For windowed functions, SQL Server introduces two new operators in the execution plan; Segment and Sequence Project. If you’ve tried looking them up in the documentation, you’ll know that it’s not exactly perfectly obvious how they work. Here’s my stab at clarifying what they actually do.
In fact, if you look up these two operators, the single-paragraph documentation for both of them are near-identical: “[…] divides the input set into segments based on the value of one or more columns. […] The operator then outputs one segment at a time.” The reason may have something to do with the duality – these two operators often appear in the same plans, right next to each other.
Segment
![]() The Segment operator takes a previously ordered result set and identifies the rows that constitute a change in a grouping column. Suppose you have a table (or stream, actually) of financial transactions with three relevant columns (date, time, amount). The stream is ordered by date and time, so when you iterate through it, you get all the transactions in chronological order. The Segment operator can be used to identify when the date column changes from one row to the next, for instance if you want to find the first or last transaction for each date.
The Segment operator takes a previously ordered result set and identifies the rows that constitute a change in a grouping column. Suppose you have a table (or stream, actually) of financial transactions with three relevant columns (date, time, amount). The stream is ordered by date and time, so when you iterate through it, you get all the transactions in chronological order. The Segment operator can be used to identify when the date column changes from one row to the next, for instance if you want to find the first or last transaction for each date.
Let’s try an example. To start off, we’ll need some data to play with:
CREATE TABLE #transactions (
rowId int IDENTITY(1, 1) NOT NULL,
transDate date NOT NULL,
transTime time NOT NULL,
value numeric(10, 2) NOT NULL,
value2 numeric(10, 2) NOT NULL,
PRIMARY KEY CLUSTERED (transDate, rowId)
);
--- Add some random transaction data, about 130 000 rows total:
INSERT INTO #transactions (transDate, transTime, value, value2)
VALUES ({d '2014-01-01'}, {t '09:00:00'}, RAND()*10000, RAND()*10000);
WHILE (@@ROWCOUNT<50000)
INSERT INTO #transactions (transDate, transTime, value, value2)
SELECT DATEADD(dd, 1, x.maxTransDate),
DATEADD(ms, 500*ROW_NUMBER() OVER (ORDER BY (SELECT NULL)), {t '09:00:00'}),
RAND(w.rowId)*10000, RAND(0-w.rowId)*10000
FROM #transactions AS w
CROSS APPLY (SELECT MAX(transDate) AS maxTransDate FROM #transactions) AS x;
We now have 18 days worth of data to play with in the table. We can identify the dates as well as each day’s closing transaction IDs (the last rowId) with the following simple query:
SELECT transDate, MAX(rowId) AS maxRowId FROM #transactions GROUP BY transDate;
The clustered index on the table is suitably sorted, so we get a very simple query plan based on a stream aggregate operator:

But what are the amounts for those closing transactions? This should be a simple matter of putting the above aggregate in a subquery or common table expression, and then joining this with the original table again. Something like:
--- The maximum rowId for each date in a CTE... WITH x AS ( SELECT transDate, MAX(rowId) AS maxRowId FROM #transactions GROUP BY transDate) --- ... and join the CTE to the transaction table: SELECT w.* FROM #transactions AS work INNER JOIN x ON work.transDate=x.transDate AND work.rowId=x.maxRowId;
Now try to imagine what the query plan ought to look like with this new query; we have the aggregate that should look just like the plan above. Then, for each row of that aggregate, we’ll need to find the matching row in the transaction table, perhaps using a nested loop join. Here’s how I thought it would look:
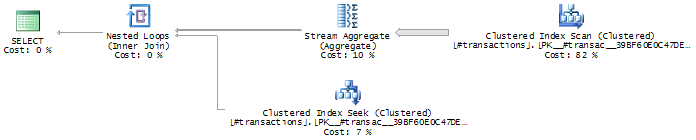
Not so. Here’s what actually happens:

The query optimizer (very cleverly indeed) recognizes what we’re trying to do and converts the query by adding a Segment operator (to detect when the date column changes, remember?) and a TOP 1 WITH TIES to filter out single rows, the ones just before the date changes. The resulting plan, incidentally, is also non-blocking, which is great for performance.
Sequence Project
![]()
If you see the Segment operator, chances are pretty good that you may have been using a windowed function, like ROW_NUMBER(), RANK() or DENSE_RANK(). You’ll notice that Sequence Project’s best friend is Segment, and wherever Sequence Project appears, it’ll usually be accompanied (preceded) by Segment. Using the example data we created above, let’s jump straight into an example query:
SELECT rowId, transDate, transTime,
ROW_NUMBER() OVER (PARTITION BY transDate ORDER BY rowId)
FROM #transactions;
The ROW_NUMBER() function creates an ordered counter that resets to 1 for every new transDate. As you know by now, the Segment operator “partitions” the data stream (i.e. the contents from the table), which makes it perfect for this type of operation – it tells the rest of the query plan when to reset the count. The actual counting is done by the Sequence Project operator. Consider the following plan:

From right-to-left, the clustered index scan returns all rows from the table (they’re already ordered correctly for our purposes because of the table’s clustered index definition). For each row in the stream, the Segment operator checks if it belongs to the same group as the previous row (i.e. if it has the same transDate). Using this information, the Sequence Project operator then either adds 1 to the row count column (if the group is still the same) or resets the counter to 1 (if we’ve entered a new group).
Interestingly, if your query does not contain a PARTITION BY expression, you wouldn’t need a Segment, right?
SELECT rowId, transDate, transTime,
ROW_NUMBER() OVER (ORDER BY transDate, rowId)
FROM #transactions;
Wrong. For reasons apparently known only to the software engineers on the Microsoft SQL Server development team, the Segment operator is still there, although it doesn’t do anything except passing rows in the stream. But don’t worry about it – doing nothing is really cheap and won’t ruin your query performance. 🙂
Window Spool
![]()
The Window Spool operator is used when you use ordered windowed functions, like LAST_VALUE(), LEAD(), LAG(), etc. What it essentially does is to expand the stream (the “frame”) in order to solve the task at hand. Consider the following example query:
SELECT transDate, transTime, LAG(transTime, 3) OVER (PARTITION BY transDate ORDER BY rowId) FROM #transactions;
The LAG() function, in this example, returns the third preceding transTime value for the current transDate, ordered by rowId. The query plan looks like this:


Going through the plan, right-to-left, here’s what’s going on: The clustered index scan returns all of the rows in the table, properly ordered. Segment identifies the rows that “start” a new transDate, which its cousin Sequence Project then uses to create a row number for the stream. The scalar computation actually just subtracts 3 from the row number.
The next Segment operator just re-does what the first Segment did (grouping by transDate), probably because that information wasn’t passed on once the Sequence Project was done. The segment column is then used by the Window Spool operator to expand the stream. So here’s the stream before the Window Spool (excluding the scalar computation):
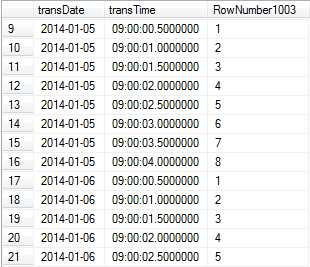
The Window Spool effectively doubles the size of the stream (which you can also see by hovering over the arrow in the graphical query plan), because we’ve unioned the stream with itself. The pseudo-code of this join looks something like:
SELECT transDate, transTime, RowNumber1003, NULL AS Expr1002 FROM stream UNION ALL SELECT transDate, NULL AS transTime, RowNumber1003+3, transTime AS Expr1002 FROM stream ORDER BY transDate, RowNumber1003;
So with each row, we’re also union’ing the corresponding record three rows back in the stream. This looks something like this:
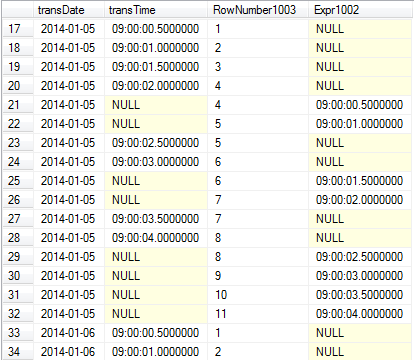
Rows with NULL values in Expr1002 are the “original” rows, while rows with NULL values in transTime the “lagging” rows.
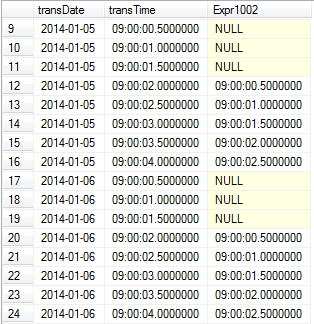
Now, because we’ve doubled the number of output rows, we need to aggregate them by transDate and RowNumber1003 so we get back the original number of rows. transTime and Expr1002 are the columns being aggregated. Here’s the pseudo-code for the Stream Aggregate, to finish off the query plan:
SELECT transDate,
ANY(transTime) AS transTime,
ANY(Expr1002) AS Expr1002
FROM stream
GROUP BY transDate, RowNumber1003
HAVING COUNT(transTime)>0;
.. and the final output looks like this:
Windowed aggregates
The use of Segment and Sequence Project is basically the same when used for windowed aggregates (SUM(something) OVER (PARTITION BY something)), but the query plan is a bit more complex, so I’ll save that topic for another post.
Credits
Most of this post is (again) based on some excellent work by Paul White (on Segment, Sequence Project). I got some help from my friendly peers on Stack Exchange with the partition-less Segment operator as well. Another great source of inspiration is Itzik Ben-Gan’s excellent book on window functions.