstName varchar(100) NOT NULL,
lastName varchar(100) NOT NULL,
streetAddress varchar(100) NULL,
postalAddress varchar(100) NOT NULL,
jobTitle varchar(100) NULL,
companyName varchar(100) NULL,
employedSince date NULL,
PRIMARY KEY CLUSTERED ([ID])
);
INSERT INTO Denorm.person (firstName, lastName, streetAddress,
postalAddress, jobTitle, companyName, employedSince)
VALUES ('Pilar', 'Ackerman', '5407 Cougar Way', '98104 Seattle WA',
'Developer', 'AdventureWorks', {d '2002-08-12'}),
('Gavin', 'Jenkins', '3173 Darlene Drive', '94010 Burlingame CA',
'Developer', 'AdventureWorks', {d '2008-12-01'}),
('Jamie', 'Torres', '1248 Cougar Way', '98104 Seattle WA',
'Manager', 'AdventureWorks', {d '2005-03-13'});
With this denormalized setup, if a property changes name, say from “Developer” to “Software engineer”, you’d have to update multiple rows in the table, which is not only inefficient, but can potentially cause referential inconsistencies, i.e. that one person is a “Developer” and another a “Software engineer”. This gets worse as the number of properties increases, particularly when people move, change their last name, phone number, etc.
If you were to build a normalized version of this data, you would split it into separate tables for persons, postal codes, locations (addresses), companies, job titles and employments. Here’s an example of a normalized data model, complete with foreign key constraints that define the relations between the tables:
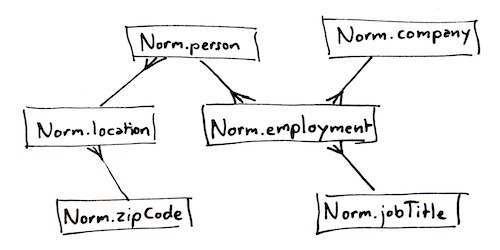
--- A table of zip codes: CREATE TABLE Norm.zipCode ( zipCode int NOT NULL, postalAddress varchar(100) NOT NULL, PRIMARY KEY CLUSTERED (zipCode) ); INSERT INTO Norm.zipCode (zipCode, postalAddress) VALUES (94010, 'Burlingame CA'), (98104, 'Seattle WA'); --- And addresses that go with those zip codes: CREATE TABLE Norm.location ( [ID] int NOT NULL, streetAddress varchar(100) NULL, zipCode int NOT NULL, PRIMARY KEY CLUSTERED ([ID]), FOREIGN KEY (zipCode) REFERENCES Norm.zipCode (zipCode) ); INSERT INTO Norm.location ([ID], streetAddress, zipCode) VALUES (1001, '5407 Cougar Way', 98104), (1002, '3173 Darlene Drive', 94010), (1003, '1248 Cougar Way', 98104); --- And finally, connect a person to the address: CREATE TABLE Norm.person ( [ID] int NOT NULL, firstName varchar(100) NOT NULL, lastName varchar(100) NOT NULL, location_ID int NOT NULL, PRIMARY KEY CLUSTERED ([ID]), FOREIGN KEY (location_ID) REFERENCES Norm.location ([ID]) ) INSERT INTO Norm.person ([ID], firstName, lastName, location_ID) VALUES (9001, 'Pilar', 'Ackerman', 1001), (9002, 'Gavin', 'Jenkins', 1002), (9003, 'Jamie', 'Torres', 1003); --- Here's table of companies... CREATE TABLE Norm.company ( [ID] int NOT NULL, companyName varchar(100) NOT NULL, PRIMARY KEY CLUSTERED ([ID]) ); INSERT INTO Norm.company ([ID], companyName) VALUES (1, 'AdventureWorks'); --- ... some job titles, CREATE TABLE Norm.jobTitle ( [ID] int NOT NULL, jobTitle varchar(100) NOT NULL, PRIMARY KEY CLUSTERED ([ID]) ); INSERT INTO Norm.jobTitle ([ID], jobTitle) VALUES (2001, 'Developer'), (2002, 'Manager'); --- .. and we'll connect people, jobs and companies in --- an "employment" table: CREATE TABLE Norm.employment ( company_ID int NOT NULL, person_ID int NOT NULL, jobTitle_ID int NOT NULL, employedSince date NOT NULL, employedUntil date NULL, PRIMARY KEY CLUSTERED (person_ID, employedSince), FOREIGN KEY (company_ID) REFERENCES Norm.company ([ID]), FOREIGN KEY (jobTitle_ID) REFERENCES Norm.jobTitle ([ID]), FOREIGN KEY (person_ID) REFERENCES Norm.person ([ID]) ); INSERT INTO Norm.employment (company_ID, person_ID, jobTitle_ID, employedSince) VALUES (1, 9001, 2001, {d '2002-08-12'}), (1, 9002, 2001, {d '2008-12-01'}), (1, 9003, 2002, {d '2005-03-13'});
The downside with normalization is that when you query the data, you need to join a potentially large number of tables. However, in most cases, this is offset by the advantage that normalized data isn’t duplicated – there’s exactly one row in the entire database that says “AdventureWorks”. So, if the company changes name, you only have to update this one record.
As with most things, normalization can be taken to extremes as well (the above example is, for demonstrational purposes, a bit exaggerated in terms of normalization), so just remember to apply common sense when designing the data model.
Denormalized data models
In this context, it’s fair to mention the denormalized star-schema model as well.
Once you’re comfortable modelling databases, you will even find that some normalization, although logical and pretty to look at, may carry a performance penalty, perhaps in terms of excessive table joining. Or it may be hard for end-users to understand an overly elaborate data model. This is the reason that data warehouses and data marts, which are designed to be very easy to understand and use even for not-so-skilled users, are commonly built as denormalized star schemas.
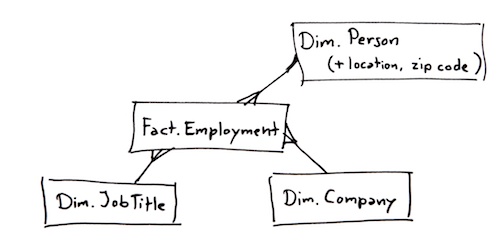
A star-schema database has the advantage that you need very few, if any, table joins to extract aggregates of large volumes of data, which makes it excellent for use in datawarehousing applications, but you will have to manage data consistency in the dimension tables, because properties of dimension members are stored once for each dimension member.
Stay tuned for next week’s article on partitioning!