![]() The spool operator is one of those icons that will show up in a query plan now and then. In this post, we’ll take a closer look at what it does in a query plan, how it affects performance, and what you can do to substitute or eliminate it.
The spool operator is one of those icons that will show up in a query plan now and then. In this post, we’ll take a closer look at what it does in a query plan, how it affects performance, and what you can do to substitute or eliminate it.
What it does
The spool operator creates a temporary data storage in tempdb that exists only for the duration of the current statement. This storage is populated with a subset of data that the server needs to access more than once. The idea is to make the query more efficient by “caching” the data. There are two ways this can happen, eager or lazy. The eager spool, like the name implies, loads everything into the temporary data storage at once, whereas the lazy spool loads data as it’s needed.
There are two common types of spools: table spools and index spools. A table spool is basically a heap, i.e. unsorted data. With a heap comes the benefit that you don’t have to sort the data when you build it, but the downside is that you can’t filter or sort it as effectively. An index spool, in contrast, is a clustered table. So it takes longer to build, but can be more useful when filtering or aggregating rows.
There are a few reasons why the optimizer stores data in a temporary structure like this, but the main two scenarios are 1) when updating data could lead to recursive effects (the so-called Halloween effect) or 2) when you need repeated access to the same data.
The Halloween effect
The Halloween effect really has nothing to do with trick-or-treating, but with a discovery made by some IBM people on halloween in the 70ies. The idea is that when you make an update to any data, you need two logical operators running in parallel: an input (a read cursor, the process that reads the data you want to update from the table) and an output (the write cursor, that actually performs the modification).
Imagine that you need to build an UPDATE query that adds $500 to the salary of everyone who makes less than $27000. The input operator would identify what the original salary is, a scalar calculation adds 500 to it, and the output operator updates the table record.
Here’s a test setup:
CREATE TABLE #salary ( employee int NOT NULL, salary numeric(10, 2) NOT NULL, CONSTRAINT PK_salary PRIMARY KEY CLUSTERED (employee) ); CREATE INDEX salaryIndex ON #salary (salary); INSERT INTO #salary (employee, salary) VALUES (1001, 25000), (1002, 26000), (1003, 27000), (1004, 28000);
And here’s the update query, in two different versions, the first one using the clustered primary key and the second one using the index on the salary column:
--- Using clustered primary key: UPDATE #salary SET salary=salary+500 FROM #salary WITH (INDEX=PK_salary) WHERE salary<27000; --- Using index on salary column: UPDATE #salary SET salary=salary+500 FROM #salary WITH (INDEX=salaryIndex) WHERE salary<27000;
In the first case, SQL Server uses the primary key to read the data, then writes the changes to the table and the salary index. Because the clustered index is sorted on empoyee and the salary index is sorted on salary, changing data in the salary column can cause the updated rows to move about in the salary index, but not in the clustered index. Here’s the query plan for the first update:

In the second case, we’re using an index hint to force the reader to use the salary index as its input. But updating the salary could cause the updated row to move in the index. With any bit of bad luck, this sort operation could cause some of the updated rows to move forward in the index as a result of the update – and end up ahead of the read cursor, causing them to be included more than once by the reader. If that happened, the query could potentially keep looping until everybody had a salary of at least $27000. Which would be decent. But incorrect.
To prevent this, all the rows that we want to update in the salary index are first copied to a temporary structure, using a table spool. That way we can then loop through this temporary structure to find out which employees make less than $27000, so that each row is only counted once. Here’s the query plan:
![]()
It’s worth mentioning that the spool operator isn’t the only way to handle “halloween protection” – there are other operators that will provide this as well, although this is outside the scope of this article.
Inserting data from the same table
Another variant of the Halloween effect is when you perform an INSERT into a table using data selected from the same table.
CREATE TABLE #records ( i int NOT NULL, CONSTRAINT PK_records PRIMARY KEY CLUSTERED (i) ); INSERT INTO #records (i) VALUES (1), (2), (3), (4); --- Read rows from #records and re-insert them into the --- same table again: INSERT INTO #records (i) SELECT i+10 FROM #records;
In this case, the reader performs a scan of the #records table and the writer populates the table. It reads 1, inserts 101, reads 2, etc. By the time the reader has passed row 4, it’ll just keep reading row 101, inserting 201, reading 102, etc. Using a spool operator, the server avoids an infinite recursion.
In this case, a lazy spool would work pretty much like no spool at all, so this query is going to need an eager spool.
Recursion
Recursive queries are another great example of a query that would be a lot trickier without spooling. The lazy spool is, in fact, ideal for recursive common table expressions.
Here’s an example of a query that splits a string into words.
--- A string of words, separated by comma, to split: DECLARE @txt varchar(max)='One, two, three, four, five, six'; WITH rcte (word, remain) AS ( --- The anchor part SELECT CAST(NULL AS varchar(10)), @txt UNION ALL --- The recursive part of the common table expression: --- Cut out the first word of the "remain" column and --- truncate the "remain" column by the same length. --- This repeats until remain=''. SELECT CAST(RTRIM(LEFT(remain, CHARINDEX(',', remain+',')-1)) AS varchar(10)), CAST(SUBSTRING(remain, CHARINDEX(',', remain+',')+1, LEN(remain)) AS varchar(max)) FROM rcte WHERE remain!='') SELECT word FROM rcte WHERE word IS NOT NULL;
Long story short, the query loads the anchor row into a spool, then repeatedly reads and updates the spool table until completion. Here’s the query plan, where you can identify both those spool operators:
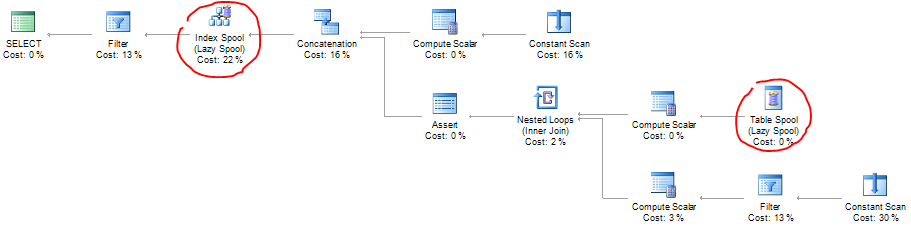
The reason the spool is lazy in this case is because the query processor cannot determine all the rows it’s going to generate from the start – so “we’ll cross that bridge when we get to it.”
As for the Assert-operator, it’s just checking that we don’t exceed the maximum number of recursions.
Other uses
Windowed functions often also depend heavily on the spool operator. You will probably come across other, less obvious cases such as some occurrences of LOOP JOINs, TOP operators, etc.
Performance
If you analyze the I/O usage for the two example queries in the Halloween effect section, you’ll find that the one with the spool operator comes with an extra cost. After all, the server has to save a dataset to a temporary table (the spool) and then join this spool back to the original query. However, we’ve intentionally forced this situation using a “bad” index hint.
Generally, the spool operator is there to boost the performance of a query. So if you see one, it’s there to help. You might, however, be able to eliminate it and improve performance even further by trying to eliminate some of the obvious root causes.
- Don’t assume spools are bad. But they can sometimes point to bad things.
- Can you add or use a different index in an update, so the reader doesn’t work with an index that is being updated?
- Can you eliminate or re-write windowed functions?
- Can you add or use a different index in order to enable the use of a better type of JOIN?
- Can you re-write recursive common table expressions?
Credits
I found quite a bit of inspiration for this article in Rob Farley’s excellent deep-dive on spooling.
More on the Halloween effect and blocking operators on Craig Freedman’s blog.
VERY NICE ARTICLE