Can you apply gaps and islands logic on a string? Sure you can.
What’s the problem we’re trying to solve?
Suppose you have a delimited string input that you want to split into its parts. That’s what STRING_SPLIT() does:
DECLARE @source nvarchar(max)='Canada, Cape Verde, '+
'Central African Republic, Chad, Chile, China, Colombia, Comoros';
SELECT TRIM([value]) AS [Country]
FROM STRING_SPLIT(@source, ',');
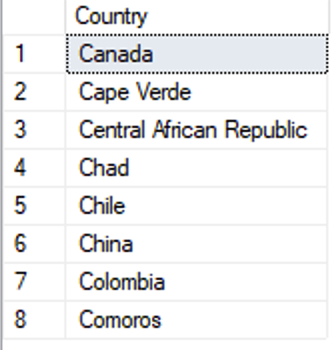
Simple enough. But delimited lists are tricky, because the delimiter could exist in the name itself. Look for yourself what happens when we add the two Congos to the list:
DECLARE @source nvarchar(max)='Canada, Cape Verde, '+
'Central African Republic, Chad, Chile, China, Colombia, Comoros, '+
'Congo, Democratic Republic of the, Congo, Republic of the';
SELECT TRIM([value]) AS [Country]
FROM STRING_SPLIT(@source, ',');

You can solve this by quoting the problematic names. In T-SQL, we use square brackets to quote object names that contain white spaces, or other delimiters.
DECLARE @source nvarchar(max)='Canada, Cape Verde, '+
'Central African Republic, Chad, Chile, China, Colombia, Comoros, '+
'[Congo, Democratic Republic of the], [Congo, Republic of the]';
SELECT TRIM([value]) AS [Country]
FROM STRING_SPLIT(@source, ',');
… but STRING_SPLIT() does not natively handle quoting characters.

Roll your own quoting-aware STRING_SPLIT()
Just like Itzik Ben-Gan’s brilliant gaps-and-islands solution, we’ll need to process this in steps. First, let’s just split the string by the delimiter, even if that means splitting a quoted string:
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
)
SELECT *
FROM s1;
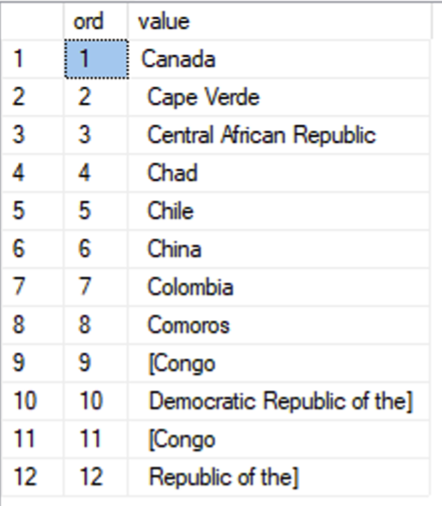
Now, let’s compute how many square brackets we can find for each item. This will give us the quote level, or actually, the relative change of the quote level. “[” means the quote level increases by 1, “]” means it decreases by 1:
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
),
s2 AS (
SELECT ord, [value],
LEN(REPLACE([value], N']', N''))-
LEN(REPLACE([value], N'[', N'')) AS quote_level_change
FROM s1
)
SELECT *
FROM s2;
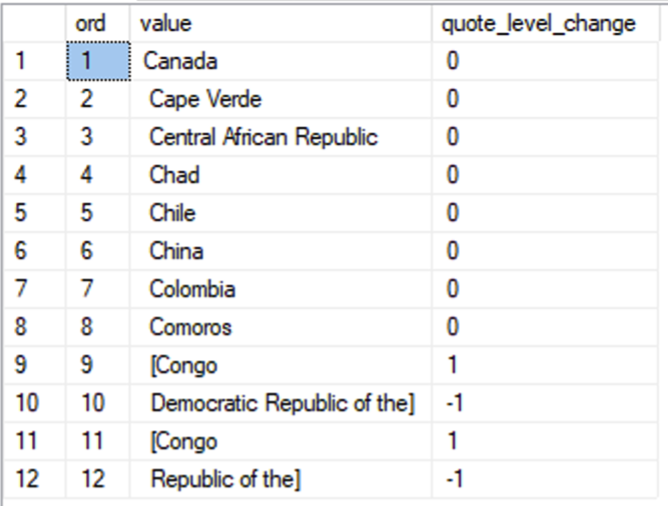
Now, if we create a running total of the quote_level_change column, we get the actual quote level at the end of each respective line:
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
),
s2 AS (
SELECT ord, [value],
LEN(REPLACE([value], N']', N''))-
LEN(REPLACE([value], N'[', N'')) AS quote_level_change
FROM s1
),
s3 AS (
SELECT ord, [value],
SUM(quote_level_change) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS quote_level
FROM s2
)
SELECT *
FROM s3;
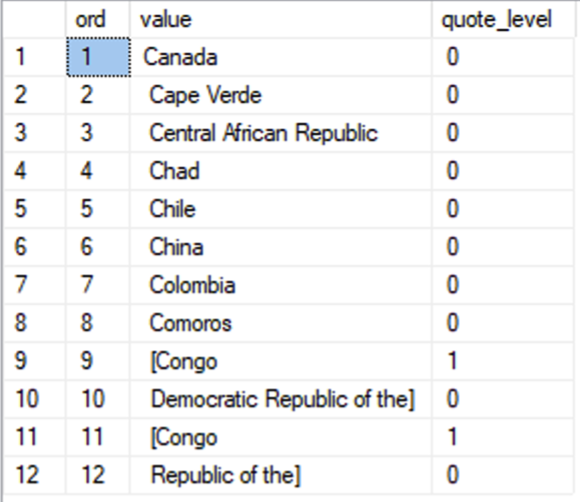
Now, you can think of the this result set as a number of “groups”, where each group has one or more lines. Whenever a preceding line has a quote level of 0, a new group begins. Here’s what that looks like in T-SQL:
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
),
s2 AS (
SELECT ord, [value],
LEN(REPLACE([value], N']', N''))-
LEN(REPLACE([value], N'[', N'')) AS quote_level_change
FROM s1
),
s3 AS (
SELECT ord, [value],
SUM(quote_level_change) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS quote_level
FROM s2
),
s4 AS (
SELECT ord, [value], (CASE
WHEN LAG(quote_level, 1, 0) OVER (ORDER BY ord)=0
THEN 1 ELSE 0 END) AS is_new_group
FROM s3
)
SELECT *
FROM s4;
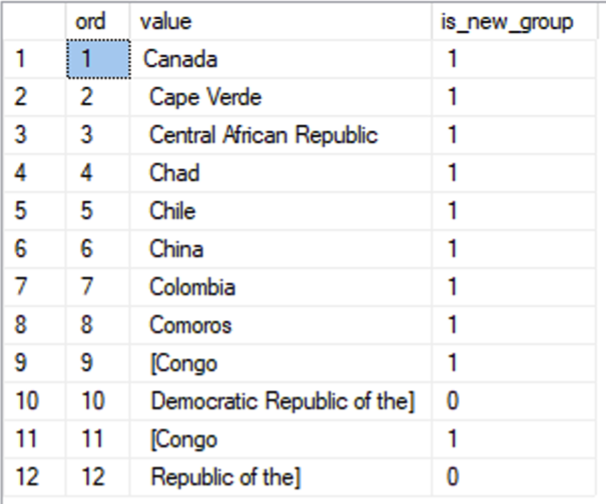
So, to get a “group number”, all you have to do is create a running total of the “is_new_group” column:
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
),
s2 AS (
SELECT ord, [value],
LEN(REPLACE([value], N']', N''))-
LEN(REPLACE([value], N'[', N'')) AS quote_level_change
FROM s1
),
s3 AS (
SELECT ord, [value],
SUM(quote_level_change) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS quote_level
FROM s2
),
s4 AS (
SELECT ord, [value], (CASE
WHEN LAG(quote_level, 1, 0) OVER (ORDER BY ord)=0
THEN 1 ELSE 0 END) AS is_new_group
FROM s3
),
s5 AS (
SELECT ord, [value],
SUM(is_new_group) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS group_number
FROM s4
)
SELECT *
FROM s5;
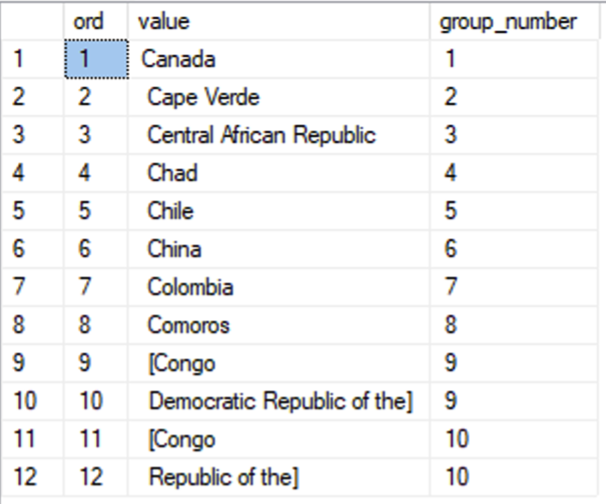
Now, all we need to do is to STRING_AGG() these lines together again. We want one result row for each “group_number”:
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
),
s2 AS (
SELECT ord, [value],
LEN(REPLACE([value], N']', N''))-
LEN(REPLACE([value], N'[', N'')) AS quote_level_change
FROM s1
),
s3 AS (
SELECT ord, [value],
SUM(quote_level_change) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS quote_level
FROM s2
),
s4 AS (
SELECT ord, [value], (CASE
WHEN LAG(quote_level, 1, 0) OVER (ORDER BY ord)=0
THEN 1 ELSE 0 END) AS is_new_group
FROM s3
),
s5 AS (
SELECT ord, [value],
SUM(is_new_group) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS group_number
FROM s4
)
SELECT TRIM(STRING_AGG([value], N',') WITHIN GROUP (ORDER BY ord)) AS [value]
FROM s5
GROUP BY group_number
ORDER BY group_number;

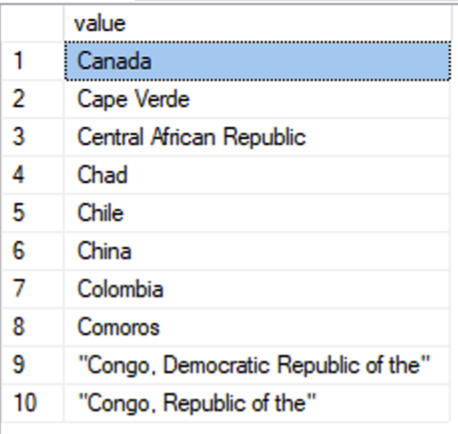
What about “regular” quotes?
Using square brackets is pretty handy, because it allows us to add and subtract from the quote level as we go. That obviously won’t work when the opening and closing character of a quote is the same, such as with full quotes (“) or apostrophes (‘).
For “regular” quotes, we can instead just add create a “quote character count” that increments for every quote character, whether it’s opening or closing. Take that total modulo 2 (quote_char_count%2) and you get an output of 0 or 1, indicating if we’re inside a quote or not.
If we plug that into our logic above, the change is relatively small:
DECLARE @source nvarchar(max)='Canada, Cape Verde, '+
'Central African Republic, Chad, Chile, China, Colombia, Comoros, '+
'"Congo, Democratic Republic of the", "Congo, Republic of the"';
WITH s1 AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ord, [value]
FROM STRING_SPLIT(@source, N',')
),
s2 AS (
SELECT ord, [value],
LEN([value])-LEN(REPLACE([value], N'"', N'')) AS quote_char_count
FROM s1
),
s3 AS (
SELECT ord, [value],
SUM(quote_char_count) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING)%2 AS quote_level
FROM s2
),
s4 AS (
SELECT ord, [value], (CASE
WHEN LAG(quote_level, 1, 0) OVER (ORDER BY ord)=0
THEN 1 ELSE 0 END) AS is_new_group
FROM s3
),
s5 AS (
SELECT ord, [value],
SUM(is_new_group) OVER (
ORDER BY ord ROWS UNBOUNDED PRECEDING) AS group_number
FROM s4
)
SELECT TRIM(STRING_AGG([value], N',') WITHIN GROUP (ORDER BY ord)) AS [value]
FROM s5
GROUP BY group_number
ORDER BY group_number;
The query plan must be amazing?
Funny you should ask. The plan actually only contains a single Sort operator, at the very end of the plan.


That said, if performance is a critical metric when you’re doing these kinds of things in T-SQL, maybe you should fix this somewhere else in your ETL chain.
Takeaway
Window functions can do strange and amazing things that you may never have thought of in terms of set-based SQL code. The eye-opener for me was a presentation by Itzik Ben-Gan many years ago, where he demonstrated how he used window functions to solve problems like gaps and islands, packing, and others.
I always think of window functions as “T-SQL 2.0” – once you think you’ve mastered the regular DML code, there’s a whole new world of window functions to discover.
Very nice Daniel!
It reminds me of the times before SQL Server had JSON support and I tried to write my own JSON-parser in T-SQL with a similar use of window functions. It was neither pretty nor fast :D.
Speaking of JSON, I’ve solved this issue by escaping (with ‘\’) instead of quoted names. I transform the string into a JSON array and then use OPENJSON(), instead of using STRING_SPLIT(). I do this to be able to return guaranteed correct order of the elements. The function also allows for multiple characters as separator.
create or alter function dbo.split_string (
@string nvarchar(max),
@separator nvarchar(128)
)
returns table
as return (
select idx = cast(j.[key] as bigint) + 1
,[value] = replace(j.[value], nchar(17), @separator)
from openjson(
N'[“‘ +
replace(
replace(
string_escape(@string, ‘json’),
string_escape(N’\’ + @separator, ‘json’),
string_escape(nchar(17), ‘json’)
),
string_escape(@separator, ‘json’),
N'”,”‘
) +
N'”]’
) j
);
You would use it like this:
declare @string nvarchar(max) = N’Canada, Cape Verde, ‘ +
‘Central African Republic, Chad, Chile, China, Colombia, Comoros, ‘ +
‘Congo\, Democratic Republic of the, Congo\, Republic of the’;
select idx, [value] from dbo.split_string(@string, N’,’);
I have no idea of how performant this is compared to STRING_SPLIT(), but it’s fast enough for my purposes 🙂
Woah, the what-now? I had no idea about STRING_ESCAPE() – I will definitely look closer at this function!
Cool! 🙂
I just added an easier-to-read version of the function here: https://github.com/stonebr00k/t_sql_utils/blob/main/_/dbo/function/table_valued/split_string.sql
This is a good article and thanks for posting it, Daniel. I just want to remind you and everyone else of what the documentation clearly states.
From https://docs.microsoft.com/en-us/sql/t-sql/functions/string-split-transact-sql in the REMARKS section…
“The output rows might be in any order. The order is not guaranteed to match the order of the substrings in the input string.”
That’s why so many of us railed against the function when it first came out. Without an “ordinal position” to sort the return on, there is no guarantee that any generated ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) will produce the correct order.
Yes, they finally fixed that but only in some of the Azure products and they’re closed the “feedback” item as done without implementing it in SQL Server (the non-Azure product).