I’ve solved this puzzle a number of times, but I’ve never really been quite happy with the result. It was either too slow, too much code, too hard to understand. So here’s a fresh take at computing the time-to-payment on a large amount of invoices, with multiple, overlapping, partial payments.
Cash flow analysis, simplified.
The last day of the month is usually the best day of the month if you’re a consultant – because that’s when you bill your clients for all that hard work you’ve done in the last few weeks. Yeah, I know what you’re thinking, but consultants are people, too, and we need to put food on our family, just like everybody else.
But I digress. Part of keeping track of customer invoices is to know who paid up and who’s dragging their feet. For a small business, that can normally be resolved with a quick glance at your bank statement, but for a company that sends dozens, or hundreds, or even thousands of invoices every month, that’s work that sooner or later needs to be automated.
Better yet, if you have enough data to work with, you can start analyzing your customers’ payment patterns and make changes to optimize your invoice flows.
Some sample data
Let’s create a sample table with accounting transactions. There’s a date, a customer code, an invoice number and an amount. Positive amounts are invoices, negative amounts are payments.
CREATE TABLE dbo.InvoiceTransactions (
TransactionID int NOT NULL,
TransactionDate date NOT NULL,
InvoiceNo int NULL,
Customer varchar(10) NOT NULL,
Amount numeric(10, 2) NOT NULL,
PRIMARY KEY CLUSTERED (TransactionID)
);
This huge block of code just fills the table with some random transactions. You can tinker with the parameters if you want, but the defaults will create about 75 000 invoices and a little over 250 000 payments.
DECLARE @CustomerCount int=2500, --- How many customers
@InvoiceCount int=60, --- How many invoices for each customer
@PaymentCount int=5, --- Max number of payments for a single invoice
@DayCount int=2000, --- First invoice date, no of days prior to today
@PaymentTerm int=30; --- Normal number of settlement days for invoices
WITH n AS (
SELECT 1 AS i UNION ALL
SELECT i+1 FROM n WHERE i<@CustomerCount)
INSERT INTO dbo.InvoiceTransactions (TransactionID, TransactionDate, InvoiceNo, Customer, Amount)
SELECT ROW_NUMBER() OVER (ORDER BY pay.TransactionDate, inv2.Customer) AS TransactionID,
pay.TransactionDate,
(CASE WHEN pay.Amount>0 THEN DENSE_RANK() OVER (ORDER BY inv2.InvoiceDate, inv2.Customer) END) AS InvoiceNo,
inv2.Customer,
pay.Amount
FROM (
SELECT inv.Customer,
inv.InvoiceAmount,
inv.Payments,
inv.InvoiceSeq,
DATEADD(month,
inv.InvoiceSeq,
MAX(inv.InvoiceDate) OVER (PARTITION BY inv.Customer)) AS InvoiceDate
FROM (
SELECT CONVERT(varchar(10), CONVERT(binary(2), cust.i), 2) AS Customer,
ROUND(100000.00*RAND(CHECKSUM(NEWID())), 0) AS InvoiceAmount,
FLOOR(SQRT(20*RAND(CHECKSUM(NEWID())))) AS Payments,
DATEADD(day, FLOOR(@DayCount*RAND(CHECKSUM(NEWID()))), DATEADD(day, -@DayCount-@InvoiceCount*30/2, CAST(SYSDATETIME() AS date))) AS InvoiceDate,
inv.i AS InvoiceSeq
FROM n AS cust
INNER JOIN n AS inv ON inv.i<=@InvoiceCount
) AS inv
) AS inv2
CROSS APPLY (
SELECT 1+FLOOR(@PaymentCount*SQRT(RAND(inv2.InvoiceAmount))) AS PaymentCount
) AS pc
CROSS APPLY (
SELECT inv2.InvoiceDate AS TransactionDate,
inv2.InvoiceAmount AS Amount
UNION ALL
SELECT DATEADD(day, 20*n.i, inv2.InvoiceDate) AS TransactionDate,
-ROUND(inv2.InvoiceAmount/pc.PaymentCount, 2)
-(CASE WHEN n.i=pc.PaymentCount
THEN inv2.InvoiceAmount-pc.PaymentCount*ROUND(inv2.InvoiceAmount/pc.PaymentCount, 2)
ELSE 0.0 END) AS Amount
FROM n
WHERE n.i<=pc.PaymentCount
) AS pay
WHERE inv2.InvoiceDate<=SYSDATETIME()
AND pay.TransactionDate<=SYSDATETIME()
OPTION (MAXRECURSION 0);
Let simmer for a minute or two.
Looking at the data
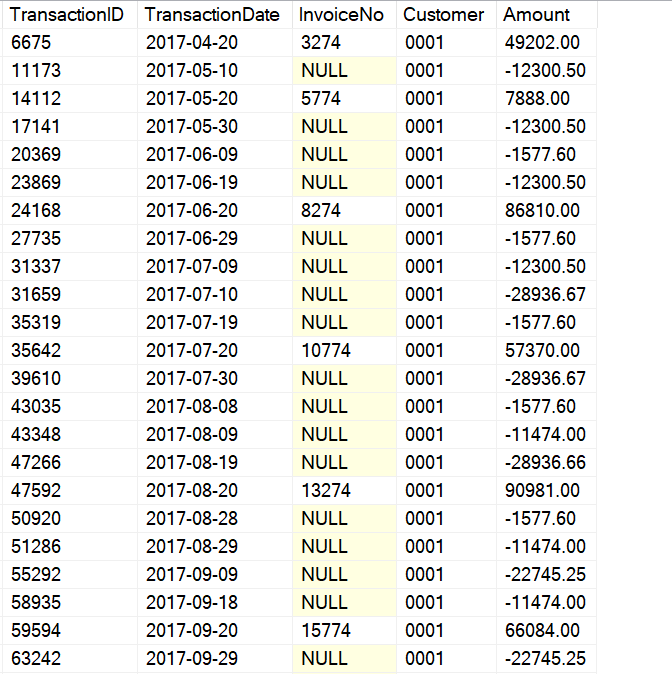
Here’s an example customer. You’ll notice right off the bat that we’re sending this customer an invoice every day on the 20th of the month. To add some complexity, the customer will arbitrarily pay parts of the invoiced amount over time, and to add insult to injury, the banking interface won’t tell us which invoice the customer is paying for, so we’ll just decide that each payment goes towards the oldest outstanding invoice.
Our task is to calculate how many days have elapsed, for each invoice, from invoice date to payment in full.
Let’s add a running total
A running total of the Amount column will return the customer’s outstanding balance for each transaction, so that feels like a good way forward:
SELECT *,
SUM(Amount) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS RunningTotal
FROM dbo.InvoiceTransactions;
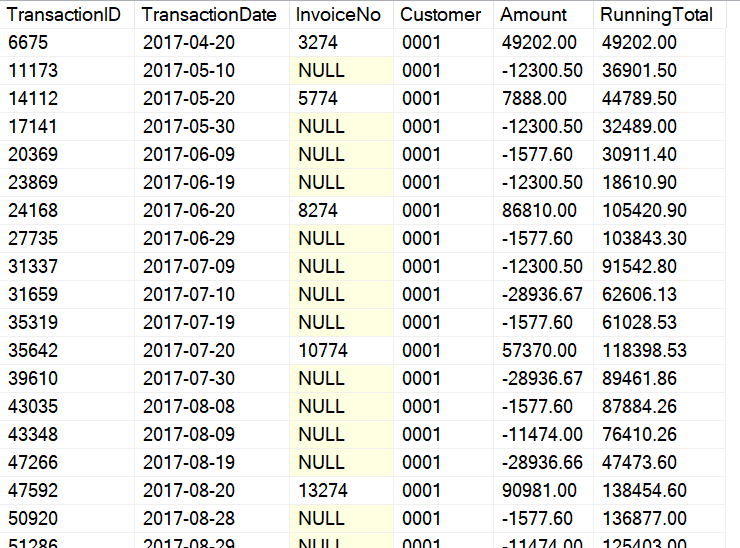
And here, we see the problem right away: invoice 3274 is actually paid in full by 2017-07-09. But by the time the customer has made those payments, we’ve already issued new invoices, so the balance for the customer isn’t zero.
Maybe we can split the running total into invoices and payments:
SELECT *,
SUM((CASE WHEN Amount>0 THEN Amount ELSE 0.0 END)) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS NetInvoicedAmount,
SUM((CASE WHEN Amount<0 THEN Amount ELSE 0.0 END)) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS NetPaidAmount
FROM dbo.InvoiceTransactions;
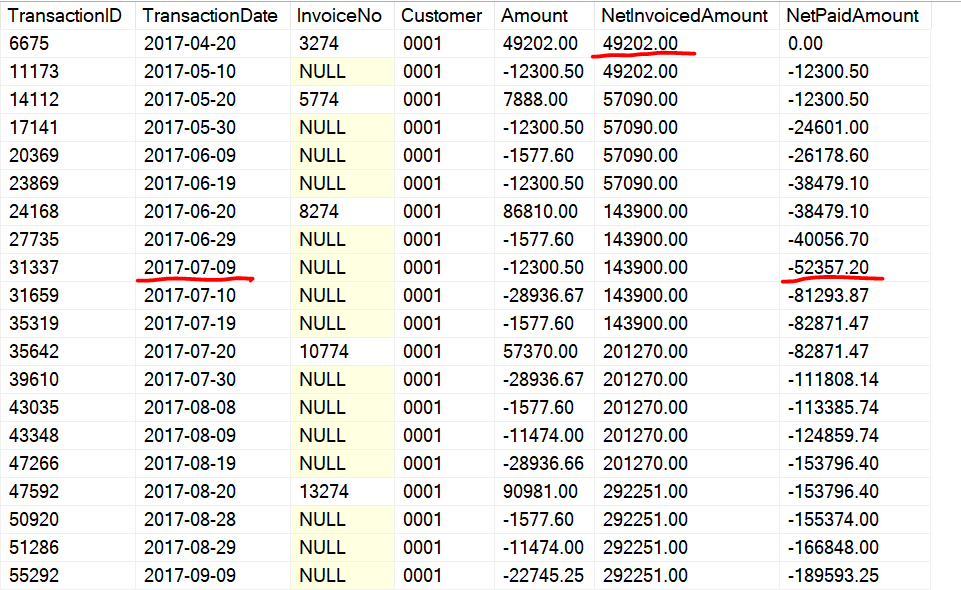
Now we’ve split the running total into one invoice column (always incremented) and one payment column (always subtracted from). To find the point where the client has made enough payments to cover an invoice, we can just keep moving down along the transactions until we find the first running payment total equal to or greater than the invoice running total (at the point in time when the invoice was issued).
So how can we match these in T-SQL?
Split invoices and payments
Let’s try putting invoices and payments in separate common table expressions, and then join those together:
WITH inv AS (
SELECT InvoiceNo, TransactionDate, Customer,
SUM(Amount) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS NetInvoicedAmount
FROM dbo.InvoiceTransactions
WHERE Amount>0),
pay AS (
SELECT TransactionID, TransactionDate, Customer, -Amount AS Amount,
-SUM(Amount) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS NetPaidAmount
FROM dbo.InvoiceTransactions
WHERE Amount<0)
SELECT inv.InvoiceNo,
inv.TransactionDate AS InvoiceDate,
MIN(pay.TransactionDate) AS PaymentDate,
DATEDIFF(day, inv.TransactionDate, MIN(pay.TransactionDate)) AS DaysToPayment
FROM inv
INNER JOIN pay ON inv.Customer=pay.Customer
WHERE inv.NetInvoicedAmount<=pay.NetPaidAmount
GROUP BY inv.InvoiceNo,
inv.TransactionDate;
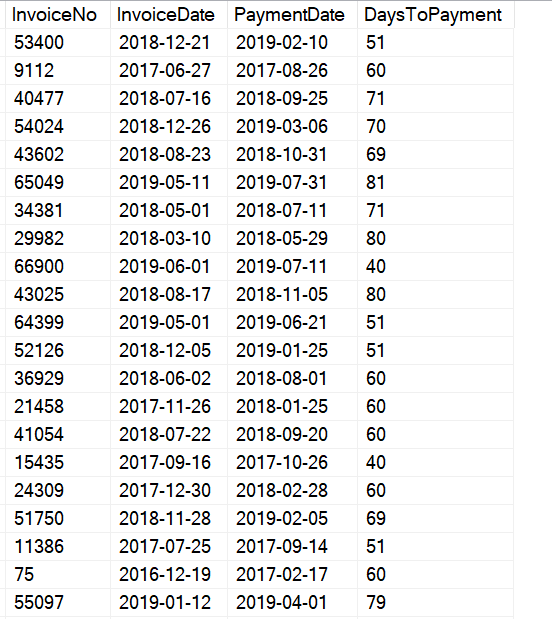
Here’s what’s happening:
- Scan dbo.InvoiceTransactions twice; once for invoices (“inv”, where Amount>0), once for payments (“pay”, where Amount<0).
- Join the two streams together by just the Customer column – this unfortunately creates a cartesian product, where each invoice gets joined to each payment (for the same client, of course).
- Then filter that result, keeping only payments where the NetPaidAmount is greater than or equal to the NetInvoicedAmount.
- Aggregate the result, and keep just the first of those payments, i.e. MIN(TransactionDate).
And the result looks something like this:
The performance stuff.
Before we start tweaking the performance stuff, let’s consider what this query actually does and how we could help it along with an index or two.
- Two scans, one where Amount>0 and on where Amount<0.
- In both of those scans, we want to build a running total
- partitioned by Customer, …
- … ordered by TransactionDate…
- … and TransactionID as a tie-breaker.
- We’ll want to include the Amount column for both scans, and for the invoice scan, we’ll also need the InvoiceNo column.
Here are two filtered indexes that will cover all of these requirements:
CREATE UNIQUE INDEX IX_Paid
ON dbo.InvoiceTransactions (Customer, TransactionDate, TransactionID)
INCLUDE (Amount)
WHERE (Amount<0);
CREATE UNIQUE INDEX IX_Invoiced
ON dbo.InvoiceTransactions (Customer, TransactionDate, TransactionID)
INCLUDE (Amount, InvoiceNo)
WHERE (Amount>0);
Now, let’s look at how the query performs. Here’s the plan:

- Going right-to-left, SQL Server scans our purpose-built non-clustered indexes (one for the payments, one for the invoices).
- Then, the (Segment, Sequence Project) pair computes a row number (per Customer), which is used internally.
- After that, another (Segment, Window Spool, Stream Aggregate) sequence computes the respective running total per Customer over time.
- Then, SQL Server joins those two data streams, using a many-to-many Merge Join. This is made possible because streams are ordered by Customer as a consequence of our non-clustered indexes.
- The join generates a cartesian product, which you can clearly see from the fat arrow and the red size indication.
- Finally, to keep just the first payment row for each invoice, a Hash Match aggregate compresses everything down again.
This query ran in a single thread, for 8.1 seconds with a 7.4 MB memory grant. But can we make it go faster?
Lose an aggregation
We could eliminate the need for the aggregation if we could find a way to match only a single payment to each invoice.
Because the payment’s running total always goes in the same direction, we can definitively say that once we’ve found one row where the payment running total is greater than or equal to the invoice running total, we can stop looking. We can identify when that row happens by looking at how much it has changed from the previous total.
In other words, if it is greater than or equal to the invoice running total now, but the previous rows wasn’t, this is the exact row that we’re looking for.
Or, in T-SQL,
WITH inv AS (
SELECT InvoiceNo, TransactionDate, Customer,
SUM(Amount) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS NetInvoicedAmount
FROM dbo.InvoiceTransactions
WHERE Amount>0),
pay AS (
SELECT TransactionID, TransactionDate, Customer, -Amount AS Amount,
-SUM(Amount) OVER (
PARTITION BY Customer
ORDER BY TransactionDate, TransactionID
ROWS UNBOUNDED PRECEDING) AS NetPaidAmount
FROM dbo.InvoiceTransactions
WHERE Amount<0)
SELECT inv.InvoiceNo,
inv.TransactionDate AS InvoiceDate,
pay.TransactionDate AS PaymentDate,
DATEDIFF(day, inv.TransactionDate, pay.TransactionDate) AS DaysToPayment
FROM inv
INNER JOIN pay ON inv.Customer=pay.Customer
WHERE inv.NetInvoicedAmount<=pay.NetPaidAmount AND
inv.NetInvoicedAmount>pay.NetPaidAmount-pay.Amount;
In the final WHERE clause, we’re no longer just checking that NetInvoicedAmount<=NetPaidAmount, but we’re now also checking that NetInvoicedAmount>NetPaidAmount-Amount (i.e. what NetPaidAmount was in the previous row).
So because we’ve added this check, we no longer need the GROUP BY clause, and we don’t need to MIN() the date column in the SELECT. Here’s the result:

And now, the query finishes in just 6.2 seconds, with no memory grant, because we’re using a Merge Join!
This means that the first row is returned to the client instantly, and that the query will scale more or less linearly* if you throw more data at it.
Other applications
Look familiar? That’s right, this stuff is not just good for keeping track of invoice payments. Instead of invoices, think of warehouse transactions – keeping track of how many days elapse from when you get milk delivery to your store to when a customer buys it. Do you run out of milk on sunday afternoons, or could you perhaps order resupplies a little later and free up space in the fridge?
The same thing goes for shipping containers in a logistics chain, or cars in a dealership.
* Merge Join does allocate a small memory grant in many-to-many joins, so to be fair it will use a little memory and may not scale perfectly linearly.
Question :
After creating “inv” and “pay” sub list using the “with” structure
and then we make join beetwen the two set and here at this second step
the order of the two list retains the original order that is : Customer, TransactionDate, TransactionID
So what is the cause of the the set ordering remains the same
when making “match” beetwen the two set on the basis of only using “Customer” column.
As we know : SQL does not make sure the order when we don’t use “order by” clause.
Or it is only SQL Server version speciality.
Correct, the order is by definition not guarateed. But for the window functions to work, SQL Server will order each stream accordingly (and in our case, it’s already in the right order because of the index).
You’ll probably see different ordering in the output if you run into paralellism, for instance.