This is the second part in a series on storing and modelling data efficiently. A great way to add performance to your data is to partition it. Like the name implies, partitioning splits a table or index into multiple partitions, so the data can be stored across multiple physical files and drives. Partitioning is a feature of SQL Server Enterprise Edition, but if you have one, you’re in luck!
Partitioning
Partitioning a table or index splits it into a bunch of separate partitions, which can be stored on one or more different volumes. Optimally, you could store each partition on a separate physical disk, but the performance gain is not all together lost even if you store everything on a single volume. Remember, what you’re doing is chunking up the information for quicker access by SQL Server, and if you filter your query using the partitioning column, SQL Server can do what’s called partition elimination, which means that it can query only a single partition instead of looking through the entire table or index – which is exactly why we want partitioning in the first place.
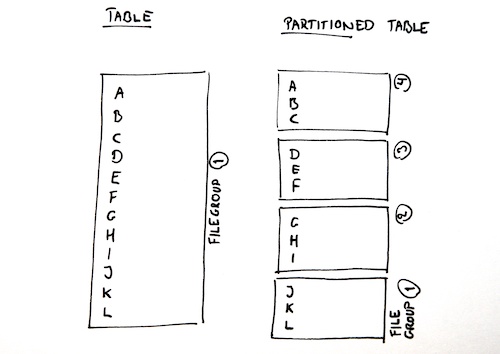
Here are the basic three steps to set up partitioning:
- The partitioning function defines the boundary values (and their data type) for each partition. The boundary value is the “border”, where a partition begins and ends. It also defines if the partition function is left-delimited or right-delimited.
- The partition scheme maps a partition function to a number of file groups.
- Finally, create a table on the partition scheme. Just like a regular table, except instead of placing it “ON [PRIMARY]”, you put it “ON [yourPartitionScheme]”.
That’s it. There’s a fancy-pants wizard in SQL Server Management Studio for this, too. But here’s how it looks in code:
--- Create the partition function: CREATE PARTITION FUNCTION fn_part_left(int) AS RANGE LEFT FOR VALUES (100, 110, 120, 130); --- Create the partition scheme. --- In this example, the ALL keywords means that I'm --- putting all the partitions on the same file group. CREATE PARTITION SCHEME ps_part_left AS PARTITION fn_part_left ALL TO ([PRIMARY]); --- Create a table on the partition scheme, including --- specifying which column of the table is used as --- the partitioning column. --- The partitioning column has to be part of the table's --- clustered index. CREATE TABLE dbo.tbl_part_left ( i int NOT NULL, PRIMARY KEY CLUSTERED (i) ) ON ps_part_left(i); --- Populate the table with some example data: INSERT INTO dbo.tbl_part_left (i) VALUES (98), (99), (100), (101), (102), (103), (104), (105), (106), (107), (108), (109), (110), (111), (112), (130), (131), (132), (133);
There’s so much more to talk about when it comes to partitioning, including the differences between LEFT-delimited and RIGHT-delimited partitions, how to switch data in and out of partitioned tables, and more, but it goes a bit beyond the scope of this post.
Check back next week, when we’ll be taking a closer look at data compression!