We’re no strangers to doing things in T-SQL that would perhaps be more efficient in a procedural language. Love it or hate it, a T-SQL solution is easier in some situations, like my sp_ctrl3 procedure that I use as a drop-in replacement for the standard sp_help procedure to display object information in a way that simplifies copying and pasting.
One of the things that sp_ctrl3 does is plaintext database search. If you pass a string to the procedure that does not match an existing object, it’ll just perform a plaintext search of all SQL modules (procedure, views, triggers, etc) for that string. The search result includes line numbers for each result, so it needs to split each module into lines.
I’ve found that this takes a very long time to run in a database with large stored procedures, so here’s how I tuned it to run faster.
If you want to follow along, try the example code in a database that has Brent Ozar’s First Responder Kit installed, or just substitute the name of the stored procedure in the code for one of yours.
The simple solution
You know the rules – keep it simple, stupid. Ideally, we’ll just need a STRING_SPLIT() – split the module into lines, and filter them. Right?
DECLARE @searchString nvarchar(128)=N'%test%';
--- Get the source code
DECLARE @source nvarchar(max)=(
SELECT REPLACE([definition], NCHAR(13)+NCHAR(10), NCHAR(13))
FROM sys.sql_modules
WHERE [object_id]=OBJECT_ID('dbo.sp_Blitz'));
--- 100-110 ms
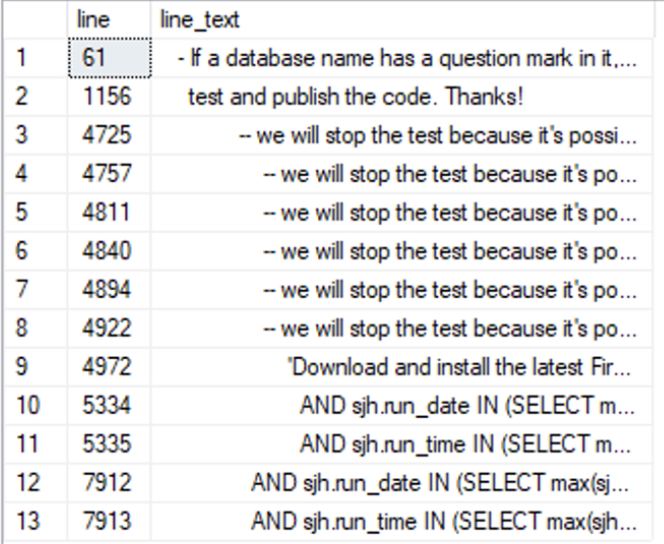
SELECT *
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS line, [value] AS line_text
FROM STRING_SPLIT(@source, NCHAR(13))
) AS lines
WHERE line_text LIKE @searchString;
The simplified code example collects the source code for dbo.sp_Blitz into an nvarchar(max) variable, splits that code into lines, then filters those lines to just show the ones that contain the search pattern “test”.
It’s pretty fast – 110 ms on my machine – and the code is really compact and easy to read. There are however a couple of problems with this:
- The STRING_SPLIT() function is only available on SQL Server 2016 and later. But some of my users are still running SQL Server 2014 in their setup, and occasionally, so do I.
- The output order of STRING_SPLIT() is not guaranteed, so counting the row numbers like we do isn’t guaranteed to be correct. The ROW_NUMBER() trick, where we order by (SELECT NULL) is a well-used trick to circumvent the fact that you’re not allowed to order by constants – this creates a row counter that just follows the order in which the rows are returned.
A full commitment
To fix the issues with the STRING_SPLIT() solution, I’m thinking of a recursive common table expression. Though it does make the code harder to read, and as you’ll see, and it brings a noticeable performance impact.
WITH rcte AS (
SELECT 0 AS line, CAST(NULL AS nvarchar(max)) AS line_text, @source AS remain
UNION ALL
SELECT line+1 AS line,
LEFT(remain, PATINDEX(N'%['+NCHAR(10)+NCHAR(13)+N']%', remain+NCHAR(10))-1) AS line_text,
SUBSTRING(remain, PATINDEX(N'%['+NCHAR(10)+NCHAR(13)+N']%', remain+NCHAR(10))+1, LEN(remain)) AS remain
FROM rcte
WHERE remain LIKE @searchString)
SELECT line, line_text
FROM rcte
WHERE line_text LIKE @searchString
OPTION (MAXRECURSION 0);
The recursive common table expression traverses @source from left to right, one line break character at a time, so it will return one output row for each line.
The important part happens in two of the CTE’s columns: “line_text” and “remain”. The “line_text” is the current line and “remain” is the remaining part of @source at any given point. The “anchor” will have the entire @source is in the “remain” column and the “line_text” is NULL.
Recursion
For each recursion, we’ll use PATINDEX() to find the next line break in the “remain” column (line breaks can be an NCHAR(10) or an NCHAR(13) depending on the module author’s platform and settings). In case there’s no more line break in “remain”, we’ll add an NCHAR(10) to the end, just to make sure we get every last line.
Anything to the left of that line break goes into “line_text”, anything to the right goes back into the “remain” column for the next iteration.
The OPTION (MAXRECURSION) hint is there to allow the recursion to continue past the default 100-iteration limit without throwing an error, in order to handle modules that contain more than 100 lines. 0 allows for an infinite number of iterations, but you could set it to any value up to 30,000 if you really want.
Like a turtle in a headwind
The problem with this recursive CTE is that it’s mind-numbingly slow, because it iterates over every single line in @source. And for every iteration, it needs to perform a number of scalar operations, including a wildcard lookup and putting the resulting row in a Lazy Spool.
This query runs for a whopping 80 seconds on my system.
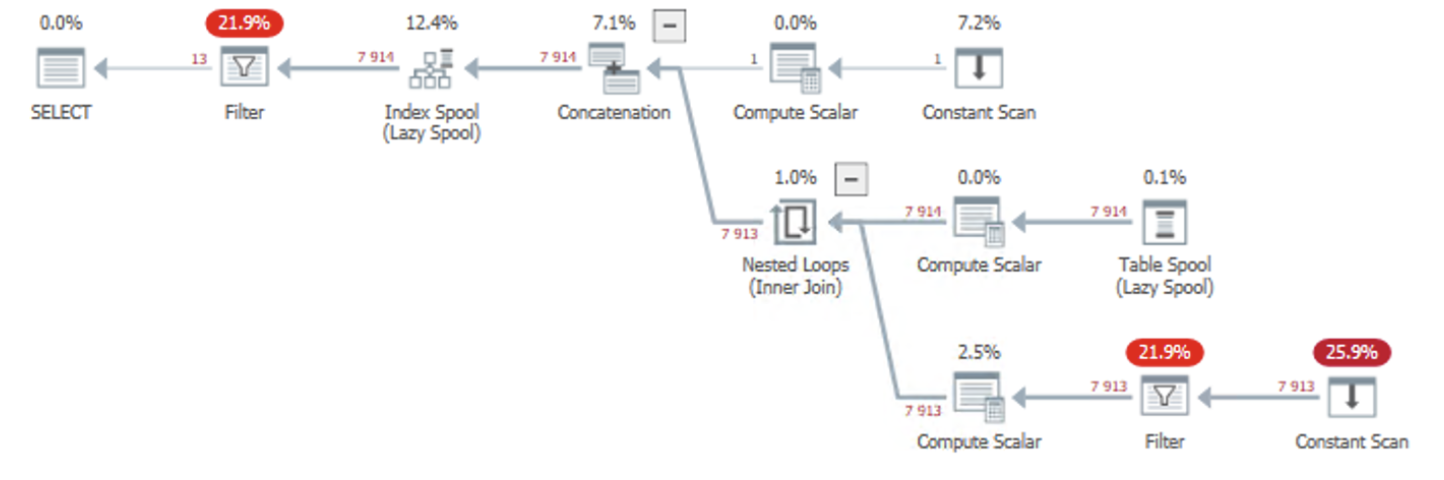
The top-right Constant Scan is our anchor, @source. This feeds into a (lazy) Index Spool, which makes that same row available to the next iteration (the Table Spool operator to the right). You could actually think of the Lazy Spool operator as a wormhole that transports rows from one place to another for re-use.
Then, it increments the line number counter. The Filter operator tests if we should continue with the recursion (this corresponds to the WHERE condition of the recursion), and finally another Compute Scalar computes the LEFT() and SUBSTRING() stuff.
In the end, the new row feeds into the Index Spool, and the cycle starts over, until there’s nothing left in “remain”.
The most costly operations are related to Filter operators. The lower-right corner checks if there’s any remaining search result in the “remain” column, and the Filter operator at the top-left filters the returned rows for the search condition. This happens because we’re splitting all of the lines (up to the last search match), before filtering the lines that actually match our search condition.
This is where we can optimize the solution.
The faster CTE solution
We can reduce the number of iterations, and with that, the number of scalar function calls, if we recurse on search matches instead of line breaks. So instead of:
- split into lines,
- increment line number,
- filter lines on search condition
… we could:
- split into search matches,
- compute the line number
Bear with me:
WITH rcte AS (
SELECT 1 AS line, CAST(NULL AS nvarchar(max)) AS line_text, @source AS remain
UNION ALL
SELECT CAST(rcte.line+x3.line_count AS int) AS line,
CAST(RIGHT(x2.left_of_keyword, x3.offset_to_prev_line-1)+
SUBSTRING(rcte.remain, x1.keyword_offset, x2.offset_to_next_line) AS nvarchar(max)) AS line_text,
CAST(SUBSTRING(rcte.remain, x1.keyword_offset+x2.offset_to_next_line, LEN(rcte.remain)) AS nvarchar(max)) AS remain
FROM rcte
CROSS APPLY (
VALUES (
PATINDEX(N'%'+@searchString+N'%', rcte.remain)
)) AS x1(keyword_offset)
CROSS APPLY (
VALUES (
LEFT(rcte.remain, x1.keyword_offset-1),
PATINDEX(N'%['+NCHAR(10)+NCHAR(13)+N']%', SUBSTRING(rcte.remain, x1.keyword_offset, LEN(rcte.remain))+NCHAR(10))-1
)) AS x2(left_of_keyword, offset_to_next_line)
CROSS APPLY (
VALUES (
PATINDEX(N'%['+NCHAR(10)+NCHAR(13)+N']%', REVERSE(x2.left_of_keyword)+NCHAR(10)),
LEN(x2.left_of_keyword)-LEN(REPLACE(REPLACE(x2.left_of_keyword, NCHAR(10), N''), NCHAR(13), N''))
)) AS x3(offset_to_prev_line, line_count)
WHERE x1.keyword_offset>0
)
SELECT line, line_text
FROM rcte
WHERE line_text IS NOT NULL
OPTION (MAXRECURSION 0);
I know, there’s a lot going on here. Let’s review it step by step:
The anchor is still @source, and we’re still using “line_text” and “remain” as our working columns.
I’m using CROSS APPLY to allow me to perform calculations that I can re-use later in the query without having to package everything in an abyss of subqueries.
- x1.keyword_offset is the offset (number of characters into “remain”) where the search keyword appears next. 0 means it wasn’t found, 1 means that “remain” starts with the search keyword, etc.
- We’ll filter the recursive part in the WHERE clause in order to only keep iterating for as long as x1.keyword_offset is greater than 0.
- x2.left_of_keyword is all of the text to the left of our match. We’ll need this in a second.
- x2.offset_to_next_line is how many characters remain from the start of the search match until the next line break.
- x3.offset_to_prev_line, is computed by reversing x2.left_of_keyword and finding the nearest preceding line break before the search match.
- With x2.offset_to_next_line and x3.offset_to_prev_line, we can piece together the entire current line. These two go into the “line_text” column.
- x3.line_count tells us how many lines precede the search match in the current iteration (i.e. in “remain”). The simplest way to count the number of line breaks is to calculate the difference in length of “remain”, with and without line break characters, respectively. That’ll be how many line break characters are in the string.
- We’ll add x3.line_count to the previous line count.
- Finally, we’ll truncate the start of “remain” by (x1.keyword_offset + x2.offset_to_next_line) characters to position us at the start of the next line for the next iteration.
The query plan is nearly identical – all of the magic is hidden in the Compute Scalar operators anyway:

But our improved CTE runs in just 350 ms. Not quite as blazingly fast as the STRING_SPLIT(), and certainly not as intuitive to read, but it’s backward compatible for older SQL Server versions, and we don’t have to rely on unsupported quirks of the database engine.
Edit: Paul White’s take
T-SQL performance tuning guru Paul White actually took a stab at this problem after I published my post, and he went with a more procedural approach, which turns out to perform quite impressively:
-- No plans or row count messages
SET STATISTICS XML OFF;
SET NOCOUNT ON;
--- Get the source code
DECLARE @source nvarchar(max)=(
SELECT REPLACE([definition], NCHAR(13)+NCHAR(10), NCHAR(13))
FROM sys.sql_modules
WHERE [object_id]=OBJECT_ID('dbo.sp_Blitz'));
-- Text to find
DECLARE
@find nvarchar(128) = N'test';
-- Working variables
DECLARE
@find_len bigint = LEN(@find),
@line_num bigint = 0,
@line_start bigint = 0,
@line_end bigint = 0,
@match_pos bigint = 0;
-- Lines with matches
DECLARE @MatchLines table (
line bigint PRIMARY KEY,
line_start bigint NOT NULL,
line_length bigint NOT NULL);
-- Find first match position
SET @match_pos = CHARINDEX(@find, @source);
WHILE @match_pos > 0
BEGIN
-- Count lines and find start/end points
WHILE @line_end < @match_pos
BEGIN
SELECT
@line_start = @line_end + 1,
@line_end = CHARINDEX(
NCHAR(13),
@source COLLATE Latin1_General_100_BIN2,
@line_start),
@line_num += 1;
-- No more lines
IF @line_end = 0 SET @line_end = 2147483647;
END;
-- Record information about this match line
INSERT @MatchLines
(line, line_start, line_length)
VALUES
(@line_num, @line_start, @line_end - @line_start);
-- Find next match
SET @match_pos =
CHARINDEX(@find, @source, @match_pos + @find_len);
END;
-- Show matched lines
SELECT
ML.line,
line_text =
SUBSTRING(
@source COLLATE Latin1_General_100_BIN2,
ML.line_start,
ML.line_length)
FROM @MatchLines AS ML
ORDER BY ML.line ASC;
This solution is comparable in execution time to the STRING_SPLIT() solution in the beginning of the post, coming in at 120 ms on my system.
Regarding the first CTE solution, you write: “The most costly operations are related to Filter operators”
No. They are not. Or rather, they are very likely not. You have no reliable information to base this on.
Please tell me you are not taking estimated cost percentages serious in an execution plan where the estimated number of rows is (likely, I have not ran the code but I am even so willing to bet a round of beers) completely wrong.
(I mean, just look at the top right constant scan. Runs once. Scans a constant. And claims 7.2%. Yeah, that’s 7.2% of the estimated cost, not 7.2% of 80 full seconds.
You’re right, I snuck in the phrase “related to” for this purpose. But my wording was sloppy.
To clarify: the cost of the query comes down to the many iterations, each of which needs to
1) perform string logic like WHERE and PATINDEX(), and
2) shuffle the resulting rows in and out of the Spool.
Yes, the query plan estimates are completely off, and the initial constant scan is certainly not even a fraction of 7% of the workload. 🙂
My guess would be that most of the I/O is in the Index Spool / Table Spool combination. The Index Spool stores a row in a worktable; the Table Spool reads the last added row and removes it. (Together they for a stack).
I/O tends to be more expensive than anything else in most execution plans. (Though the PATINDEX in a very long string will indeed also contribute a lot).
I doubt, that the T-SQL code is working as expected.
The variable @line_length was never set.