Stay with me. This is not clickbait!
I made you a script so you can create your own SQL Server database using the public IMDB dataset. All you need is a SQL Server 2022, Powershell 7, and a little time.
If you didn’t know, the IMDB dataset is public, and you can download it for free. There are some license restrictions, but as long as you use the data for your own, non-commercial purpose, you’ll be fine. I’ve always claimed that the years 1994 thru 2003 were a true modern golden age of Hollywood movies, and I wanted to find out if I could prove it.
It has to be acknowledged, though, that the IMDB movie ratings are pretty far from perfect. Look, I’m not saying that reviewers have poor taste, but please consider the fact that “Avengers: Infinity War” and “Spider-Man: Into the Spider-Verse” both have an impressive average rating of 8.4, while the epic crime noir masterpiece that is “Heat” comes in at a meager 8.3, and the genre-defining cyberpunk classic “Bladerunner” gets just a 8.1 average.
I’m sure Spider-Man is a fine movie, but come on. Anyway, I digress.
How to create your own IMDB database in SQL Server
You’ll need a couple of scripts that I’ve put in a Github repository, a SQL Server 2022, and about 20 GB of free disk space to do this.
- Create a new SQL Server database.
- Create the database schema by running the Create IMDB-schema.sql script in the database.
- Download and import the IMDB dataset using the Load-ImdbStaging.ps1 script. The script will download the data files to your current working directory and perform the ingest from there. The download is just a few GB, but inserting the data may take a few hours depending on your hardware.
- Populate the relational tables using the Load IMDB relational tables.sql script.
- Once this is done, you can drop the staging tables in the Raw schema if you want.
The proof
I’ve chosen the following highly scientific method to determine the best consecutive ten years of moviemaking, not because I know anything about statistical analysis, but because it kind of confirms my bias what already I knew to be true.
--- Movies
--- * with at least 50,000 votes
--- * at least 1 hours long
WITH movies AS (
SELECT YEAR(t.startYear) AS startYear, t.averageRating, t.voteCount,
ROW_NUMBER() OVER (
PARTITION BY t.startYear
ORDER BY t.averageRating DESC, t.voteCount DESC
) AS ranking,
tn.title
FROM dbo.Titles AS t
INNER JOIN dbo.TitleTypes AS tt ON t.titleTypeId=tt.titleTypeId
LEFT JOIN dbo.TitleNames AS tn ON t.titleId=tn.titleId AND tn.isOriginal=1
WHERE t.voteCount>=50000
AND tt.titleType='movie'
AND t.runtime>='01:00:00'),
--- Limit to the top-10 each year to filter out the low-quality stuff
--- you would never have watched anyway
top10 AS (
SELECT *
FROM movies
WHERE ranking<=10),
--- Create a rolling aggregate of 10 years. The average is weighted using
--- the vote count, so a movie with a 9.0 and 50,000 votes does not impact
--- the average as much as a movie with a 7.0 with a million votes.
yearAggregate AS (
SELECT startYear,
--- Rolling 10-year vote count
SUM(SUM(voteCount)) OVER (ORDER BY startYear ROWS BETWEEN CURRENT ROW AND 9 FOLLOWING) AS voteCount_10yrs,
--- Rolling 10-year average rating
SUM(SUM(averageRating*voteCount)) OVER (ORDER BY startYear ROWS BETWEEN CURRENT ROW AND 9 FOLLOWING)
/SUM(SUM(voteCount)) OVER (ORDER BY startYear ROWS BETWEEN CURRENT ROW AND 9 FOLLOWING) AS averageRating_10yrs,
--- Collect the top 1 movie for the starting year
MIN((CASE WHEN ranking=1 THEN title END)) AS top1_title
FROM top10
GROUP BY startYear)
--- Finally, DENSE_RANK() the results to see which year(s) come out on top.
SELECT startYear,
startYear+9 AS endYear,
top1_title,
voteCount_10yrs,
averageRating_10yrs,
DENSE_RANK() OVER (ORDER BY averageRating_10yrs DESC) AS [rank]
FROM yearAggregate AS y
ORDER BY startYear;
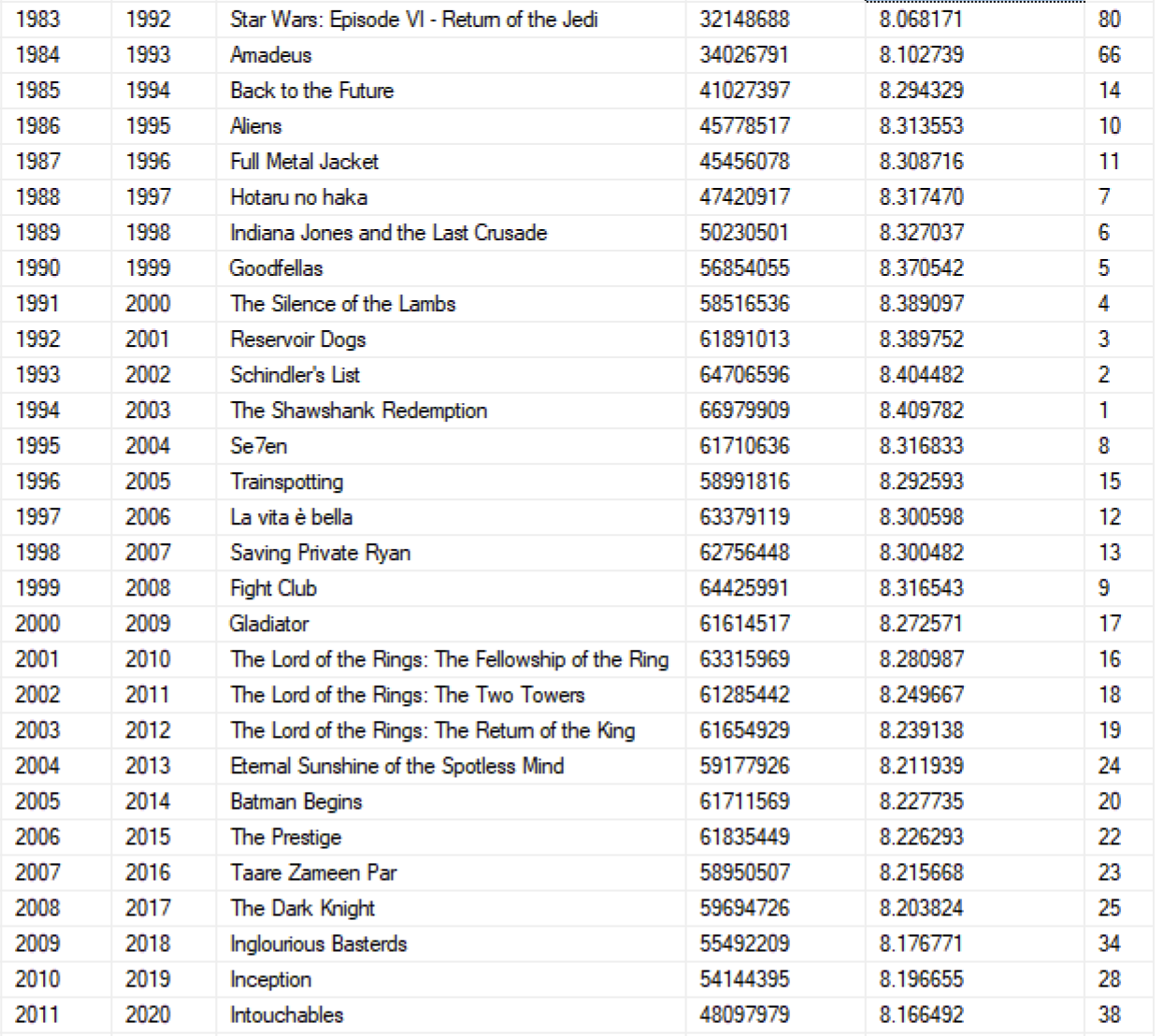
If you’ve made it this far, I’m sure you have opinions. Let me hear them in the comments.